 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Responsible LLMs: Inherent Risk, Malicious Use, and Mitigation Strategy
Jan 16, 2025



While large language models (LLMs) present significant potential for supporting numerous real-world applications and delivering positive social impacts, they still face significant challenges in terms of the inherent risk of privacy leakage, hallucinated outputs, and value misalignment, and can be maliciously used for generating toxic content and unethical purposes after been jailbroken. Therefore, in this survey, we present a comprehensive review of recent advancements aimed at mitigating these issues, organized across the four phases of LLM development and usage: data collecting and pre-training, fine-tuning and alignment, prompting and reasoning, and post-processing and auditing. We elaborate on the recent advances for enhancing the performance of LLMs in terms of privacy protection, hallucination reduction, value alignment, toxicity elimination, and jailbreak defenses. In contrast to previous surveys that focus on a single dimension of responsible LLMs, this survey presents a unified framework that encompasses these diverse dimensions, providing a comprehensive view of enhancing LLMs to better serve real-world applications.
Con4m: Context-aware Consistency Learning Framework for Segmented Time Series Classification
Jul 31, 2024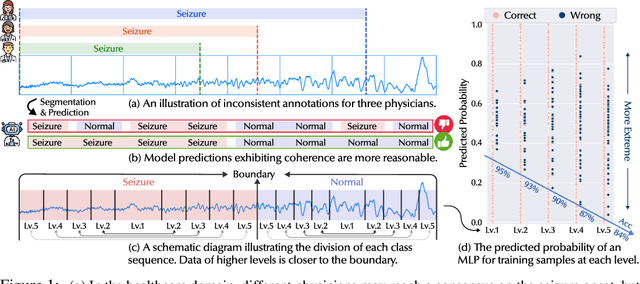

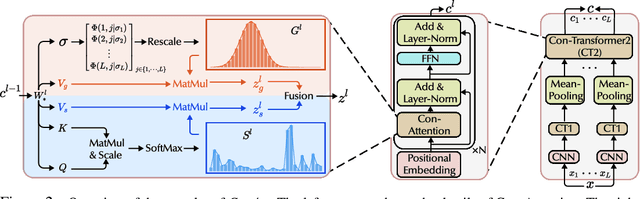
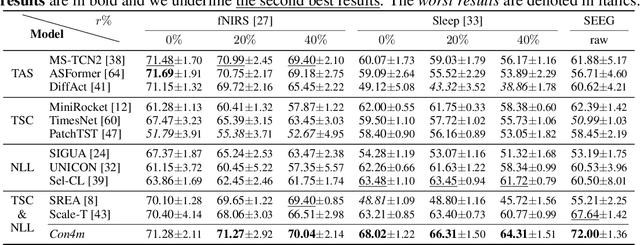
Time Series Classification (TSC) encompasses two settings: classifying entire sequences or classifying segmented subsequences. The raw time series for segmented TSC usually contain Multiple classes with Varying Duration of each class (MVD). Therefore, the characteristics of MVD pose unique challenges for segmented TSC, yet have been largely overlooked by existing works. Specifically, there exists a natural temporal dependency between consecutive instances (segments) to be classified within MVD. However, mainstream TSC models rely on the assumption of independent and identically distributed (i.i.d.), focusing on independently modeling each segment. Additionally, annotators with varying expertise may provide inconsistent boundary labels, leading to unstable performance of noise-free TSC models. To address these challenges, we first formally demonstrate that valuable contextual information enhances the discriminative power of classification instances. Leveraging the contextual priors of MVD at both the data and label levels, we propose a novel consistency learning framework Con4m, which effectively utilizes contextual information more conducive to discriminating consecutive segments in segmented TSC tasks, while harmonizing inconsistent boundary labels for training. Extensive experiments across multiple datasets validate the effectiveness of Con4m in handling segmented TSC tasks on MVD.
Practitioners Versus Users: A Value-Sensitive Evaluation of Current Industrial Recommender System Design
Aug 08, 2022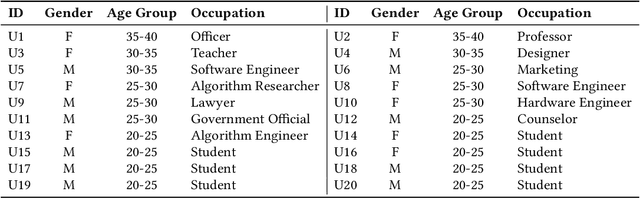
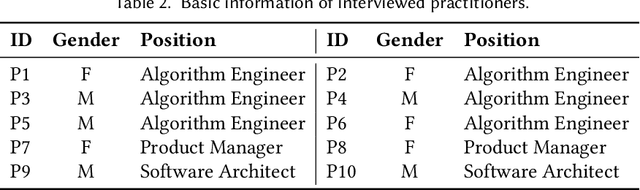

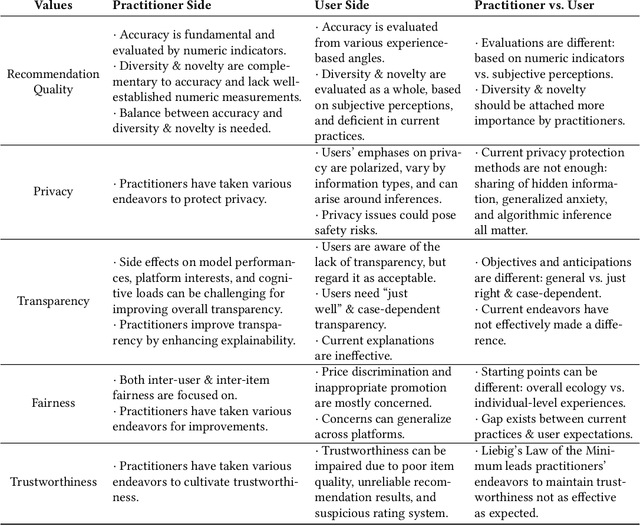
Recommender systems are playing an increasingly important role in alleviating information overload and supporting users' various needs, e.g., consumption, socialization, and entertainment. However, limited research focuses on how values should be extensively considered in industrial deployments of recommender systems, the ignorance of which can be problematic. To fill this gap, in this paper, we adopt Value Sensitive Design to comprehensively explore how practitioners and users recognize different values of current industrial recommender systems. Based on conceptual and empirical investigations, we focus on five values: recommendation quality, privacy, transparency, fairness, and trustworthiness. We further conduct in-depth qualitative interviews with 20 users and 10 practitioners to delve into their opinions towards these values. Our results reveal the existence and sources of tensions between practitioners and users in terms of value interpretation, evaluation, and practice, which provide novel implications for designing more human-centric and value-sensitive recommender systems.