 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGATE X-E : A Challenge Set for Gender-Fair Translations from Weakly-Gendered Languages
Feb 22, 2024



Neural Machine Translation (NMT) continues to improve in quality and adoption, yet the inadvertent perpetuation of gender bias remains a significant concern. Despite numerous studies on gender bias in translations into English from weakly gendered-languages, there are no benchmarks for evaluating this phenomenon or for assessing mitigation strategies. To address this gap, we introduce GATE X-E, an extension to the GATE (Rarrick et al., 2023) corpus, that consists of human translations from Turkish, Hungarian, Finnish, and Persian into English. Each translation is accompanied by feminine, masculine, and neutral variants. The dataset, which contains between 1250 and 1850 instances for each of the four language pairs, features natural sentences with a wide range of sentence lengths and domains, challenging translation rewriters on various linguistic phenomena. Additionally, we present a translation gender rewriting solution built with GPT-4 and use GATE X-E to evaluate it. We open source our contributions to encourage further research on gender debiasing.
Reducing Gender Bias in Machine Translation through Counterfactual Data Generation
Nov 27, 2023



Recent advances in neural methods have led to substantial improvement in the quality of Neural Machine Translation (NMT) systems. However, these systems frequently produce translations with inaccurate gender (Stanovsky et al., 2019), which can be traced to bias in training data. Saunders and Byrne (2020) tackle this problem with a handcrafted dataset containing balanced gendered profession words. By using this data to fine-tune an existing NMT model, they show that gender bias can be significantly mitigated, albeit at the expense of translation quality due to catastrophic forgetting. They recover some of the lost quality with modified training objectives or additional models at inference. We find, however, that simply supplementing the handcrafted dataset with a random sample from the base model training corpus is enough to significantly reduce the catastrophic forgetting. We also propose a novel domain-adaptation technique that leverages in-domain data created with the counterfactual data generation techniques proposed by Zmigrod et al. (2019) to further improve accuracy on the WinoMT challenge test set without significant loss in translation quality. We show its effectiveness in NMT systems from English into three morphologically rich languages French, Spanish, and Italian. The relevant dataset and code will be available at Github.
Evaluating Gender Bias in the Translation of Gender-Neutral Languages into English
Nov 15, 2023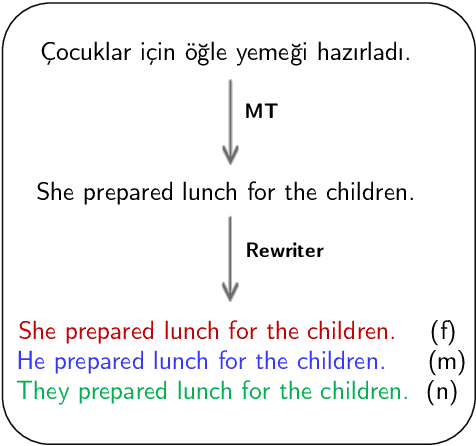



Machine Translation (MT) continues to improve in quality and adoption, yet the inadvertent perpetuation of gender bias remains a significant concern. Despite numerous studies into gender bias in translations from gender-neutral languages such as Turkish into more strongly gendered languages like English, there are no benchmarks for evaluating this phenomenon or for assessing mitigation strategies. To address this gap, we introduce GATE X-E, an extension to the GATE (Rarrick et al., 2023) corpus, that consists of human translations from Turkish, Hungarian, Finnish, and Persian into English. Each translation is accompanied by feminine, masculine, and neutral variants for each possible gender interpretation. The dataset, which contains between 1250 and 1850 instances for each of the four language pairs, features natural sentences with a wide range of sentence lengths and domains, challenging translation rewriters on various linguistic phenomena. Additionally, we present an English gender rewriting solution built on GPT-3.5 Turbo and use GATE X-E to evaluate it. We open source our contributions to encourage further research on gender debiasing.
KITAB: Evaluating LLMs on Constraint Satisfaction for Information Retrieval
Oct 24, 2023We study the ability of state-of-the art models to answer constraint satisfaction queries for information retrieval (e.g., 'a list of ice cream shops in San Diego'). In the past, such queries were considered to be tasks that could only be solved via web-search or knowledge bases. More recently, large language models (LLMs) have demonstrated initial emergent abilities in this task. However, many current retrieval benchmarks are either saturated or do not measure constraint satisfaction. Motivated by rising concerns around factual incorrectness and hallucinations of LLMs, we present KITAB, a new dataset for measuring constraint satisfaction abilities of language models. KITAB consists of book-related data across more than 600 authors and 13,000 queries, and also offers an associated dynamic data collection and constraint verification approach for acquiring similar test data for other authors. Our extended experiments on GPT4 and GPT3.5 characterize and decouple common failure modes across dimensions such as information popularity, constraint types, and context availability. Results show that in the absence of context, models exhibit severe limitations as measured by irrelevant information, factual errors, and incompleteness, many of which exacerbate as information popularity decreases. While context availability mitigates irrelevant information, it is not helpful for satisfying constraints, identifying fundamental barriers to constraint satisfaction. We open source our contributions to foster further research on improving constraint satisfaction abilities of future models.
Diversity of Thought Improves Reasoning Abilities of Large Language Models
Oct 11, 2023Large language models (LLMs) are documented to struggle in settings that require complex reasoning. Nevertheless, instructing the model to break down the problem into smaller reasoning steps (Wei et al., 2022), or ensembling various generations through modifying decoding steps (Wang et al., 2023) boosts performance. Current methods assume that the input prompt is fixed and expect the decoding strategies to introduce the diversity needed for ensembling. In this work, we relax this assumption and discuss how one can create and leverage variations of the input prompt as a means to diversity of thought to improve model performance. We propose a method that automatically improves prompt diversity by soliciting feedback from the LLM to ideate approaches that fit for the problem. We then ensemble the diverse prompts in our method DIV-SE (DIVerse reasoning path Self-Ensemble) across multiple inference calls. We also propose a cost-effective alternative where diverse prompts are used within a single inference call; we call this IDIV-SE (In-call DIVerse reasoning path Self-Ensemble). Under a fixed generation budget, DIV-SE and IDIV-SE outperform the previously discussed baselines using both GPT-3.5 and GPT-4 on several reasoning benchmarks, without modifying the decoding process. Additionally, DIV-SE advances state-of-the-art performance on recent planning benchmarks (Valmeekam et al., 2023), exceeding the highest previously reported accuracy by at least 29.6 percentage points on the most challenging 4/5 Blocksworld task. Our results shed light on how to enforce prompt diversity toward LLM reasoning and thereby improve the pareto frontier of the accuracy-cost trade-off.
Attention Satisfies: A Constraint-Satisfaction Lens on Factual Errors of Language Models
Sep 26, 2023We investigate the internal behavior of Transformer-based Large Language Models (LLMs) when they generate factually incorrect text. We propose modeling factual queries as Constraint Satisfaction Problems and use this framework to investigate how the model interacts internally with factual constraints. Specifically, we discover a strong positive relation between the model's attention to constraint tokens and the factual accuracy of its responses. In our curated suite of 11 datasets with over 40,000 prompts, we study the task of predicting factual errors with the Llama-2 family across all scales (7B, 13B, 70B). We propose SAT Probe, a method probing self-attention patterns, that can predict constraint satisfaction and factual errors, and allows early error identification. The approach and findings demonstrate how using the mechanistic understanding of factuality in LLMs can enhance reliability.
Social Biases through the Text-to-Image Generation Lens
Mar 30, 2023Text-to-Image (T2I) generation is enabling new applications that support creators, designers, and general end users of productivity software by generating illustrative content with high photorealism starting from a given descriptive text as a prompt. Such models are however trained on massive amounts of web data, which surfaces the peril of potential harmful biases that may leak in the generation process itself. In this paper, we take a multi-dimensional approach to studying and quantifying common social biases as reflected in the generated images, by focusing on how occupations, personality traits, and everyday situations are depicted across representations of (perceived) gender, age, race, and geographical location. Through an extensive set of both automated and human evaluation experiments we present findings for two popular T2I models: DALLE-v2 and Stable Diffusion. Our results reveal that there exist severe occupational biases of neutral prompts majorly excluding groups of people from results for both models. Such biases can get mitigated by increasing the amount of specification in the prompt itself, although the prompting mitigation will not address discrepancies in image quality or other usages of the model or its representations in other scenarios. Further, we observe personality traits being associated with only a limited set of people at the intersection of race, gender, and age. Finally, an analysis of geographical location representations on everyday situations (e.g., park, food, weddings) shows that for most situations, images generated through default location-neutral prompts are closer and more similar to images generated for locations of United States and Germany.
GATE: A Challenge Set for Gender-Ambiguous Translation Examples
Mar 07, 2023
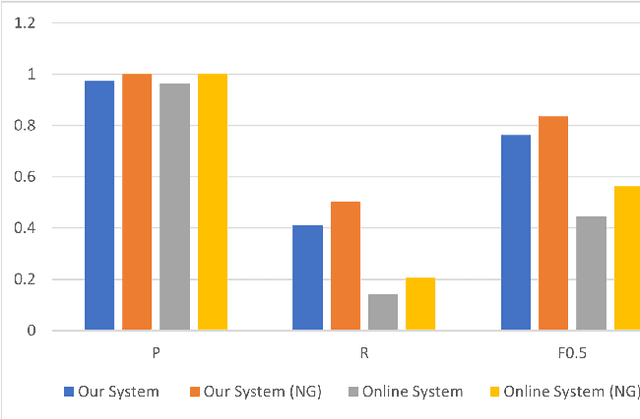


Although recent years have brought significant progress in improving translation of unambiguously gendered sentences, translation of ambiguously gendered input remains relatively unexplored. When source gender is ambiguous, machine translation models typically default to stereotypical gender roles, perpetuating harmful bias. Recent work has led to the development of "gender rewriters" that generate alternative gender translations on such ambiguous inputs, but such systems are plagued by poor linguistic coverage. To encourage better performance on this task we present and release GATE, a linguistically diverse corpus of gender-ambiguous source sentences along with multiple alternative target language translations. We also provide tools for evaluation and system analysis when using GATE and use them to evaluate our translation rewriter system.