 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics Inspired Hybrid Attention for SAR Target Recognition
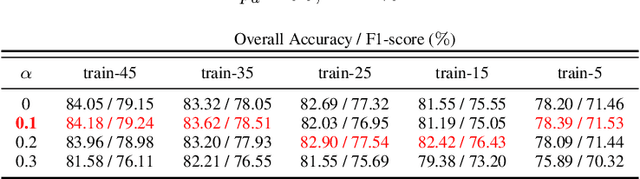
Sep 27, 2023There has been a recent emphasis on integrating physical models and deep neural networks (DNNs) for SAR target recognition, to improve performance and achieve a higher level of physical interpretability. The attributed scattering center (ASC) parameters garnered the most interest, being considered as additional input data or features for fusion in most methods. However, the performance greatly depends on the ASC optimization result, and the fusion strategy is not adaptable to different types of physical information. Meanwhile, the current evaluation scheme is inadequate to assess the model's robustness and generalizability. Thus, we propose a physics inspired hybrid attention (PIHA) mechanism and the once-for-all (OFA) evaluation protocol to address the above issues. PIHA leverages the high-level semantics of physical information to activate and guide the feature group aware of local semantics of target, so as to re-weight the feature importance based on knowledge prior. It is flexible and generally applicable to various physical models, and can be integrated into arbitrary DNNs without modifying the original architecture. The experiments involve a rigorous assessment using the proposed OFA, which entails training and validating a model on either sufficient or limited data and evaluating on multiple test sets with different data distributions. Our method outperforms other state-of-the-art approaches in 12 test scenarios with same ASC parameters. Moreover, we analyze the working mechanism of PIHA and evaluate various PIHA enabled DNNs. The experiments also show PIHA is effective for different physical information. The source code together with the adopted physical information is available at https://github.com/XAI4SAR.
Multi-grained Temporal Prototype Learning for Few-shot Video Object Segmentation
Sep 20, 2023Few-Shot Video Object Segmentation (FSVOS) aims to segment objects in a query video with the same category defined by a few annotated support images. However, this task was seldom explored. In this work, based on IPMT, a state-of-the-art few-shot image segmentation method that combines external support guidance information with adaptive query guidance cues, we propose to leverage multi-grained temporal guidance information for handling the temporal correlation nature of video data. We decompose the query video information into a clip prototype and a memory prototype for capturing local and long-term internal temporal guidance, respectively. Frame prototypes are further used for each frame independently to handle fine-grained adaptive guidance and enable bidirectional clip-frame prototype communication. To reduce the influence of noisy memory, we propose to leverage the structural similarity relation among different predicted regions and the support for selecting reliable memory frames. Furthermore, a new segmentation loss is also proposed to enhance the category discriminability of the learned prototypes. Experimental results demonstrate that our proposed video IPMT model significantly outperforms previous models on two benchmark datasets. Code is available at https://github.com/nankepan/VIPMT.
Progressively Dual Prior Guided Few-shot Semantic Segmentation
Nov 20, 2022


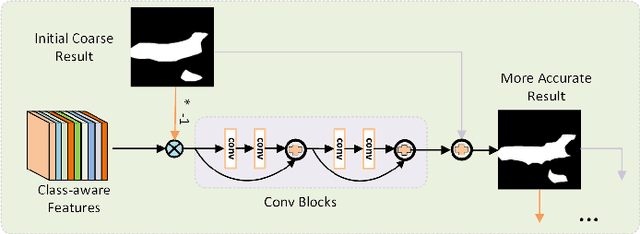
Few-shot semantic segmentation task aims at performing segmentation in query images with a few annotated support samples. Currently, few-shot segmentation methods mainly focus on leveraging foreground information without fully utilizing the rich background information, which could result in wrong activation of foreground-like background regions with the inadaptability to dramatic scene changes of support-query image pairs. Meanwhile, the lack of detail mining mechanism could cause coarse parsing results without some semantic components or edge areas since prototypes have limited ability to cope with large object appearance variance. To tackle these problems, we propose a progressively dual prior guided few-shot semantic segmentation network. Specifically, a dual prior mask generation (DPMG) module is firstly designed to suppress the wrong activation in foreground-background comparison manner by regarding background as assisted refinement information. With dual prior masks refining the location of foreground area, we further propose a progressive semantic detail enrichment (PSDE) module which forces the parsing model to capture the hidden semantic details by iteratively erasing the high-confidence foreground region and activating details in the rest region with a hierarchical structure. The collaboration of DPMG and PSDE formulates a novel few-shot segmentation network that can be learned in an end-to-end manner. Comprehensive experiments on PASCAL-5i and MS COCO powerfully demonstrate that our proposed algorithm achieves the great performance.
Intermediate Prototype Mining Transformer for Few-Shot Semantic Segmentation
Oct 13, 2022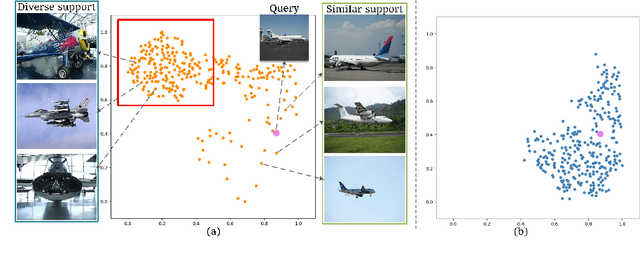
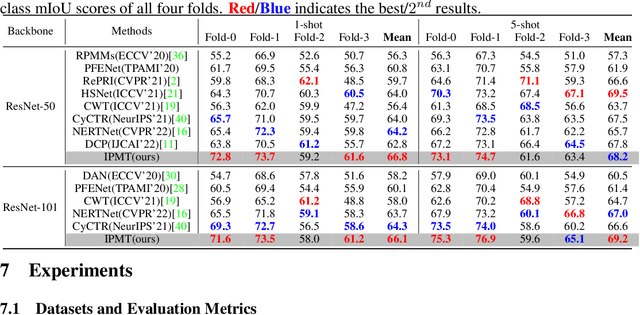
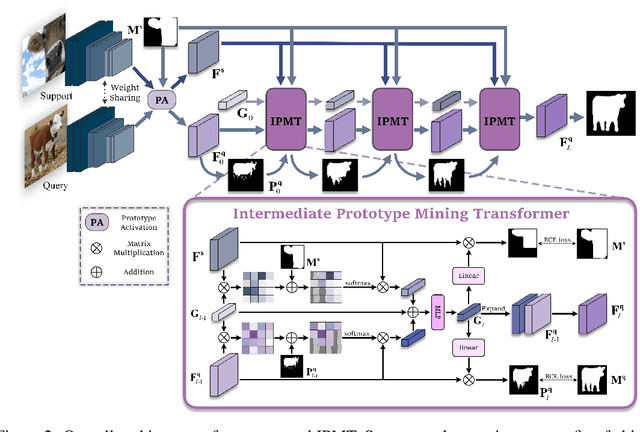

Few-shot semantic segmentation aims to segment the target objects in query under the condition of a few annotated support images. Most previous works strive to mine more effective category information from the support to match with the corresponding objects in query. However, they all ignored the category information gap between query and support images. If the objects in them show large intra-class diversity, forcibly migrating the category information from the support to the query is ineffective. To solve this problem, we are the first to introduce an intermediate prototype for mining both deterministic category information from the support and adaptive category knowledge from the query. Specifically, we design an Intermediate Prototype Mining Transformer (IPMT) to learn the prototype in an iterative way. In each IPMT layer, we propagate the object information in both support and query features to the prototype and then use it to activate the query feature map. By conducting this process iteratively, both the intermediate prototype and the query feature can be progressively improved. At last, the final query feature is used to yield precise segmentation prediction. Extensive experiments on both PASCAL-5i and COCO-20i datasets clearly verify the effectiveness of our IPMT and show that it outperforms previous state-of-the-art methods by a large margin. Code is available at https://github.com/LIUYUANWEI98/IPMT
Towards Large-Scale Small Object Detection: Survey and Benchmarks
Jul 31, 2022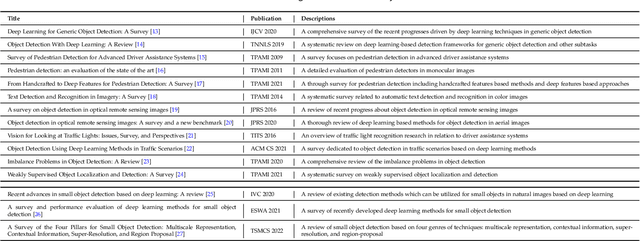
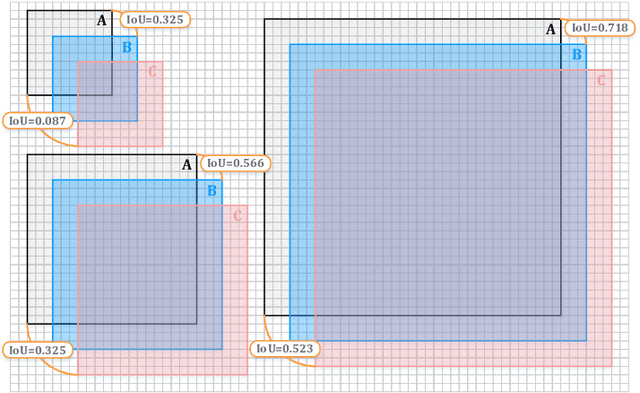
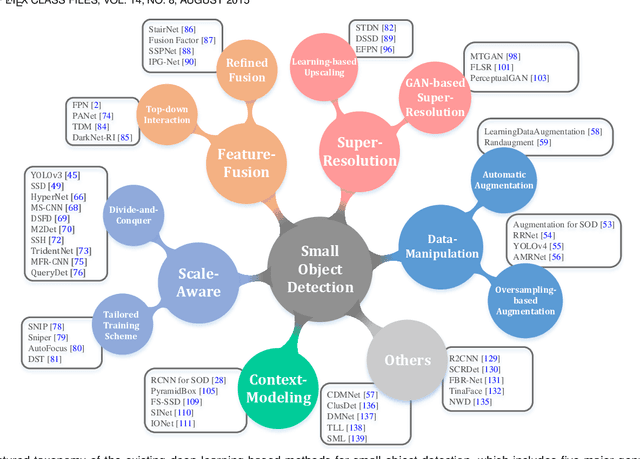
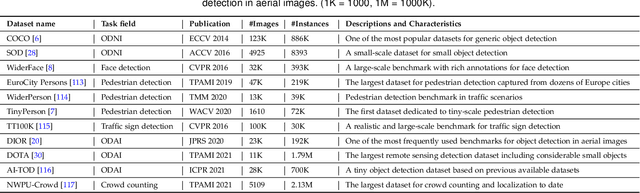
With the rise of deep convolutional neural networks, object detection has achieved prominent advances in past years. However, such prosperity could not camouflage the unsatisfactory situation of Small Object Detection (SOD), one of the notoriously challenging tasks in computer vision, owing to the poor visual appearance and noisy representation caused by the intrinsic structure of small targets. In addition, large-scale dataset for benchmarking small object detection methods remains a bottleneck. In this paper, we first conduct a thorough review of small object detection. Then, to catalyze the development of SOD, we construct two large-scale Small Object Detection dAtasets (SODA), SODA-D and SODA-A, which focus on the Driving and Aerial scenarios respectively. SODA-D includes 24704 high-quality traffic images and 277596 instances of 9 categories. For SODA-A, we harvest 2510 high-resolution aerial images and annotate 800203 instances over 9 classes. The proposed datasets, as we know, are the first-ever attempt to large-scale benchmarks with a vast collection of exhaustively annotated instances tailored for multi-category SOD. Finally, we evaluate the performance of mainstream methods on SODA. We expect the released benchmarks could facilitate the development of SOD and spawn more breakthroughs in this field. Datasets and codes will be available soon at: \url{https://shaunyuan22.github.io/SODA}.
Learning Non-target Knowledge for Few-shot Semantic Segmentation
May 10, 2022
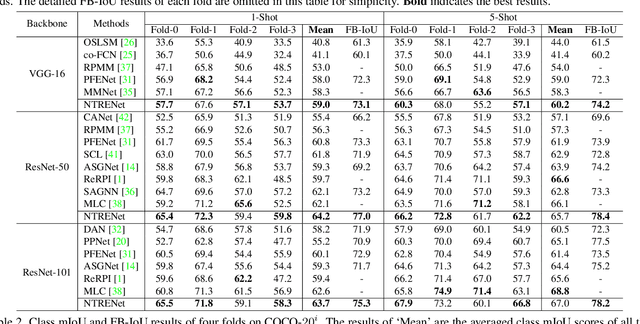
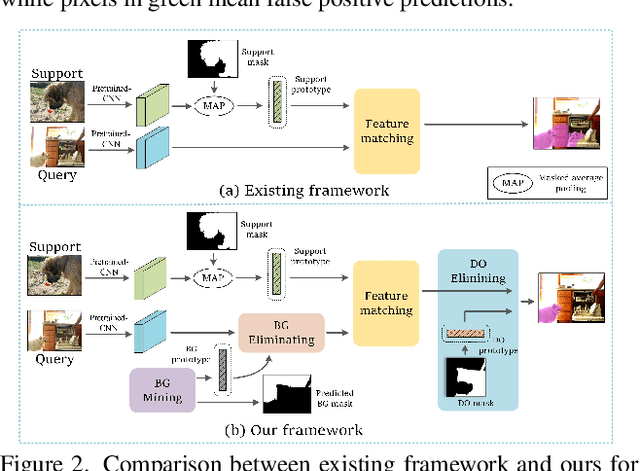
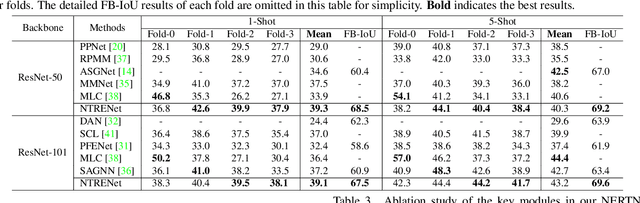
Existing studies in few-shot semantic segmentation only focus on mining the target object information, however, often are hard to tell ambiguous regions, especially in non-target regions, which include background (BG) and Distracting Objects (DOs). To alleviate this problem, we propose a novel framework, namely Non-Target Region Eliminating (NTRE) network, to explicitly mine and eliminate BG and DO regions in the query. First, a BG Mining Module (BGMM) is proposed to extract the BG region via learning a general BG prototype. To this end, we design a BG loss to supervise the learning of BGMM only using the known target object segmentation ground truth. Then, a BG Eliminating Module and a DO Eliminating Module are proposed to successively filter out the BG and DO information from the query feature, based on which we can obtain a BG and DO-free target object segmentation result. Furthermore, we propose a prototypical contrastive learning algorithm to improve the model ability of distinguishing the target object from DOs. Extensive experiments on both PASCAL-5i and COCO-20i datasets show that our approach is effective despite its simplicity.
Physically Explainable CNN for SAR Image Classification
Oct 27, 2021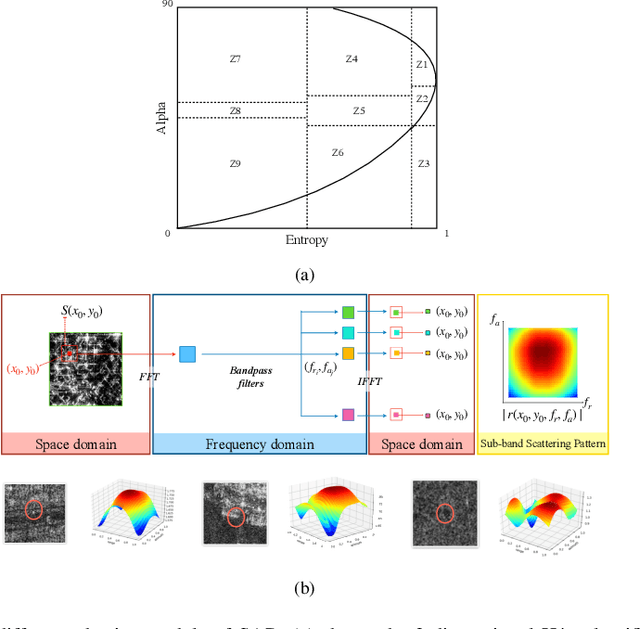


Integrating the special electromagnetic characteristics of Synthetic Aperture Radar (SAR) in deep neural networks is essential in order to enhance the explainability and physics awareness of deep learning. In this paper, we firstly propose a novel physics guided and injected neural network for SAR image classification, which is mainly guided by explainable physics models and can be learned with very limited labeled data. The proposed framework comprises three parts: (1) generating physics guided signals using existing explainable models, (2) learning physics-aware features with physics guided network, and (3) injecting the physics-aware features adaptively to the conventional classification deep learning model for prediction. The prior knowledge, physical scattering characteristic of SAR in this paper, is injected into the deep neural network in the form of physics-aware features which is more conducive to understanding the semantic labels of SAR image patches. A hybrid Image-Physics SAR dataset format is proposed, and both Sentinel-1 and Gaofen-3 SAR data are taken for evaluation. The experimental results show that our proposed method substantially improve the classification performance compared with the counterpart data-driven CNN. Moreover, the guidance of explainable physics signals leads to explainability of physics-aware features and the physics consistency of features are also preserved in the predictions. We deem the proposed method would promote the development of physically explainable deep learning in SAR image interpretation field.
Oriented R-CNN for Object Detection
Aug 12, 2021
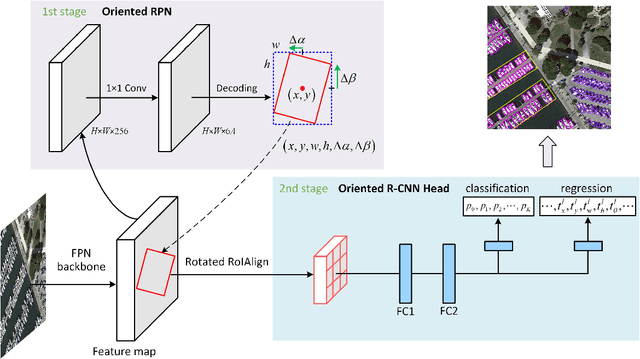
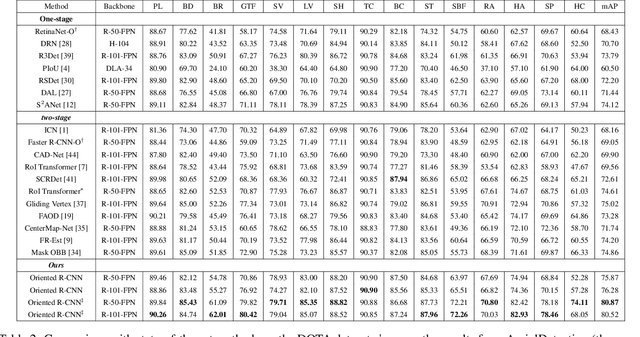
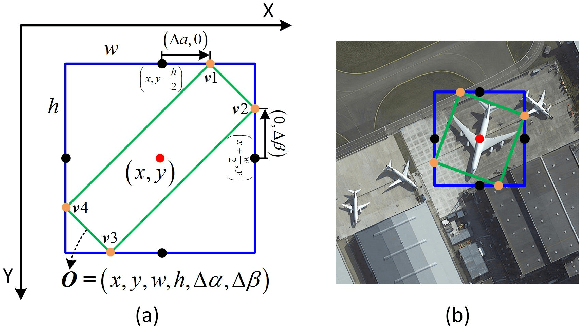
Current state-of-the-art two-stage detectors generate oriented proposals through time-consuming schemes. This diminishes the detectors' speed, thereby becoming the computational bottleneck in advanced oriented object detection systems. This work proposes an effective and simple oriented object detection framework, termed Oriented R-CNN, which is a general two-stage oriented detector with promising accuracy and efficiency. To be specific, in the first stage, we propose an oriented Region Proposal Network (oriented RPN) that directly generates high-quality oriented proposals in a nearly cost-free manner. The second stage is oriented R-CNN head for refining oriented Regions of Interest (oriented RoIs) and recognizing them. Without tricks, oriented R-CNN with ResNet50 achieves state-of-the-art detection accuracy on two commonly-used datasets for oriented object detection including DOTA (75.87% mAP) and HRSC2016 (96.50% mAP), while having a speed of 15.1 FPS with the image size of 1024$\times$1024 on a single RTX 2080Ti. We hope our work could inspire rethinking the design of oriented detectors and serve as a baseline for oriented object detection. Code is available at https://github.com/jbwang1997/OBBDetection.
Embedded Deep Bilinear Interactive Information and Selective Fusion for Multi-view Learning
Jul 13, 2020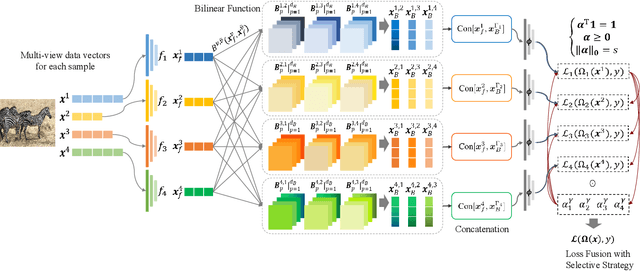
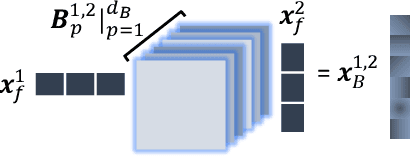

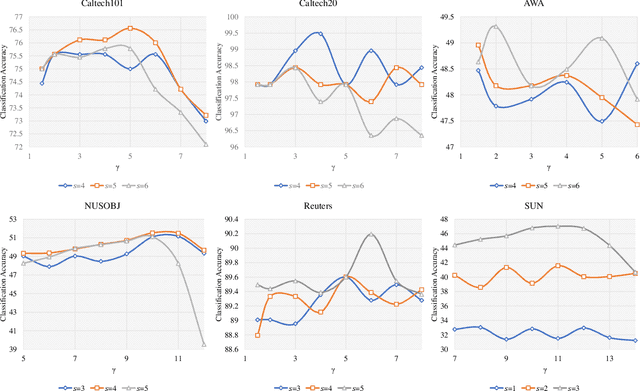
As a concrete application of multi-view learning, multi-view classification improves the traditional classification methods significantly by integrating various views optimally. Although most of the previous efforts have been demonstrated the superiority of multi-view learning, it can be further improved by comprehensively embedding more powerful cross-view interactive information and a more reliable multi-view fusion strategy in intensive studies. To fulfill this goal, we propose a novel multi-view learning framework to make the multi-view classification better aimed at the above-mentioned two aspects. That is, we seamlessly embed various intra-view information, cross-view multi-dimension bilinear interactive information, and a new view ensemble mechanism into a unified framework to make a decision via the optimization. In particular, we train different deep neural networks to learn various intra-view representations, and then dynamically learn multi-dimension bilinear interactive information from different bilinear similarities via the bilinear function between views. After that, we adaptively fuse the representations of multiple views by flexibly tuning the parameters of the view-weight, which not only avoids the trivial solution of weight but also provides a new way to select a few discriminative views that are beneficial to make a decision for the multi-view classification. Extensive experiments on six publicly available datasets demonstrate the effectiveness of the proposed method.