 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScholar Inbox: Personalized Paper Recommendations for Scientists
Apr 11, 2025
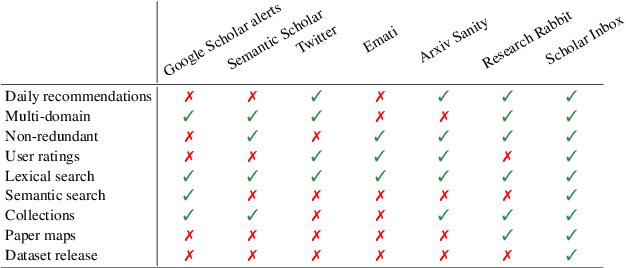

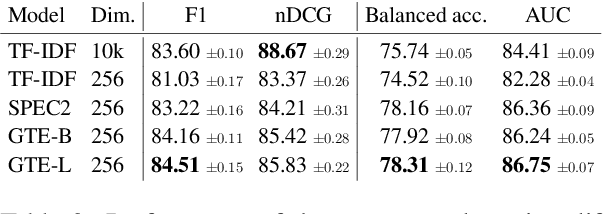
Scholar Inbox is a new open-access platform designed to address the challenges researchers face in staying current with the rapidly expanding volume of scientific literature. We provide personalized recommendations, continuous updates from open-access archives (arXiv, bioRxiv, etc.), visual paper summaries, semantic search, and a range of tools to streamline research workflows and promote open research access. The platform's personalized recommendation system is trained on user ratings, ensuring that recommendations are tailored to individual researchers' interests. To further enhance the user experience, Scholar Inbox also offers a map of science that provides an overview of research across domains, enabling users to easily explore specific topics. We use this map to address the cold start problem common in recommender systems, as well as an active learning strategy that iteratively prompts users to rate a selection of papers, allowing the system to learn user preferences quickly. We evaluate the quality of our recommendation system on a novel dataset of 800k user ratings, which we make publicly available, as well as via an extensive user study. https://www.scholar-inbox.com/
HDT: Hierarchical Document Transformer
Jul 11, 2024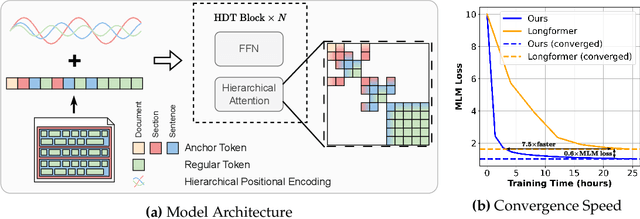

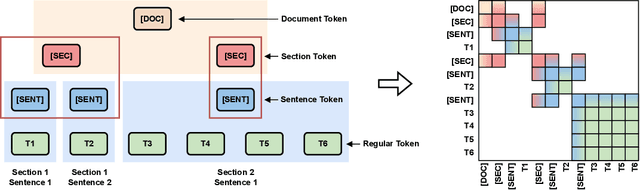

In this paper, we propose the Hierarchical Document Transformer (HDT), a novel sparse Transformer architecture tailored for structured hierarchical documents. Such documents are extremely important in numerous domains, including science, law or medicine. However, most existing solutions are inefficient and fail to make use of the structure inherent to documents. HDT exploits document structure by introducing auxiliary anchor tokens and redesigning the attention mechanism into a sparse multi-level hierarchy. This approach facilitates information exchange between tokens at different levels while maintaining sparsity, thereby enhancing computational and memory efficiency while exploiting the document structure as an inductive bias. We address the technical challenge of implementing HDT's sample-dependent hierarchical attention pattern by developing a novel sparse attention kernel that considers the hierarchical structure of documents. As demonstrated by our experiments, utilizing structural information present in documents leads to faster convergence, higher sample efficiency and better performance on downstream tasks.