 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Multiple Hybrid Adverse Weather in Video via a Unified Model
Mar 08, 2025Videos captured under real-world adverse weather conditions typically suffer from uncertain hybrid weather artifacts with heterogeneous degradation distributions. However, existing algorithms only excel at specific single degradation distributions due to limited adaption capacity and have to deal with different weather degradations with separately trained models, thus may fail to handle real-world stochastic weather scenarios. Besides, the model training is also infeasible due to the lack of paired video data to characterize the coexistence of multiple weather. To ameliorate the aforementioned issue, we propose a novel unified model, dubbed UniWRV, to remove multiple heterogeneous video weather degradations in an all-in-one fashion. Specifically, to tackle degenerate spatial feature heterogeneity, we propose a tailored weather prior guided module that queries exclusive priors for different instances as prompts to steer spatial feature characterization. To tackle degenerate temporal feature heterogeneity, we propose a dynamic routing aggregation module that can automatically select optimal fusion paths for different instances to dynamically integrate temporal features. Additionally, we managed to construct a new synthetic video dataset, termed HWVideo, for learning and benchmarking multiple hybrid adverse weather removal, which contains 15 hybrid weather conditions with a total of 1500 adverse-weather/clean paired video clips. Real-world hybrid weather videos are also collected for evaluating model generalizability. Comprehensive experiments demonstrate that our UniWRV exhibits robust and superior adaptation capability in multiple heterogeneous degradations learning scenarios, including various generic video restoration tasks beyond weather removal.
S2Gaussian: Sparse-View Super-Resolution 3D Gaussian Splatting
Mar 06, 2025In this paper, we aim ambitiously for a realistic yet challenging problem, namely, how to reconstruct high-quality 3D scenes from sparse low-resolution views that simultaneously suffer from deficient perspectives and clarity. Whereas existing methods only deal with either sparse views or low-resolution observations, they fail to handle such hybrid and complicated scenarios. To this end, we propose a novel Sparse-view Super-resolution 3D Gaussian Splatting framework, dubbed S2Gaussian, that can reconstruct structure-accurate and detail-faithful 3D scenes with only sparse and low-resolution views. The S2Gaussian operates in a two-stage fashion. In the first stage, we initially optimize a low-resolution Gaussian representation with depth regularization and densify it to initialize the high-resolution Gaussians through a tailored Gaussian Shuffle Split operation. In the second stage, we refine the high-resolution Gaussians with the super-resolved images generated from both original sparse views and pseudo-views rendered by the low-resolution Gaussians. In which a customized blur-free inconsistency modeling scheme and a 3D robust optimization strategy are elaborately designed to mitigate multi-view inconsistency and eliminate erroneous updates caused by imperfect supervision. Extensive experiments demonstrate superior results and in particular establishing new state-of-the-art performances with more consistent geometry and finer details.
Learn A Flexible Exploration Model for Parameterized Action Markov Decision Processes
Jan 06, 2025Hybrid action models are widely considered an effective approach to reinforcement learning (RL) modeling. The current mainstream method is to train agents under Parameterized Action Markov Decision Processes (PAMDPs), which performs well in specific environments. Unfortunately, these models either exhibit drastic low learning efficiency in complex PAMDPs or lose crucial information in the conversion between raw space and latent space. To enhance the learning efficiency and asymptotic performance of the agent, we propose a model-based RL (MBRL) algorithm, FLEXplore. FLEXplore learns a parameterized-action-conditioned dynamics model and employs a modified Model Predictive Path Integral control. Unlike conventional MBRL algorithms, we carefully design the dynamics loss function and reward smoothing process to learn a loose yet flexible model. Additionally, we use the variational lower bound to maximize the mutual information between the state and the hybrid action, enhancing the exploration effectiveness of the agent. We theoretically demonstrate that FLEXplore can reduce the regret of the rollout trajectory through the Wasserstein Metric under given Lipschitz conditions. Our empirical results on several standard benchmarks show that FLEXplore has outstanding learning efficiency and asymptotic performance compared to other baselines.
Cross-Consistent Deep Unfolding Network for Adaptive All-In-One Video Restoration
Sep 07, 2023Existing Video Restoration (VR) methods always necessitate the individual deployment of models for each adverse weather to remove diverse adverse weather degradations, lacking the capability for adaptive processing of degradations. Such limitation amplifies the complexity and deployment costs in practical applications. To overcome this deficiency, in this paper, we propose a Cross-consistent Deep Unfolding Network (CDUN) for All-In-One VR, which enables the employment of a single model to remove diverse degradations for the first time. Specifically, the proposed CDUN accomplishes a novel iterative optimization framework, capable of restoring frames corrupted by corresponding degradations according to the degradation features given in advance. To empower the framework for eliminating diverse degradations, we devise a Sequence-wise Adaptive Degradation Estimator (SADE) to estimate degradation features for the input corrupted video. By orchestrating these two cascading procedures, CDUN achieves adaptive processing for diverse degradation. In addition, we introduce a window-based inter-frame fusion strategy to utilize information from more adjacent frames. This strategy involves the progressive stacking of temporal windows in multiple iterations, effectively enlarging the temporal receptive field and enabling each frame's restoration to leverage information from distant frames. Extensive experiments demonstrate that the proposed method achieves state-of-the-art performance in All-In-One VR.
Data-free Black-box Attack based on Diffusion Model
Jul 24, 2023Since the training data for the target model in a data-free black-box attack is not available, most recent schemes utilize GANs to generate data for training substitute model. However, these GANs-based schemes suffer from low training efficiency as the generator needs to be retrained for each target model during the substitute training process, as well as low generation quality. To overcome these limitations, we consider utilizing the diffusion model to generate data, and propose a data-free black-box attack scheme based on diffusion model to improve the efficiency and accuracy of substitute training. Despite the data generated by the diffusion model exhibits high quality, it presents diverse domain distributions and contains many samples that do not meet the discriminative criteria of the target model. To further facilitate the diffusion model to generate data suitable for the target model, we propose a Latent Code Augmentation (LCA) method to guide the diffusion model in generating data. With the guidance of LCA, the data generated by the diffusion model not only meets the discriminative criteria of the target model but also exhibits high diversity. By utilizing this data, it is possible to train substitute model that closely resemble the target model more efficiently. Extensive experiments demonstrate that our LCA achieves higher attack success rates and requires fewer query budgets compared to GANs-based schemes for different target models.
DRM-IR: Task-Adaptive Deep Unfolding Network for All-In-One Image Restoration
Jul 15, 2023



Existing All-In-One image restoration (IR) methods usually lack flexible modeling on various types of degradation, thus impeding the restoration performance. To achieve All-In-One IR with higher task dexterity, this work proposes an efficient Dynamic Reference Modeling paradigm (DRM-IR), which consists of task-adaptive degradation modeling and model-based image restoring. Specifically, these two subtasks are formalized as a pair of entangled reference-based maximum a posteriori (MAP) inferences, which are optimized synchronously in an unfolding-based manner. With the two cascaded subtasks, DRM-IR first dynamically models the task-specific degradation based on a reference image pair and further restores the image with the collected degradation statistics. Besides, to bridge the semantic gap between the reference and target degraded images, we further devise a Degradation Prior Transmitter (DPT) that restrains the instance-specific feature differences. DRM-IR explicitly provides superior flexibility for All-in-One IR while being interpretable. Extensive experiments on multiple benchmark datasets show that our DRM-IR achieves state-of-the-art in All-In-One IR.
Rain Removal and Illumination Enhancement Done in One Go
Aug 09, 2021

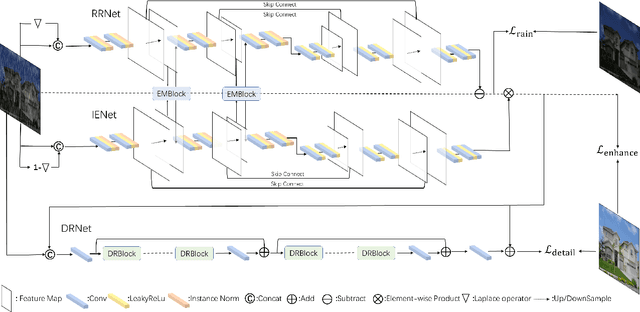

Rain removal plays an important role in the restoration of degraded images. Recently, data-driven methods have achieved remarkable success. However, these approaches neglect that the appearance of rain is often accompanied by low light conditions, which will further degrade the image quality. Therefore, it is very indispensable to jointly remove the rain and enhance the light for real-world rain image restoration. In this paper, we aim to address this problem from two aspects. First, we proposed a novel entangled network, namely EMNet, which can remove the rain and enhance illumination in one go. Specifically, two encoder-decoder networks interact complementary information through entanglement structure, and parallel rain removal and illumination enhancement. Considering that the encoder-decoder structure is unreliable in preserving spatial details, we employ a detail recovery network to restore the desired fine texture. Second, we present a new synthetic dataset, namely DarkRain, to boost the development of rain image restoration algorithms in practical scenarios. DarkRain not only contains different degrees of rain, but also considers different lighting conditions, and more realistically simulates the rainfall in the real world. EMNet is extensively evaluated on the proposed benchmark and achieves state-of-the-art results. In addition, after a simple transformation, our method outshines existing methods in both rain removal and low-light image enhancement. The source code and dataset will be made publicly available later.