 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBVINet: Unlocking Blind Video Inpainting with Zero Annotations
Feb 03, 2025



Video inpainting aims to fill in corrupted regions of the video with plausible contents. Existing methods generally assume that the locations of corrupted regions are known, focusing primarily on the "how to inpaint". This reliance necessitates manual annotation of the corrupted regions using binary masks to indicate "whereto inpaint". However, the annotation of these masks is labor-intensive and expensive, limiting the practicality of current methods. In this paper, we expect to relax this assumption by defining a new blind video inpainting setting, enabling the networks to learn the mapping from corrupted video to inpainted result directly, eliminating the need of corrupted region annotations. Specifically, we propose an end-to-end blind video inpainting network (BVINet) to address both "where to inpaint" and "how to inpaint" simultaneously. On the one hand, BVINet can predict the masks of corrupted regions by detecting semantic-discontinuous regions of the frame and utilizing temporal consistency prior of the video. On the other hand, the predicted masks are incorporated into the BVINet, allowing it to capture valid context information from uncorrupted regions to fill in corrupted ones. Besides, we introduce a consistency loss to regularize the training parameters of BVINet. In this way, mask prediction and video completion mutually constrain each other, thereby maximizing the overall performance of the trained model. Furthermore, we customize a dataset consisting of synthetic corrupted videos, real-world corrupted videos, and their corresponding completed videos. This dataset serves as a valuable resource for advancing blind video inpainting research. Extensive experimental results demonstrate the effectiveness and superiority of our method.
Prompt-Aware Controllable Shadow Removal
Jan 25, 2025



Shadow removal aims to restore the image content in shadowed regions. While deep learning-based methods have shown promising results, they still face key challenges: 1) uncontrolled removal of all shadows, or 2) controllable removal but heavily relies on precise shadow region masks.To address these issues, we introduce a novel paradigm: prompt-aware controllable shadow removal. Unlike existing approaches, our paradigm allows for targeted shadow removal from specific subjects based on user prompts (e.g., dots, lines, or subject masks). This approach eliminates the need for shadow annotations and offers flexible, user-controlled shadow removal.Specifically, we propose an end-to-end learnable model, the \emph{\textbf{P}}rompt-\emph{\textbf{A}}ware \emph{\textbf{C}}ntrollable \emph{\textbf{S}}hadow \emph{\textbf{R}}emoval \emph{\textbf{Net}}work (PACSRNet). PACSRNet consists of two key modules: a prompt-aware module that generates shadow masks for the specified subject based on the user prompt, and a shadow removal module that uses the shadow prior from the first module to restore the content in the shadowed regions.Additionally, we enhance the shadow removal module by incorporating feature information from the prompt-aware module through a linear operation, providing prompt-guided support for shadow removal.Recognizing that existing shadow removal datasets lack diverse user prompts, we contribute a new dataset specifically designed for prompt-based controllable shadow removal.Extensive experimental results demonstrate the effectiveness and superiority of PACSRNet.
Brant-X: A Unified Physiological Signal Alignment Framework
Aug 28, 2024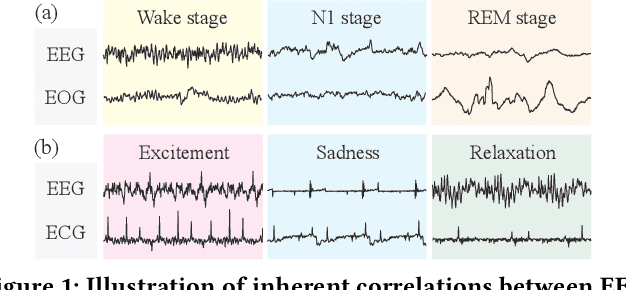
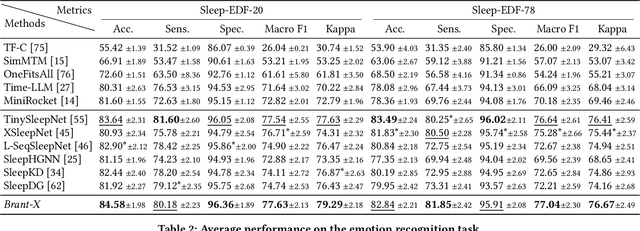

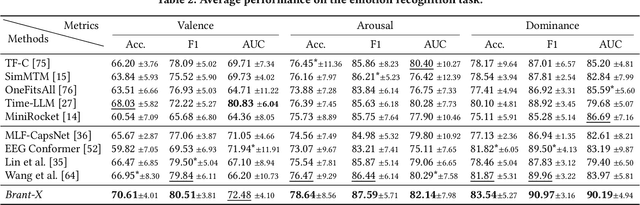
Physiological signals serve as indispensable clues for understanding various physiological states of human bodies. Most existing works have focused on a single type of physiological signals for a range of application scenarios. However, as the body is a holistic biological system, the inherent interconnection among various physiological data should not be neglected. In particular, given the brain's role as the control center for vital activities, electroencephalogram (EEG) exhibits significant correlations with other physiological signals. Therefore, the correlation between EEG and other physiological signals holds potential to improve performance in various scenarios. Nevertheless, achieving this goal is still constrained by several challenges: the scarcity of simultaneously collected physiological data, the differences in correlations between various signals, and the correlation differences between various tasks. To address these issues, we propose a unified physiological signal alignment framework, Brant-X, to model the correlation between EEG and other signals. Our approach (1) employs the EEG foundation model to data-efficiently transfer the rich knowledge in EEG to other physiological signals, and (2) introduces the two-level alignment to fully align the semantics of EEG and other signals from different semantic scales. In the experiments, Brant-X achieves state-of-the-art performance compared with task-agnostic and task-specific baselines on various downstream tasks in diverse scenarios, including sleep stage classification, emotion recognition, freezing of gaits detection, and eye movement communication. Moreover, the analysis on the arrhythmia detection task and the visualization in case study further illustrate the effectiveness of Brant-X in the knowledge transfer from EEG to other physiological signals. The model's homepage is at https://github.com/zjunet/Brant-X/.
* Accepted by SIGKDD 2024