 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity Adaptive Attention-based Speech Network: Enhancing Feature Understanding for Mental Health Disorders
Paper and Code
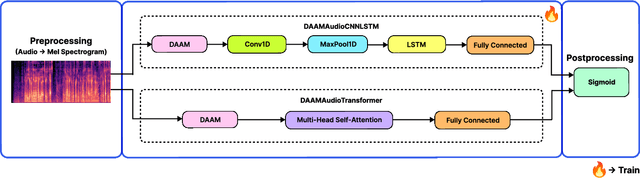
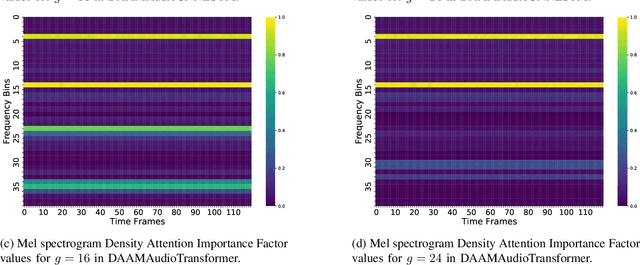
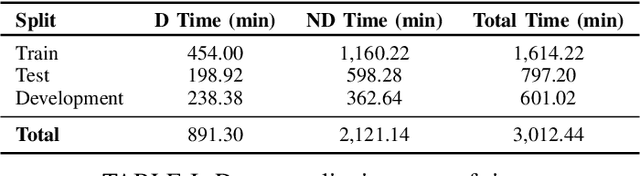
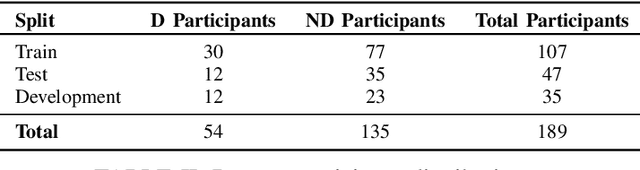
Speech-based depression detection poses significant challenges for automated detection due to its unique manifestation across individuals and data scarcity. Addressing these challenges, we introduce DAAMAudioCNNLSTM and DAAMAudioTransformer, two parameter efficient and explainable models for audio feature extraction and depression detection. DAAMAudioCNNLSTM features a novel CNN-LSTM framework with multi-head Density Adaptive Attention Mechanism (DAAM), focusing dynamically on informative speech segments. DAAMAudioTransformer, leveraging a transformer encoder in place of the CNN-LSTM architecture, incorporates the same DAAM module for enhanced attention and interpretability. These approaches not only enhance detection robustness and interpretability but also achieve state-of-the-art performance: DAAMAudioCNNLSTM with an F1 macro score of 0.702 and DAAMAudioTransformer with an F1 macro score of 0.72 on the DAIC-WOZ dataset, without reliance on supplementary information such as vowel positions and speaker information during training/validation as in previous approaches. Both models' significant explainability and efficiency in leveraging speech signals for depression detection represent a leap towards more reliable, clinically useful diagnostic tools, promising advancements in speech and mental health care. To foster further research in this domain, we make our code publicly available.