 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCon4m: Context-aware Consistency Learning Framework for Segmented Time Series Classification
Jul 31, 2024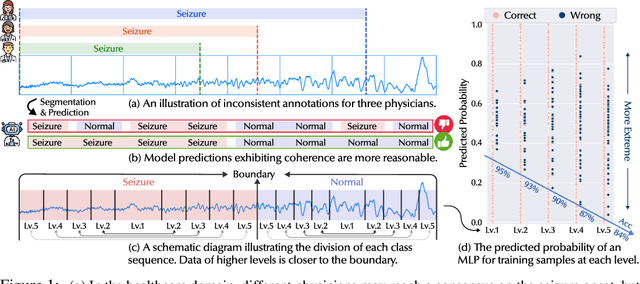

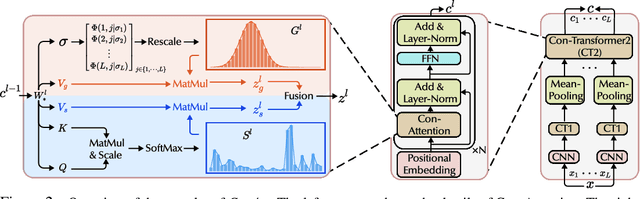
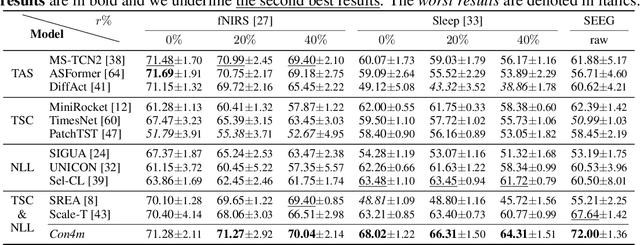
Time Series Classification (TSC) encompasses two settings: classifying entire sequences or classifying segmented subsequences. The raw time series for segmented TSC usually contain Multiple classes with Varying Duration of each class (MVD). Therefore, the characteristics of MVD pose unique challenges for segmented TSC, yet have been largely overlooked by existing works. Specifically, there exists a natural temporal dependency between consecutive instances (segments) to be classified within MVD. However, mainstream TSC models rely on the assumption of independent and identically distributed (i.i.d.), focusing on independently modeling each segment. Additionally, annotators with varying expertise may provide inconsistent boundary labels, leading to unstable performance of noise-free TSC models. To address these challenges, we first formally demonstrate that valuable contextual information enhances the discriminative power of classification instances. Leveraging the contextual priors of MVD at both the data and label levels, we propose a novel consistency learning framework Con4m, which effectively utilizes contextual information more conducive to discriminating consecutive segments in segmented TSC tasks, while harmonizing inconsistent boundary labels for training. Extensive experiments across multiple datasets validate the effectiveness of Con4m in handling segmented TSC tasks on MVD.
Explicit Motion Handling and Interactive Prompting for Video Camouflaged Object Detection
Mar 04, 2024Camouflage poses challenges in distinguishing a static target, whereas any movement of the target can break this disguise. Existing video camouflaged object detection (VCOD) approaches take noisy motion estimation as input or model motion implicitly, restricting detection performance in complex dynamic scenes. In this paper, we propose a novel Explicit Motion handling and Interactive Prompting framework for VCOD, dubbed EMIP, which handles motion cues explicitly using a frozen pre-trained optical flow fundamental model. EMIP is characterized by a two-stream architecture for simultaneously conducting camouflaged segmentation and optical flow estimation. Interactions across the dual streams are realized in an interactive prompting way that is inspired by emerging visual prompt learning. Two learnable modules, i.e. the camouflaged feeder and motion collector, are designed to incorporate segmentation-to-motion and motion-to-segmentation prompts, respectively, and enhance outputs of the both streams. The prompt fed to the motion stream is learned by supervising optical flow in a self-supervised manner. Furthermore, we show that long-term historical information can also be incorporated as a prompt into EMIP and achieve more robust results with temporal consistency. Experimental results demonstrate that our EMIP achieves new state-of-the-art records on popular VCOD benchmarks. The code will be publicly available.
Local-Global Transformer Enhanced Unfolding Network for Pan-sharpening
Apr 28, 2023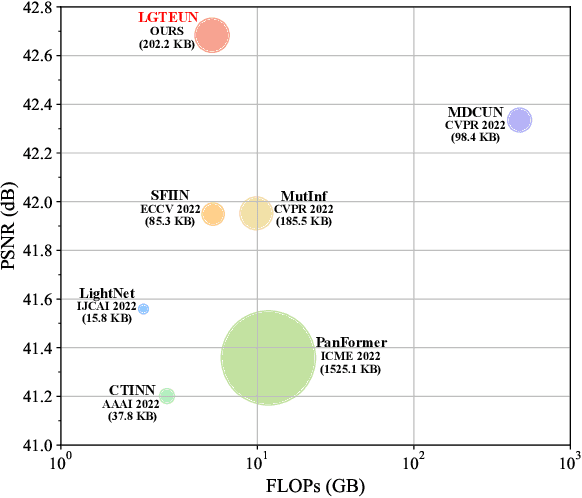

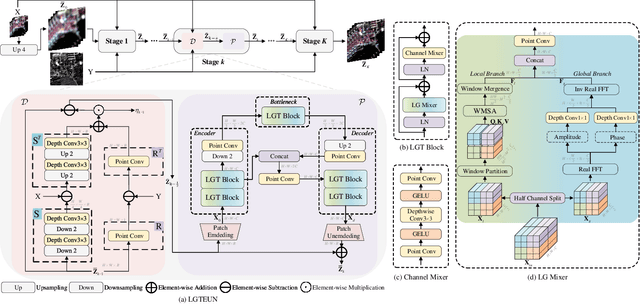

Pan-sharpening aims to increase the spatial resolution of the low-resolution multispectral (LrMS) image with the guidance of the corresponding panchromatic (PAN) image. Although deep learning (DL)-based pan-sharpening methods have achieved promising performance, most of them have a two-fold deficiency. For one thing, the universally adopted black box principle limits the model interpretability. For another thing, existing DL-based methods fail to efficiently capture local and global dependencies at the same time, inevitably limiting the overall performance. To address these mentioned issues, we first formulate the degradation process of the high-resolution multispectral (HrMS) image as a unified variational optimization problem, and alternately solve its data and prior subproblems by the designed iterative proximal gradient descent (PGD) algorithm. Moreover, we customize a Local-Global Transformer (LGT) to simultaneously model local and global dependencies, and further formulate an LGT-based prior module for image denoising. Besides the prior module, we also design a lightweight data module. Finally, by serially integrating the data and prior modules in each iterative stage, we unfold the iterative algorithm into a stage-wise unfolding network, Local-Global Transformer Enhanced Unfolding Network (LGTEUN), for the interpretable MS pan-sharpening. Comprehensive experimental results on three satellite data sets demonstrate the effectiveness and efficiency of LGTEUN compared with state-of-the-art (SOTA) methods. The source code is available at https://github.com/lms-07/LGTEUN.
Boosting Graph Search with Attention Network for Solving the General Orienteering Problem
Sep 10, 2021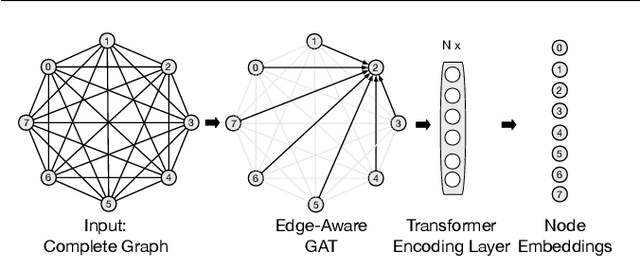
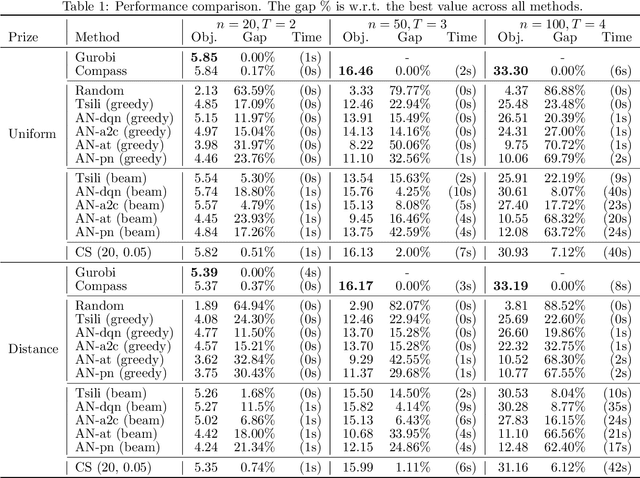
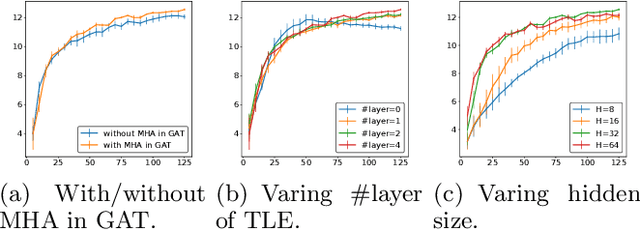
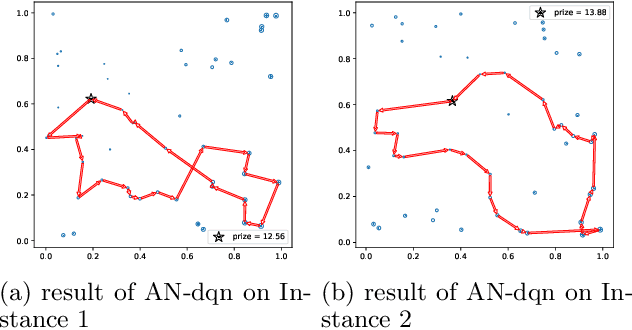
Recently, several studies have explored the use of neural network to solve different routing problems, which is an auspicious direction. These studies usually design an encoder-decoder based framework that uses encoder embeddings of nodes and the problem-specific context to produce node sequence(path), and further optimize the produced result on top by beam search. However, existing models can only support node coordinates as input, ignore the self-referential property of the studied routing problems, and lack the consideration about the low reliability in the initial stage of node selection, thus are hard to be applied in real-world. In this paper, we take the orienteering problem as an example to tackle these limitations. We propose a novel combination of a variant beam search algorithm and a learned heuristic for solving the general orienteering problem. We acquire the heuristic with an attention network that takes the distances among nodes as input, and learn it via a reinforcement learning framework. The empirical studies show that our method can surpass a wide range of baselines and achieve results close to the optimal or highly specialized approach. Also, our proposed framework can be easily applied to other routing problems. Our code is publicly available.