 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
Removing Multiple Hybrid Adverse Weather in Video via a Unified Model
Mar 08, 2025Videos captured under real-world adverse weather conditions typically suffer from uncertain hybrid weather artifacts with heterogeneous degradation distributions. However, existing algorithms only excel at specific single degradation distributions due to limited adaption capacity and have to deal with different weather degradations with separately trained models, thus may fail to handle real-world stochastic weather scenarios. Besides, the model training is also infeasible due to the lack of paired video data to characterize the coexistence of multiple weather. To ameliorate the aforementioned issue, we propose a novel unified model, dubbed UniWRV, to remove multiple heterogeneous video weather degradations in an all-in-one fashion. Specifically, to tackle degenerate spatial feature heterogeneity, we propose a tailored weather prior guided module that queries exclusive priors for different instances as prompts to steer spatial feature characterization. To tackle degenerate temporal feature heterogeneity, we propose a dynamic routing aggregation module that can automatically select optimal fusion paths for different instances to dynamically integrate temporal features. Additionally, we managed to construct a new synthetic video dataset, termed HWVideo, for learning and benchmarking multiple hybrid adverse weather removal, which contains 15 hybrid weather conditions with a total of 1500 adverse-weather/clean paired video clips. Real-world hybrid weather videos are also collected for evaluating model generalizability. Comprehensive experiments demonstrate that our UniWRV exhibits robust and superior adaptation capability in multiple heterogeneous degradations learning scenarios, including various generic video restoration tasks beyond weather removal.
ROMA: Cross-Domain Region Similarity Matching for Unpaired Nighttime Infrared to Daytime Visible Video Translation
Apr 26, 2022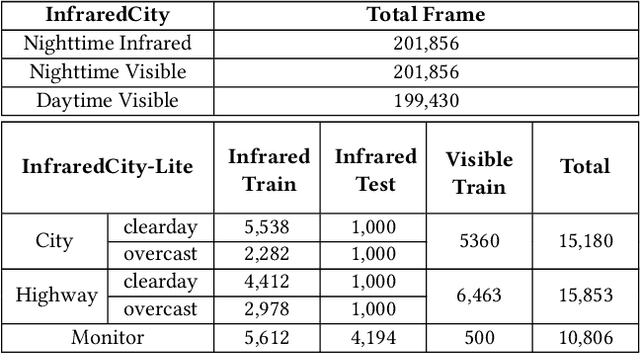
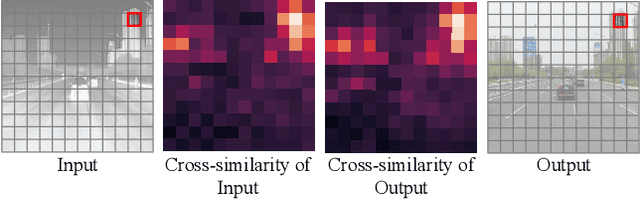
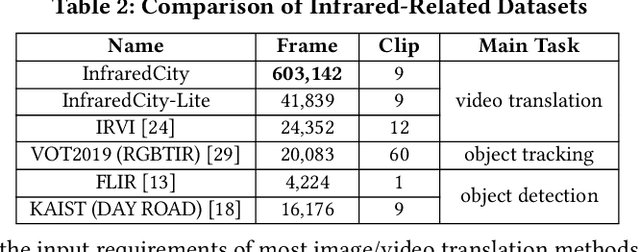
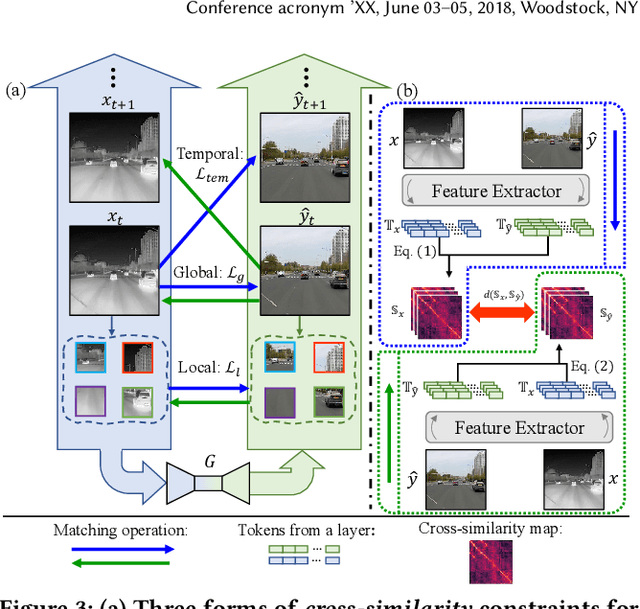
Infrared cameras are often utilized to enhance the night vision since the visible light cameras exhibit inferior efficacy without sufficient illumination. However, infrared data possesses inadequate color contrast and representation ability attributed to its intrinsic heat-related imaging principle. This makes it arduous to capture and analyze information for human beings, meanwhile hindering its application. Although, the domain gaps between unpaired nighttime infrared and daytime visible videos are even huger than paired ones that captured at the same time, establishing an effective translation mapping will greatly contribute to various fields. In this case, the structural knowledge within nighttime infrared videos and semantic information contained in the translated daytime visible pairs could be utilized simultaneously. To this end, we propose a tailored framework ROMA that couples with our introduced cRoss-domain regiOn siMilarity mAtching technique for bridging the huge gaps. To be specific, ROMA could efficiently translate the unpaired nighttime infrared videos into fine-grained daytime visible ones, meanwhile maintain the spatiotemporal consistency via matching the cross-domain region similarity. Furthermore, we design a multiscale region-wise discriminator to distinguish the details from synthesized visible results and real references. Extensive experiments and evaluations for specific applications indicate ROMA outperforms the state-of-the-art methods. Moreover, we provide a new and challenging dataset encouraging further research for unpaired nighttime infrared and daytime visible video translation, named InfraredCity. In particular, it consists of 9 long video clips including City, Highway and Monitor scenarios. All clips could be split into 603,142 frames in total, which are 20 times larger than the recently released daytime infrared-to-visible dataset IRVI.
I2V-GAN: Unpaired Infrared-to-Visible Video Translation
Aug 04, 2021
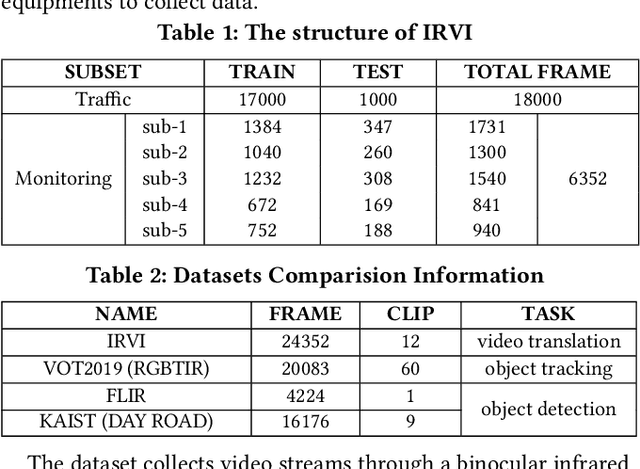
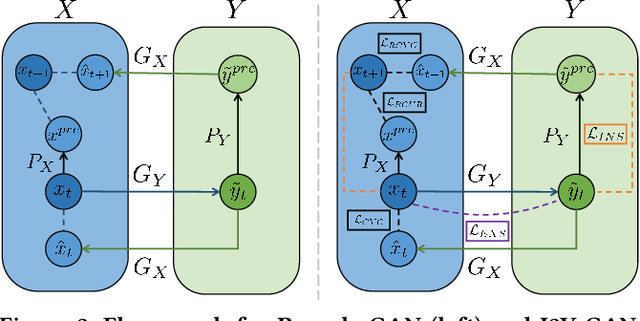
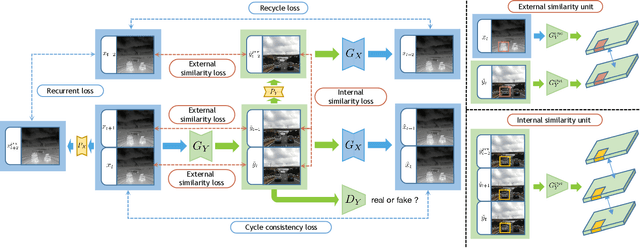
Human vision is often adversely affected by complex environmental factors, especially in night vision scenarios. Thus, infrared cameras are often leveraged to help enhance the visual effects via detecting infrared radiation in the surrounding environment, but the infrared videos are undesirable due to the lack of detailed semantic information. In such a case, an effective video-to-video translation method from the infrared domain to the visible light counterpart is strongly needed by overcoming the intrinsic huge gap between infrared and visible fields. To address this challenging problem, we propose an infrared-to-visible (I2V) video translation method I2V-GAN to generate fine-grained and spatial-temporal consistent visible light videos by given unpaired infrared videos. Technically, our model capitalizes on three types of constraints: 1)adversarial constraint to generate synthetic frames that are similar to the real ones, 2)cyclic consistency with the introduced perceptual loss for effective content conversion as well as style preservation, and 3)similarity constraints across and within domains to enhance the content and motion consistency in both spatial and temporal spaces at a fine-grained level. Furthermore, the current public available infrared and visible light datasets are mainly used for object detection or tracking, and some are composed of discontinuous images which are not suitable for video tasks. Thus, we provide a new dataset for I2V video translation, which is named IRVI. Specifically, it has 12 consecutive video clips of vehicle and monitoring scenes, and both infrared and visible light videos could be apart into 24352 frames. Comprehensive experiments validate that I2V-GAN is superior to the compared SOTA methods in the translation of I2V videos with higher fluency and finer semantic details. The code and IRVI dataset are available at https://github.com/BIT-DA/I2V-GAN.