 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumosaic: Hyperspectral Video via Active Illumination and Coded-Exposure Pixels
Feb 25, 2026We present Lumosaic, a compact active hyperspectral video system designed for real-time capture of dynamic scenes. Our approach combines a narrowband LED array with a coded-exposure-pixel (CEP) camera capable of high-speed, per-pixel exposure control, enabling joint encoding of scene information across space, time, and wavelength within each video frame. Unlike passive snapshot systems that divide light across multiple spectral channels simultaneously and assume no motion during a frame's exposure, Lumosaic actively synchronizes illumination and pixel-wise exposure, improving photon utilization and preserving spectral fidelity under motion. A learning-based reconstruction pipeline then recovers 31-channel hyperspectral (400-700 nm) video at 30 fps and VGA resolution, producing temporally coherent and spectrally accurate reconstructions. Experiments on synthetic and real data demonstrate that Lumosaic significantly improves reconstruction fidelity and temporal stability over existing snapshot hyperspectral imaging systems, enabling robust hyperspectral video across diverse materials and motion conditions.
Initialization Schemes for Kolmogorov-Arnold Networks: An Empirical Study
Sep 03, 2025Kolmogorov-Arnold Networks (KANs) are a recently introduced neural architecture that replace fixed nonlinearities with trainable activation functions, offering enhanced flexibility and interpretability. While KANs have been applied successfully across scientific and machine learning tasks, their initialization strategies remain largely unexplored. In this work, we study initialization schemes for spline-based KANs, proposing two theory-driven approaches inspired by LeCun and Glorot, as well as an empirical power-law family with tunable exponents. Our evaluation combines large-scale grid searches on function fitting and forward PDE benchmarks, an analysis of training dynamics through the lens of the Neural Tangent Kernel, and evaluations on a subset of the Feynman dataset. Our findings indicate that the Glorot-inspired initialization significantly outperforms the baseline in parameter-rich models, while power-law initialization achieves the strongest performance overall, both across tasks and for architectures of varying size. All code and data accompanying this manuscript are publicly available at https://github.com/srigas/KAN_Initialization_Schemes.
Effectively Leveraging CLIP for Generating Situational Summaries of Images and Videos
Jul 30, 2024



Situation recognition refers to the ability of an agent to identify and understand various situations or contexts based on available information and sensory inputs. It involves the cognitive process of interpreting data from the environment to determine what is happening, what factors are involved, and what actions caused those situations. This interpretation of situations is formulated as a semantic role labeling problem in computer vision-based situation recognition. Situations depicted in images and videos hold pivotal information, essential for various applications like image and video captioning, multimedia retrieval, autonomous systems and event monitoring. However, existing methods often struggle with ambiguity and lack of context in generating meaningful and accurate predictions. Leveraging multimodal models such as CLIP, we propose ClipSitu, which sidesteps the need for full fine-tuning and achieves state-of-the-art results in situation recognition and localization tasks. ClipSitu harnesses CLIP-based image, verb, and role embeddings to predict nouns fulfilling all the roles associated with a verb, providing a comprehensive understanding of depicted scenarios. Through a cross-attention Transformer, ClipSitu XTF enhances the connection between semantic role queries and visual token representations, leading to superior performance in situation recognition. We also propose a verb-wise role prediction model with near-perfect accuracy to create an end-to-end framework for producing situational summaries for out-of-domain images. We show that situational summaries empower our ClipSitu models to produce structured descriptions with reduced ambiguity compared to generic captions. Finally, we extend ClipSitu to video situation recognition to showcase its versatility and produce comparable performance to state-of-the-art methods.
ClipSitu: Effectively Leveraging CLIP for Conditional Predictions in Situation Recognition
Jul 02, 2023Situation Recognition is the task of generating a structured summary of what is happening in an image using an activity verb and the semantic roles played by actors and objects. In this task, the same activity verb can describe a diverse set of situations as well as the same actor or object category can play a diverse set of semantic roles depending on the situation depicted in the image. Hence model needs to understand the context of the image and the visual-linguistic meaning of semantic roles. Therefore, we leverage the CLIP foundational model that has learned the context of images via language descriptions. We show that deeper-and-wider multi-layer perceptron (MLP) blocks obtain noteworthy results for the situation recognition task by using CLIP image and text embedding features and it even outperforms the state-of-the-art CoFormer, a Transformer-based model, thanks to the external implicit visual-linguistic knowledge encapsulated by CLIP and the expressive power of modern MLP block designs. Motivated by this, we design a cross-attention-based Transformer using CLIP visual tokens that model the relation between textual roles and visual entities. Our cross-attention-based Transformer known as ClipSitu XTF outperforms existing state-of-the-art by a large margin of 14.1% on semantic role labelling (value) for top-1 accuracy using imSitu dataset. We will make the code publicly available.
Evaluating Paraphrastic Robustness in Textual Entailment Models
Jun 29, 2023We present PaRTE, a collection of 1,126 pairs of Recognizing Textual Entailment (RTE) examples to evaluate whether models are robust to paraphrasing. We posit that if RTE models understand language, their predictions should be consistent across inputs that share the same meaning. We use the evaluation set to determine if RTE models' predictions change when examples are paraphrased. In our experiments, contemporary models change their predictions on 8-16\% of paraphrased examples, indicating that there is still room for improvement.
Addressing the Cold-Start Problem in Outfit Recommendation Using Visual Preference Modelling
Aug 04, 2020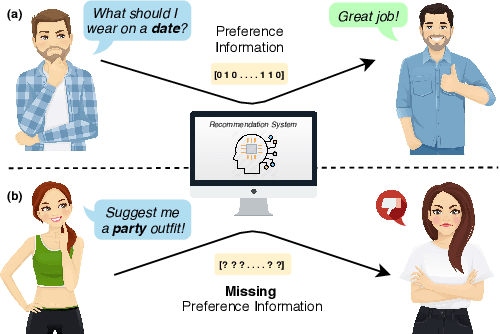
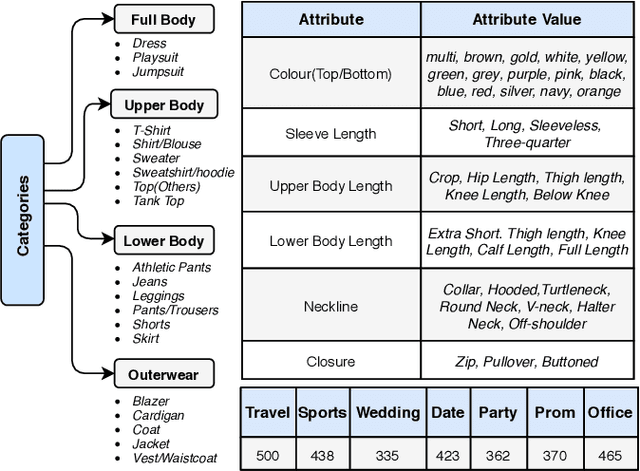
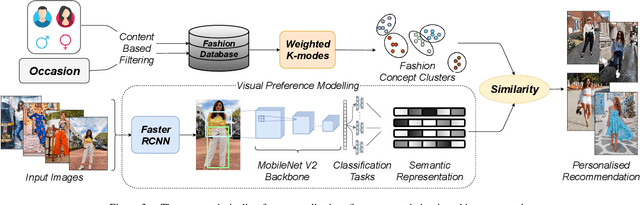
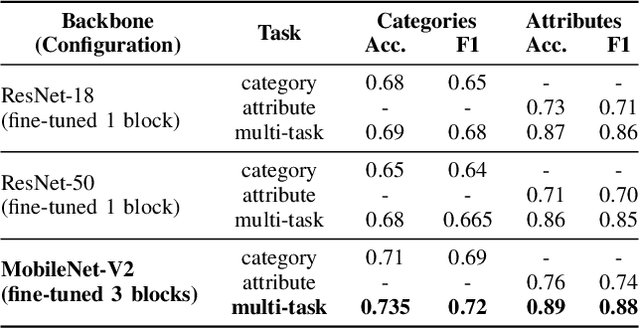
With the global transformation of the fashion industry and a rise in the demand for fashion items worldwide, the need for an effectual fashion recommendation has never been more. Despite various cutting-edge solutions proposed in the past for personalising fashion recommendation, the technology is still limited by its poor performance on new entities, i.e. the cold-start problem. In this paper, we attempt to address the cold-start problem for new users, by leveraging a novel visual preference modelling approach on a small set of input images. We demonstrate the use of our approach with feature-weighted clustering to personalise occasion-oriented outfit recommendation. Quantitatively, our results show that the proposed visual preference modelling approach outperforms state of the art in terms of clothing attribute prediction. Qualitatively, through a pilot study, we demonstrate the efficacy of our system to provide diverse and personalised recommendations in cold-start scenarios.