 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-JEPA : Soft Clustering Anchors for Self-Supervised Speech Representation Learning
Jun 17, 2026Self-supervised speech encoders are predominantly trained by predicting discrete hard cluster IDs at masked positions, a recipe that collapses acoustic ambiguity at category boundaries and requires interrupting training to re-cluster the entire corpus between iterations. We introduce S-JEPA, a JEPA-style encoder-predictor pair trained to match the soft posteriors of a Gaussian Mixture Model at masked positions via KL divergence. Training runs as one continuous optimization trajectory in two phases: a fixed GMM over MFCC features, then an online GMM over encoder features, with the input layer selected adaptively from a label-free signal, removing both the offline re-cluster step and the hand-tuned choice of which transformer layer to cluster on. Under the SUPERB protocol, S-JEPA achieves the lowest WER among evaluated SSL methods below 90M parameters and matches HuBERT-Base on emotion recognition at roughly half its parameter count, establishing a new Pareto frontier without offline re-clustering or teacher distillation. An analysis of the predictor's per-frame entropy on held-out speech reveals a bimodal distribution with a substantial minority of frames near the entropy of a perfect two-cluster tie, providing direct empirical evidence that the soft-target objective preserves the acoustic ambiguity that hard targets would collapse. Code is available at https://github.com/gioannides/s-jepa.
TASR: Training-Free Adaptive Stopping for Iterative Retrieval
Jun 11, 2026Iterative retrieval-augmented generation agents commonly overspend by continuing to retrieve after the model has converged on an answer, incurring calls that change neither the prediction nor the supporting evidence. Existing remedies learn a stopping policy from labeled trajectories, tying the decision to a trained component that requires retraining for each new model or task. We propose TASR (Training-Free Adaptive Stopping Rule), a one-line predicate that fires when the model repeats its previous-round normalized answer and the isotonically calibrated logit margin exceeds 0.25. No classifier or value head is learned; the threshold is fixed across all twenty-four (model, retriever, corpus) configurations we evaluate. On a 3-model x 2-dataset distractor grid, TASR retains 94.8% of fixed-k=5's macro F1 at 62.6% of its calls and exceeds fixed-k=3 by +3.42 F1. The pattern holds on nine open-domain BM25 cells (55.01 F1 at 2.98 calls vs. 54.33 at 3.00 for fixed-k=3) and, with calibration locked from the distractor split, on nine dense-retrieval cells across two retriever families, with zero significant regressions in either extension. The rule was selected from an exhaustive enumeration of 381 candidate stopping rules; no alternative Pareto-dominates it on any evaluated configuration. A signal-quality analysis shows that verbalized 1-5 confidence collapses on RLHF-tuned models (96.5% of values equal 5, entropy 0.182 nats), while the logit margin achieves 44x better class-conditional separation, grounding the design in a measurable model pathology. TASR is an auditable, training-free Pareto baseline against which learned stopping controllers can be compared. Code is publicly available.
Density Adaptive Attention-based Speech Network: Enhancing Feature Understanding for Mental Health Disorders
Aug 31, 2024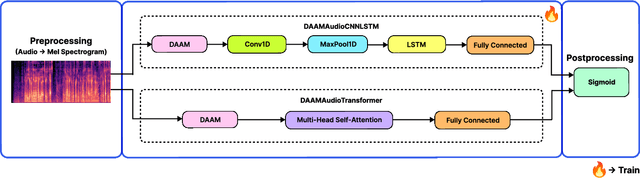
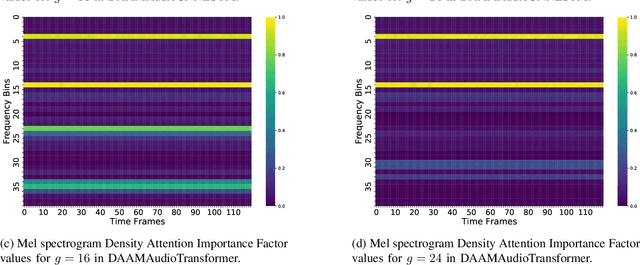
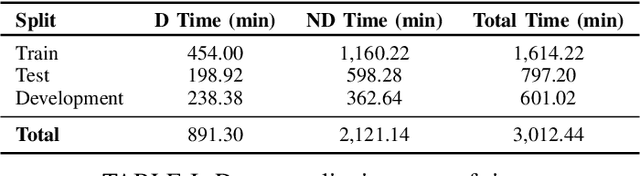
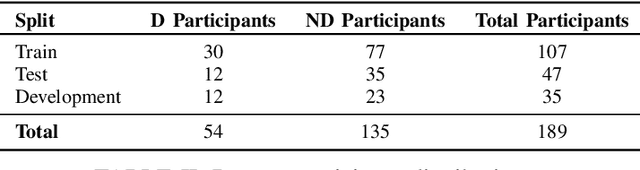
Speech-based depression detection poses significant challenges for automated detection due to its unique manifestation across individuals and data scarcity. Addressing these challenges, we introduce DAAMAudioCNNLSTM and DAAMAudioTransformer, two parameter efficient and explainable models for audio feature extraction and depression detection. DAAMAudioCNNLSTM features a novel CNN-LSTM framework with multi-head Density Adaptive Attention Mechanism (DAAM), focusing dynamically on informative speech segments. DAAMAudioTransformer, leveraging a transformer encoder in place of the CNN-LSTM architecture, incorporates the same DAAM module for enhanced attention and interpretability. These approaches not only enhance detection robustness and interpretability but also achieve state-of-the-art performance: DAAMAudioCNNLSTM with an F1 macro score of 0.702 and DAAMAudioTransformer with an F1 macro score of 0.72 on the DAIC-WOZ dataset, without reliance on supplementary information such as vowel positions and speaker information during training/validation as in previous approaches. Both models' significant explainability and efficiency in leveraging speech signals for depression detection represent a leap towards more reliable, clinically useful diagnostic tools, promising advancements in speech and mental health care. To foster further research in this domain, we make our code publicly available.
Out-of-Distribution Detection with Attention Head Masking for Multimodal Document Classification
Aug 20, 2024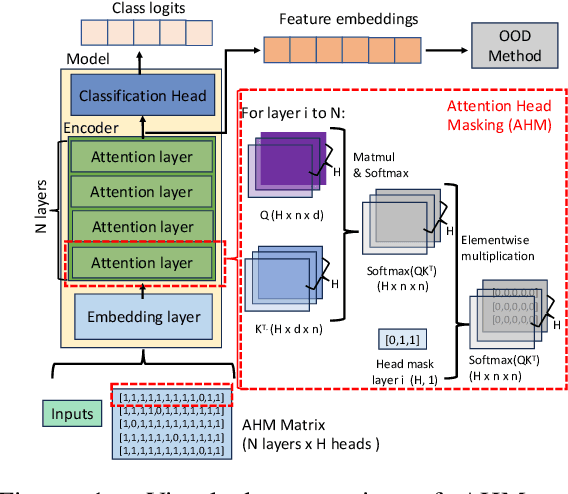
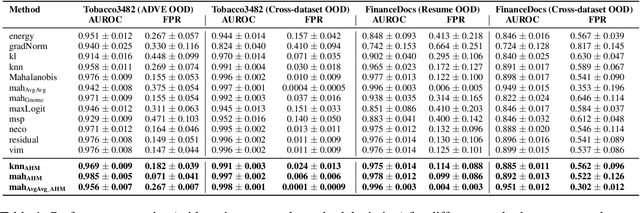

Detecting out-of-distribution (OOD) data is crucial in machine learning applications to mitigate the risk of model overconfidence, thereby enhancing the reliability and safety of deployed systems. The majority of existing OOD detection methods predominantly address uni-modal inputs, such as images or texts. In the context of multi-modal documents, there is a notable lack of extensive research on the performance of these methods, which have primarily been developed with a focus on computer vision tasks. We propose a novel methodology termed as attention head masking (AHM) for multi-modal OOD tasks in document classification systems. Our empirical results demonstrate that the proposed AHM method outperforms all state-of-the-art approaches and significantly decreases the false positive rate (FPR) compared to existing solutions up to 7.5\%. This methodology generalizes well to multi-modal data, such as documents, where visual and textual information are modeled under the same Transformer architecture. To address the scarcity of high-quality publicly available document datasets and encourage further research on OOD detection for documents, we introduce FinanceDocs, a new document AI dataset. Our code and dataset are publicly available.
Gaussian Adaptive Attention is All You Need: Robust Contextual Representations Across Multiple Modalities
Jan 31, 2024We propose the Multi-Head Gaussian Adaptive Attention Mechanism (GAAM), a novel probabilistic attention framework, and the Gaussian Adaptive Transformer (GAT), designed to enhance information aggregation across multiple modalities, including Speech, Text and Vision. GAAM integrates learnable mean and variance into its attention mechanism, implemented in a Multi-Headed framework enabling it to collectively model any Probability Distribution for dynamic recalibration of feature significance. This method demonstrates significant improvements, especially with highly non-stationary data, surpassing the state-of-the-art attention techniques in model performance (up to approximately +20% in accuracy) by identifying key elements within the feature space. GAAM's compatibility with dot-product-based attention models and relatively low number of parameters showcases its adaptability and potential to boost existing attention frameworks. Empirically, GAAM exhibits superior adaptability and efficacy across a diverse range of tasks, including emotion recognition in speech, image classification, and text classification, thereby establishing its robustness and versatility in handling multi-modal data. Furthermore, we introduce the Importance Factor (IF), a new learning-based metric that enhances the explainability of models trained with GAAM-based methods. Overall, GAAM represents an advancement towards development of better performing and more explainable attention models across multiple modalities.