 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Object Interaction Detection Collaborated with Large Relation-driven Diffusion Models
Paper and Code
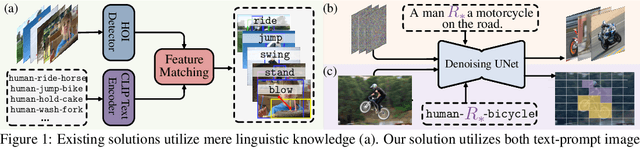
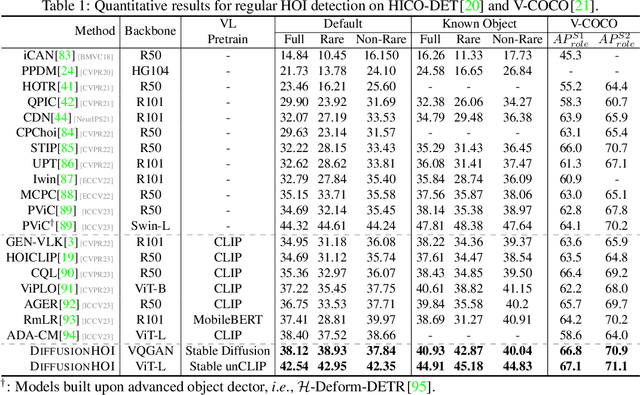
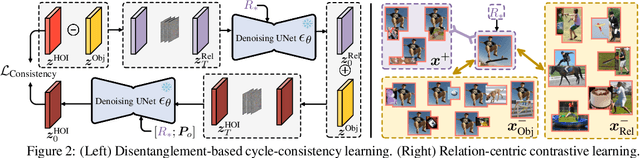
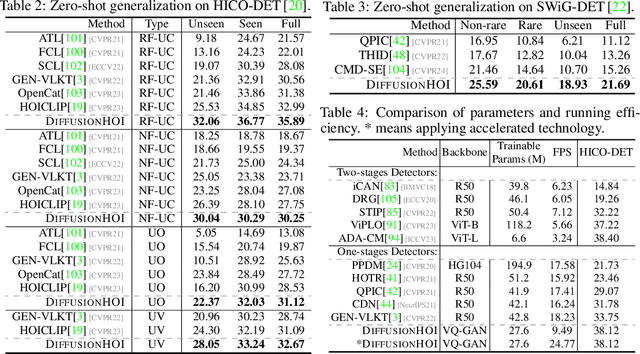
Prevalent human-object interaction (HOI) detection approaches typically leverage large-scale visual-linguistic models to help recognize events involving humans and objects. Though promising, models trained via contrastive learning on text-image pairs often neglect mid/low-level visual cues and struggle at compositional reasoning. In response, we introduce DIFFUSIONHOI, a new HOI detector shedding light on text-to-image diffusion models. Unlike the aforementioned models, diffusion models excel in discerning mid/low-level visual concepts as generative models, and possess strong compositionality to handle novel concepts expressed in text inputs. Considering diffusion models usually emphasize instance objects, we first devise an inversion-based strategy to learn the expression of relation patterns between humans and objects in embedding space. These learned relation embeddings then serve as textual prompts, to steer diffusion models generate images that depict specific interactions, and extract HOI-relevant cues from images without heavy fine-tuning. Benefited from above, DIFFUSIONHOI achieves SOTA performance on three datasets under both regular and zero-shot setups.