 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal-Global Transformer Enhanced Unfolding Network for Pan-sharpening
Apr 28, 2023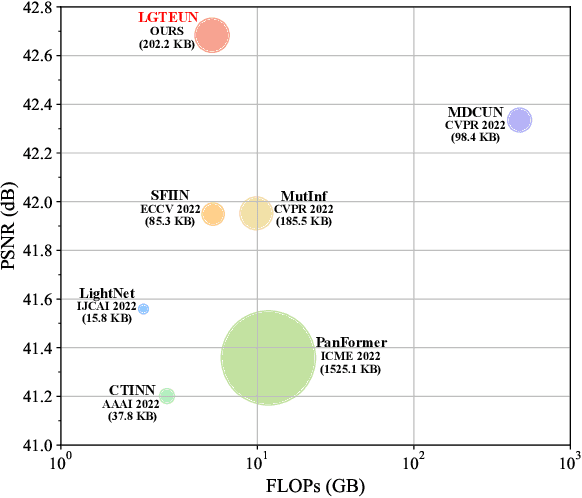

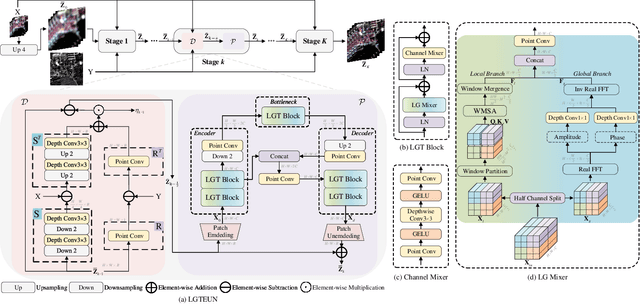

Pan-sharpening aims to increase the spatial resolution of the low-resolution multispectral (LrMS) image with the guidance of the corresponding panchromatic (PAN) image. Although deep learning (DL)-based pan-sharpening methods have achieved promising performance, most of them have a two-fold deficiency. For one thing, the universally adopted black box principle limits the model interpretability. For another thing, existing DL-based methods fail to efficiently capture local and global dependencies at the same time, inevitably limiting the overall performance. To address these mentioned issues, we first formulate the degradation process of the high-resolution multispectral (HrMS) image as a unified variational optimization problem, and alternately solve its data and prior subproblems by the designed iterative proximal gradient descent (PGD) algorithm. Moreover, we customize a Local-Global Transformer (LGT) to simultaneously model local and global dependencies, and further formulate an LGT-based prior module for image denoising. Besides the prior module, we also design a lightweight data module. Finally, by serially integrating the data and prior modules in each iterative stage, we unfold the iterative algorithm into a stage-wise unfolding network, Local-Global Transformer Enhanced Unfolding Network (LGTEUN), for the interpretable MS pan-sharpening. Comprehensive experimental results on three satellite data sets demonstrate the effectiveness and efficiency of LGTEUN compared with state-of-the-art (SOTA) methods. The source code is available at https://github.com/lms-07/LGTEUN.
Robust Ellipsoid Fitting Using Axial Distance and Combination
Apr 02, 2023



In random sample consensus (RANSAC), the problem of ellipsoid fitting can be formulated as a problem of minimization of point-to-model distance, which is realized by maximizing model score. Hence, the performance of ellipsoid fitting is affected by distance metric. In this paper, we proposed a novel distance metric called the axial distance, which is converted from the algebraic distance by introducing a scaling factor to solve nongeometric problems of the algebraic distance. There is complementarity between the axial distance and Sampson distance because their combination is a stricter metric when calculating the model score of sample consensus and the weight of the weighted least squares (WLS) fitting. Subsequently, a novel sample-consensus-based ellipsoid fitting method is proposed by using the combination between the axial distance and Sampson distance (CAS). We compare the proposed method with several representative fitting methods through experiments on synthetic and real datasets. The results show that the proposed method has a higher robustness against outliers, consistently high accuracy, and a speed close to that of the method based on sample consensus.
DRNet: Decomposition and Reconstruction Network for Remote Physiological Measurement
Jun 20, 2022
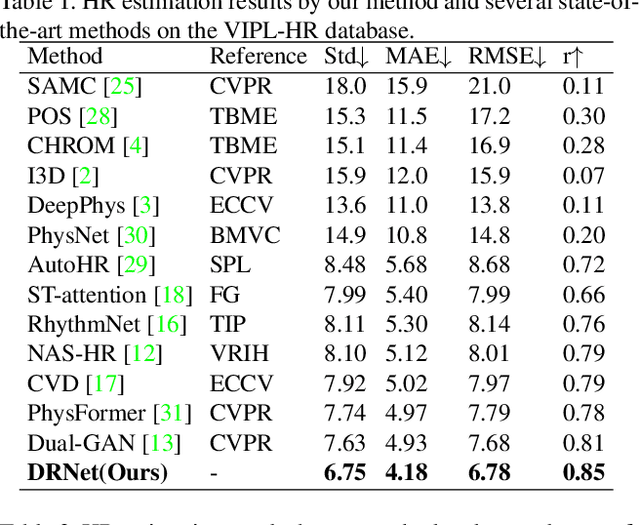
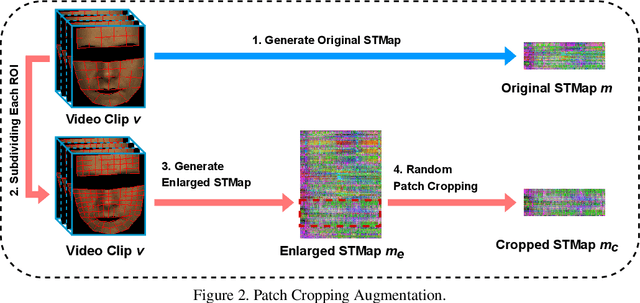
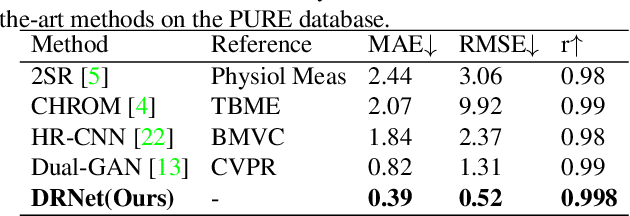
Remote photoplethysmography (rPPG) based physiological measurement has great application values in affective computing, non-contact health monitoring, telehealth monitoring, etc, which has become increasingly important especially during the COVID-19 pandemic. Existing methods are generally divided into two groups. The first focuses on mining the subtle blood volume pulse (BVP) signals from face videos, but seldom explicitly models the noises that dominate face video content. They are susceptible to the noises and may suffer from poor generalization ability in unseen scenarios. The second focuses on modeling noisy data directly, resulting in suboptimal performance due to the lack of regularity of these severe random noises. In this paper, we propose a Decomposition and Reconstruction Network (DRNet) focusing on the modeling of physiological features rather than noisy data. A novel cycle loss is proposed to constrain the periodicity of physiological information. Besides, a plug-and-play Spatial Attention Block (SAB) is proposed to enhance features along with the spatial location information. Furthermore, an efficient Patch Cropping (PC) augmentation strategy is proposed to synthesize augmented samples with different noise and features. Extensive experiments on different public datasets as well as the cross-database testing demonstrate the effectiveness of our approach.