 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEEAvatar: Photorealistic Text-to-3D Avatar Generation with Constrained Geometry and Appearance
Dec 26, 2023Powered by large-scale text-to-image generation models, text-to-3D avatar generation has made promising progress. However, most methods fail to produce photorealistic results, limited by imprecise geometry and low-quality appearance. Towards more practical avatar generation, we present SEEAvatar, a method for generating photorealistic 3D avatars from text with SElf-Evolving constraints for decoupled geometry and appearance. For geometry, we propose to constrain the optimized avatar in a decent global shape with a template avatar. The template avatar is initialized with human prior and can be updated by the optimized avatar periodically as an evolving template, which enables more flexible shape generation. Besides, the geometry is also constrained by the static human prior in local parts like face and hands to maintain the delicate structures. For appearance generation, we use diffusion model enhanced by prompt engineering to guide a physically based rendering pipeline to generate realistic textures. The lightness constraint is applied on the albedo texture to suppress incorrect lighting effect. Experiments show that our method outperforms previous methods on both global and local geometry and appearance quality by a large margin. Since our method can produce high-quality meshes and textures, such assets can be directly applied in classic graphics pipeline for realistic rendering under any lighting condition. Project page at: https://yoxu515.github.io/SEEAvatar/.
Integrating Boxes and Masks: A Multi-Object Framework for Unified Visual Tracking and Segmentation
Aug 28, 2023



Tracking any given object(s) spatially and temporally is a common purpose in Visual Object Tracking (VOT) and Video Object Segmentation (VOS). Joint tracking and segmentation have been attempted in some studies but they often lack full compatibility of both box and mask in initialization and prediction, and mainly focus on single-object scenarios. To address these limitations, this paper proposes a Multi-object Mask-box Integrated framework for unified Tracking and Segmentation, dubbed MITS. Firstly, the unified identification module is proposed to support both box and mask reference for initialization, where detailed object information is inferred from boxes or directly retained from masks. Additionally, a novel pinpoint box predictor is proposed for accurate multi-object box prediction, facilitating target-oriented representation learning. All target objects are processed simultaneously from encoding to propagation and decoding, as a unified pipeline for VOT and VOS. Experimental results show MITS achieves state-of-the-art performance on both VOT and VOS benchmarks. Notably, MITS surpasses the best prior VOT competitor by around 6% on the GOT-10k test set, and significantly improves the performance of box initialization on VOS benchmarks. The code is available at https://github.com/yoxu515/MITS.
ZJU ReLER Submission for EPIC-KITCHEN Challenge 2023: TREK-150 Single Object Tracking
Jul 10, 2023



The Associating Objects with Transformers (AOT) framework has exhibited exceptional performance in a wide range of complex scenarios for video object tracking and segmentation. In this study, we convert the bounding boxes to masks in reference frames with the help of the Segment Anything Model (SAM) and Alpha-Refine, and then propagate the masks to the current frame, transforming the task from Video Object Tracking (VOT) to video object segmentation (VOS). Furthermore, we introduce MSDeAOT, a variant of the AOT series that incorporates transformers at multiple feature scales. MSDeAOT efficiently propagates object masks from previous frames to the current frame using two feature scales of 16 and 8. As a testament to the effectiveness of our design, we achieved the 1st place in the EPIC-KITCHENS TREK-150 Object Tracking Challenge.
ZJU ReLER Submission for EPIC-KITCHEN Challenge 2023: Semi-Supervised Video Object Segmentation
Jul 10, 2023The Associating Objects with Transformers (AOT) framework has exhibited exceptional performance in a wide range of complex scenarios for video object segmentation. In this study, we introduce MSDeAOT, a variant of the AOT series that incorporates transformers at multiple feature scales. Leveraging the hierarchical Gated Propagation Module (GPM), MSDeAOT efficiently propagates object masks from previous frames to the current frame using a feature scale with a stride of 16. Additionally, we employ GPM in a more refined feature scale with a stride of 8, leading to improved accuracy in detecting and tracking small objects. Through the implementation of test-time augmentations and model ensemble techniques, we achieve the top-ranking position in the EPIC-KITCHEN VISOR Semi-supervised Video Object Segmentation Challenge.
Segment and Track Anything
May 11, 2023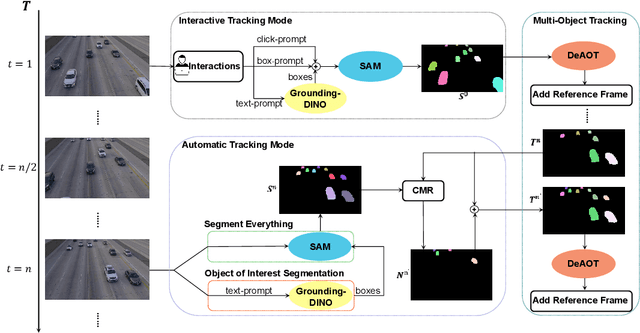
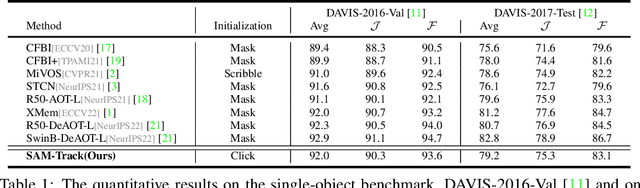


This report presents a framework called Segment And Track Anything (SAMTrack) that allows users to precisely and effectively segment and track any object in a video. Additionally, SAM-Track employs multimodal interaction methods that enable users to select multiple objects in videos for tracking, corresponding to their specific requirements. These interaction methods comprise click, stroke, and text, each possessing unique benefits and capable of being employed in combination. As a result, SAM-Track can be used across an array of fields, ranging from drone technology, autonomous driving, medical imaging, augmented reality, to biological analysis. SAM-Track amalgamates Segment Anything Model (SAM), an interactive key-frame segmentation model, with our proposed AOT-based tracking model (DeAOT), which secured 1st place in four tracks of the VOT 2022 challenge, to facilitate object tracking in video. In addition, SAM-Track incorporates Grounding-DINO, which enables the framework to support text-based interaction. We have demonstrated the remarkable capabilities of SAM-Track on DAVIS-2016 Val (92.0%), DAVIS-2017 Test (79.2%)and its practicability in diverse applications. The project page is available at: https://github.com/z-x-yang/Segment-and-Track-Anything.
Video Object Segmentation in Panoptic Wild Scenes
May 08, 2023



In this paper, we introduce semi-supervised video object segmentation (VOS) to panoptic wild scenes and present a large-scale benchmark as well as a baseline method for it. Previous benchmarks for VOS with sparse annotations are not sufficient to train or evaluate a model that needs to process all possible objects in real-world scenarios. Our new benchmark (VIPOSeg) contains exhaustive object annotations and covers various real-world object categories which are carefully divided into subsets of thing/stuff and seen/unseen classes for comprehensive evaluation. Considering the challenges in panoptic VOS, we propose a strong baseline method named panoptic object association with transformers (PAOT), which uses panoptic identification to associate objects with a pyramid architecture on multiple scales. Experimental results show that VIPOSeg can not only boost the performance of VOS models by panoptic training but also evaluate them comprehensively in panoptic scenes. Previous methods for classic VOS still need to improve in performance and efficiency when dealing with panoptic scenes, while our PAOT achieves SOTA performance with good efficiency on VIPOSeg and previous VOS benchmarks. PAOT also ranks 1st in the VOT2022 challenge. Our dataset is available at https://github.com/yoxu515/VIPOSeg-Benchmark.
Semantic Segmentation of Panoramic Images Using a Synthetic Dataset
Sep 02, 2019



Panoramic images have advantages in information capacity and scene stability due to their large field of view (FoV). In this paper, we propose a method to synthesize a new dataset of panoramic image. We managed to stitch the images taken from different directions into panoramic images, together with their labeled images, to yield the panoramic semantic segmentation dataset denominated as SYNTHIA-PANO. For the purpose of finding out the effect of using panoramic images as training dataset, we designed and performed a comprehensive set of experiments. Experimental results show that using panoramic images as training data is beneficial to the segmentation result. In addition, it has been shown that by using panoramic images with a 180 degree FoV as training data the model has better performance. Furthermore, the model trained with panoramic images also has a better capacity to resist the image distortion.