 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness Overfitting in Machine Learning: An Information-Theoretic Perspective
Jun 09, 2025Despite substantial progress in promoting fairness in high-stake applications using machine learning models, existing methods often modify the training process, such as through regularizers or other interventions, but lack formal guarantees that fairness achieved during training will generalize to unseen data. Although overfitting with respect to prediction performance has been extensively studied, overfitting in terms of fairness loss has received far less attention. This paper proposes a theoretical framework for analyzing fairness generalization error through an information-theoretic lens. Our novel bounding technique is based on Efron-Stein inequality, which allows us to derive tight information-theoretic fairness generalization bounds with both Mutual Information (MI) and Conditional Mutual Information (CMI). Our empirical results validate the tightness and practical relevance of these bounds across diverse fairness-aware learning algorithms. Our framework offers valuable insights to guide the design of algorithms improving fairness generalization.
SGLD-Based Information Criteria and the Over-Parameterized Regime
Jun 08, 2023



Double-descent refers to the unexpected drop in test loss of a learning algorithm beyond an interpolating threshold with over-parameterization, which is not predicted by information criteria in their classical forms due to the limitations in the standard asymptotic approach. We update these analyses using the information risk minimization framework and provide Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) for models learned by stochastic gradient Langevin dynamics (SGLD). Notably, the AIC and BIC penalty terms for SGLD correspond to specific information measures, i.e., symmetrized KL information and KL divergence. We extend this information-theoretic analysis to over-parameterized models by characterizing the SGLD-based BIC for the random feature model in the regime where the number of parameters $p$ and the number of samples $n$ tend to infinity, with $p/n$ fixed. Our experiments demonstrate that the refined SGLD-based BIC can track the double-descent curve, providing meaningful guidance for model selection and revealing new insights into the behavior of SGLD learning algorithms in the over-parameterized regime.
Style Variable and Irrelevant Learning for Generalizable Person Re-identification
Sep 12, 2022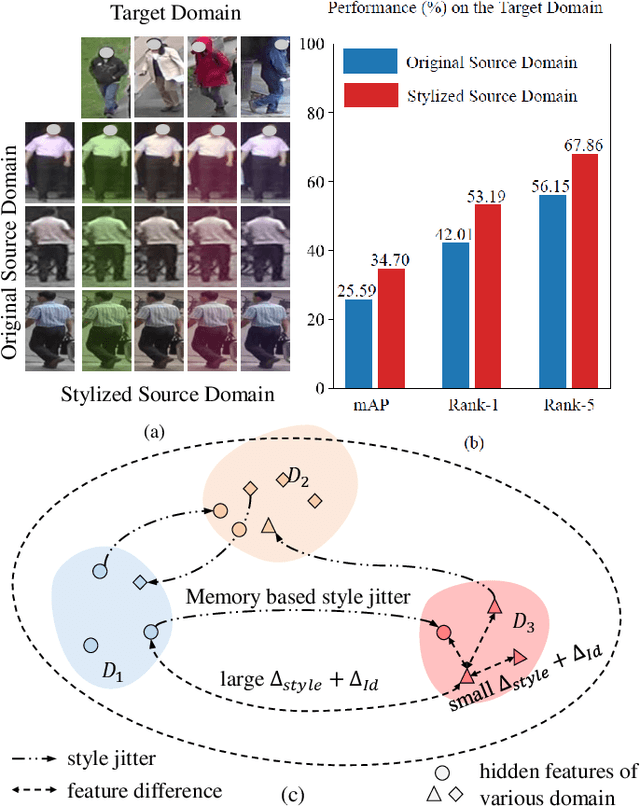
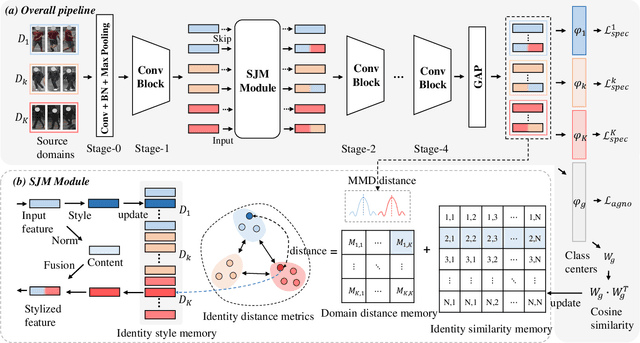
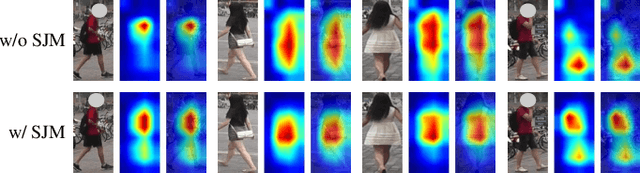
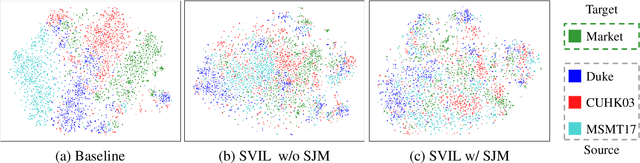
Recently, due to the poor performance of supervised person re-identification (ReID) to an unseen domain, Domain Generalization (DG) person ReID has attracted a lot of attention which aims to learn a domain-insensitive model and can resist the influence of domain bias. In this paper, we first verify through an experiment that style factors are a vital part of domain bias. Base on this conclusion, we propose a Style Variable and Irrelevant Learning (SVIL) method to eliminate the effect of style factors on the model. Specifically, we design a Style Jitter Module (SJM) in SVIL. The SJM module can enrich the style diversity of the specific source domain and reduce the style differences of various source domains. This leads to the model focusing on identity-relevant information and being insensitive to the style changes. Besides, we organically combine the SJM module with a meta-learning algorithm, maximizing the benefits and further improving the generalization ability of the model. Note that our SJM module is plug-and-play and inference cost-free. Extensive experiments confirm the effectiveness of our SVIL and our method outperforms the state-of-the-art methods on DG-ReID benchmarks by a large margin.
Symmetric Network with Spatial Relationship Modeling for Natural Language-based Vehicle Retrieval
Jun 22, 2022


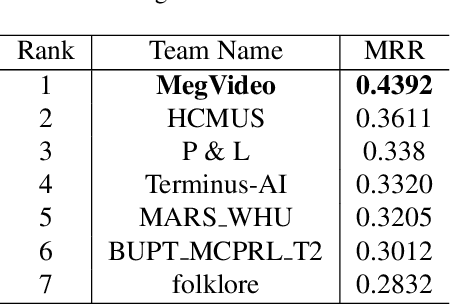
Natural language (NL) based vehicle retrieval aims to search specific vehicle given text description. Different from the image-based vehicle retrieval, NL-based vehicle retrieval requires considering not only vehicle appearance, but also surrounding environment and temporal relations. In this paper, we propose a Symmetric Network with Spatial Relationship Modeling (SSM) method for NL-based vehicle retrieval. Specifically, we design a symmetric network to learn the unified cross-modal representations between text descriptions and vehicle images, where vehicle appearance details and vehicle trajectory global information are preserved. Besides, to make better use of location information, we propose a spatial relationship modeling methods to take surrounding environment and mutual relationship between vehicles into consideration. The qualitative and quantitative experiments verify the effectiveness of the proposed method. We achieve 43.92% MRR accuracy on the test set of the 6th AI City Challenge on natural language-based vehicle retrieval track, yielding the 1st place among all valid submissions on the public leaderboard. The code is available at https://github.com/hbchen121/AICITY2022_Track2_SSM.
* 8 pages, 3 figures, publised to CVPRW
Elastic Net based Feature Ranking and Selection
Dec 30, 2020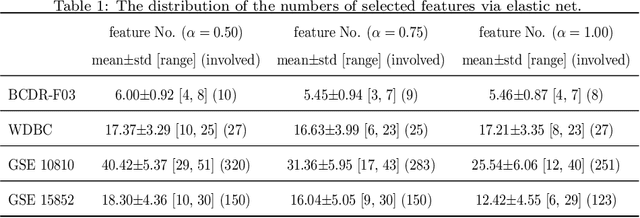
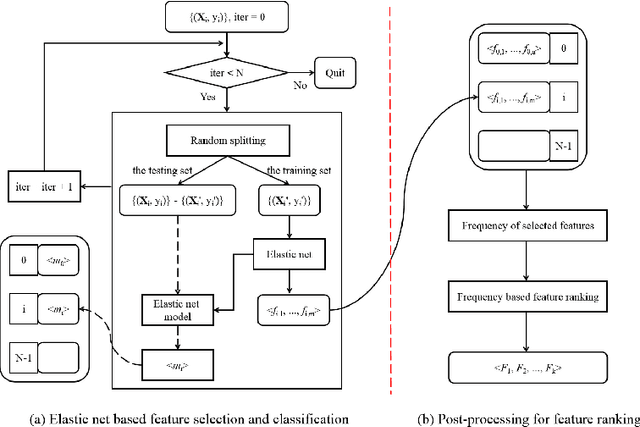
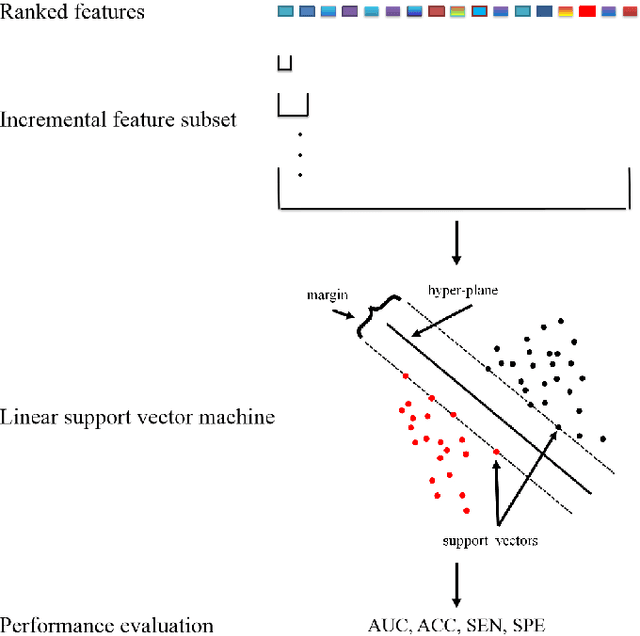

Feature selection is important in data representation and intelligent diagnosis. Elastic net is one of the most widely used feature selectors. However, the features selected are dependant on the training data, and their weights dedicated for regularized regression are irrelevant to their importance if used for feature ranking, that degrades the model interpretability and extension. In this study, an intuitive idea is put at the end of multiple times of data splitting and elastic net based feature selection. It concerns the frequency of selected features and uses the frequency as an indicator of feature importance. After features are sorted according to their frequency, linear support vector machine performs the classification in an incremental manner. At last, a compact subset of discriminative features is selected by comparing the prediction performance. Experimental results on breast cancer data sets (BCDR-F03, WDBC, GSE 10810, and GSE 15852) suggest that the proposed framework achieves competitive or superior performance to elastic net and with consistent selection of fewer features. How to further enhance its consistency on high-dimension small-sample-size data sets should be paid more attention in our future work. The proposed framework is accessible online (https://github.com/NicoYuCN/elasticnetFR).