 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity Adaptive Attention-based Speech Network: Enhancing Feature Understanding for Mental Health Disorders
Aug 31, 2024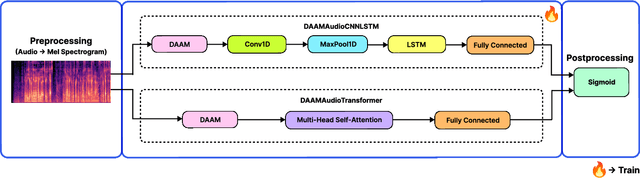
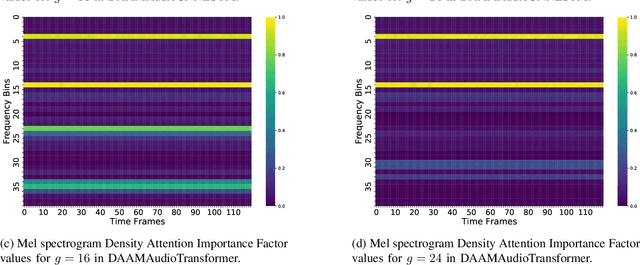
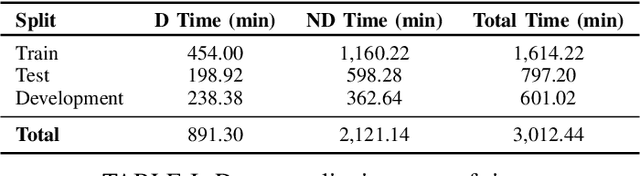
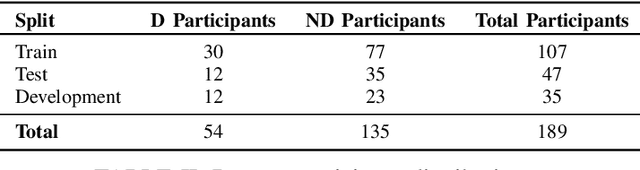
Speech-based depression detection poses significant challenges for automated detection due to its unique manifestation across individuals and data scarcity. Addressing these challenges, we introduce DAAMAudioCNNLSTM and DAAMAudioTransformer, two parameter efficient and explainable models for audio feature extraction and depression detection. DAAMAudioCNNLSTM features a novel CNN-LSTM framework with multi-head Density Adaptive Attention Mechanism (DAAM), focusing dynamically on informative speech segments. DAAMAudioTransformer, leveraging a transformer encoder in place of the CNN-LSTM architecture, incorporates the same DAAM module for enhanced attention and interpretability. These approaches not only enhance detection robustness and interpretability but also achieve state-of-the-art performance: DAAMAudioCNNLSTM with an F1 macro score of 0.702 and DAAMAudioTransformer with an F1 macro score of 0.72 on the DAIC-WOZ dataset, without reliance on supplementary information such as vowel positions and speaker information during training/validation as in previous approaches. Both models' significant explainability and efficiency in leveraging speech signals for depression detection represent a leap towards more reliable, clinically useful diagnostic tools, promising advancements in speech and mental health care. To foster further research in this domain, we make our code publicly available.
Out-of-Distribution Detection with Attention Head Masking for Multimodal Document Classification
Aug 20, 2024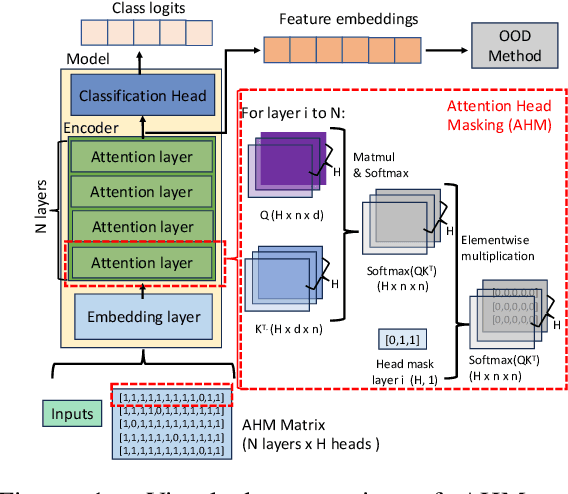
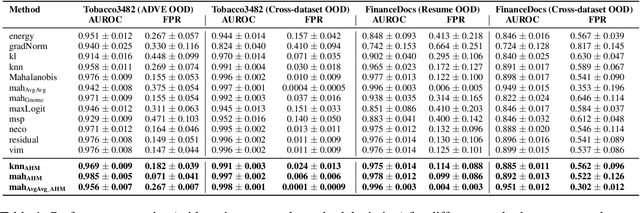

Detecting out-of-distribution (OOD) data is crucial in machine learning applications to mitigate the risk of model overconfidence, thereby enhancing the reliability and safety of deployed systems. The majority of existing OOD detection methods predominantly address uni-modal inputs, such as images or texts. In the context of multi-modal documents, there is a notable lack of extensive research on the performance of these methods, which have primarily been developed with a focus on computer vision tasks. We propose a novel methodology termed as attention head masking (AHM) for multi-modal OOD tasks in document classification systems. Our empirical results demonstrate that the proposed AHM method outperforms all state-of-the-art approaches and significantly decreases the false positive rate (FPR) compared to existing solutions up to 7.5\%. This methodology generalizes well to multi-modal data, such as documents, where visual and textual information are modeled under the same Transformer architecture. To address the scarcity of high-quality publicly available document datasets and encourage further research on OOD detection for documents, we introduce FinanceDocs, a new document AI dataset. Our code and dataset are publicly available.
Gaussian Adaptive Attention is All You Need: Robust Contextual Representations Across Multiple Modalities
Jan 31, 2024We propose the Multi-Head Gaussian Adaptive Attention Mechanism (GAAM), a novel probabilistic attention framework, and the Gaussian Adaptive Transformer (GAT), designed to enhance information aggregation across multiple modalities, including Speech, Text and Vision. GAAM integrates learnable mean and variance into its attention mechanism, implemented in a Multi-Headed framework enabling it to collectively model any Probability Distribution for dynamic recalibration of feature significance. This method demonstrates significant improvements, especially with highly non-stationary data, surpassing the state-of-the-art attention techniques in model performance (up to approximately +20% in accuracy) by identifying key elements within the feature space. GAAM's compatibility with dot-product-based attention models and relatively low number of parameters showcases its adaptability and potential to boost existing attention frameworks. Empirically, GAAM exhibits superior adaptability and efficacy across a diverse range of tasks, including emotion recognition in speech, image classification, and text classification, thereby establishing its robustness and versatility in handling multi-modal data. Furthermore, we introduce the Importance Factor (IF), a new learning-based metric that enhances the explainability of models trained with GAAM-based methods. Overall, GAAM represents an advancement towards development of better performing and more explainable attention models across multiple modalities.
Real-Time Speech Enhancement Using Spectral Subtraction with Minimum Statistics and Spectral Floor
Feb 20, 2023An initial real-time speech enhancement method is presented to reduce the effects of additive noise. The method operates in the frequency domain and is a form of spectral subtraction. Initially, minimum statistics are used to generate an estimate of the noise signal in the frequency domain. The use of minimum statistics avoids the need for a voice activity detector (VAD) which has proven to be challenging to create. As minimum statistics are used, the noise signal estimate must be multiplied by a scaling factor before subtraction from the noise corrupted speech signal can take place. A spectral floor is applied to the difference to suppress the effects of "musical noise". Finally, a series of further enhancements are considered to reduce the effects of residual noise even further. These methods are compared using time-frequency plots to create the final speech enhancement design