 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARLArena: A Unified Framework for Stable Agentic Reinforcement Learning
Feb 25, 2026Agentic reinforcement learning (ARL) has rapidly gained attention as a promising paradigm for training agents to solve complex, multi-step interactive tasks. Despite encouraging early results, ARL remains highly unstable, often leading to training collapse. This instability limits scalability to larger environments and longer interaction horizons, and constrains systematic exploration of algorithmic design choices. In this paper, we first propose ARLArena, a stable training recipe and systematic analysis framework that examines training stability in a controlled and reproducible setting. ARLArena first constructs a clean and standardized testbed. Then, we decompose policy gradient into four core design dimensions and assess the performance and stability of each dimension. Through this fine-grained analysis, we distill a unified perspective on ARL and propose SAMPO, a stable agentic policy optimization method designed to mitigate the dominant sources of instability in ARL. Empirically, SAMPO achieves consistently stable training and strong performance across diverse agentic tasks. Overall, this study provides a unifying policy gradient perspective for ARL and offers practical guidance for building stable and reproducible LLM-based agent training pipelines.
Simulator and Experience Enhanced Diffusion Model for Comprehensive ECG Generation
Nov 13, 2025Cardiovascular disease (CVD) is a leading cause of mortality worldwide. Electrocardiograms (ECGs) are the most widely used non-invasive tool for cardiac assessment, yet large, well-annotated ECG corpora are scarce due to cost, privacy, and workflow constraints. Generating ECGs can be beneficial for the mechanistic understanding of cardiac electrical activity, enable the construction of large, heterogeneous, and unbiased datasets, and facilitate privacy-preserving data sharing. Generating realistic ECG signals from clinical context is important yet underexplored. Recent work has leveraged diffusion models for text-to-ECG generation, but two challenges remain: (i) existing methods often overlook the physiological simulator knowledge of cardiac activity; and (ii) they ignore broader, experience-based clinical knowledge grounded in real-world practice. To address these gaps, we propose SE-Diff, a novel physiological simulator and experience enhanced diffusion model for comprehensive ECG generation. SE-Diff integrates a lightweight ordinary differential equation (ODE)-based ECG simulator into the diffusion process via a beat decoder and simulator-consistent constraints, injecting mechanistic priors that promote physiologically plausible waveforms. In parallel, we design an LLM-powered experience retrieval-augmented strategy to inject clinical knowledge, providing more guidance for ECG generation. Extensive experiments on real-world ECG datasets demonstrate that SE-Diff improves both signal fidelity and text-ECG semantic alignment over baselines, proving its superiority for text-to-ECG generation. We further show that the simulator-based and experience-based knowledge also benefit downstream ECG classification.
Conditional Neural ODE for Longitudinal Parkinson's Disease Progression Forecasting
Nov 06, 2025Parkinson's disease (PD) shows heterogeneous, evolving brain-morphometry patterns. Modeling these longitudinal trajectories enables mechanistic insight, treatment development, and individualized 'digital-twin' forecasting. However, existing methods usually adopt recurrent neural networks and transformer architectures, which rely on discrete, regularly sampled data while struggling to handle irregular and sparse magnetic resonance imaging (MRI) in PD cohorts. Moreover, these methods have difficulty capturing individual heterogeneity including variations in disease onset, progression rate, and symptom severity, which is a hallmark of PD. To address these challenges, we propose CNODE (Conditional Neural ODE), a novel framework for continuous, individualized PD progression forecasting. The core of CNODE is to model morphological brain changes as continuous temporal processes using a neural ODE model. In addition, we jointly learn patient-specific initial time and progress speed to align individual trajectories into a shared progression trajectory. We validate CNODE on the Parkinson's Progression Markers Initiative (PPMI) dataset. Experimental results show that our method outperforms state-of-the-art baselines in forecasting longitudinal PD progression.
FD-Bench: A Modular and Fair Benchmark for Data-driven Fluid Simulation
May 25, 2025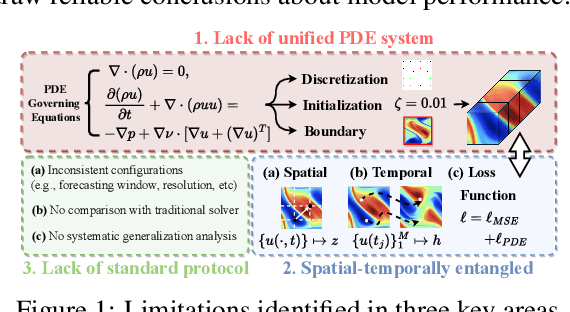

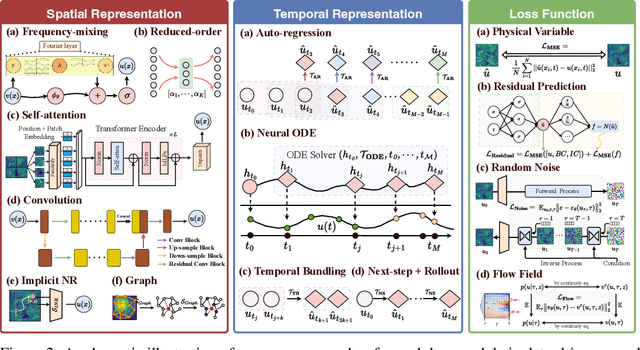
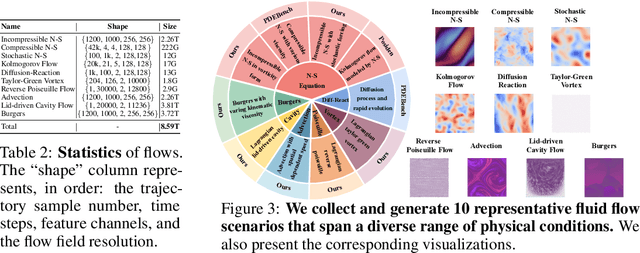
Data-driven modeling of fluid dynamics has advanced rapidly with neural PDE solvers, yet a fair and strong benchmark remains fragmented due to the absence of unified PDE datasets and standardized evaluation protocols. Although architectural innovations are abundant, fair assessment is further impeded by the lack of clear disentanglement between spatial, temporal and loss modules. In this paper, we introduce FD-Bench, the first fair, modular, comprehensive and reproducible benchmark for data-driven fluid simulation. FD-Bench systematically evaluates 85 baseline models across 10 representative flow scenarios under a unified experimental setup. It provides four key contributions: (1) a modular design enabling fair comparisons across spatial, temporal, and loss function modules; (2) the first systematic framework for direct comparison with traditional numerical solvers; (3) fine-grained generalization analysis across resolutions, initial conditions, and temporal windows; and (4) a user-friendly, extensible codebase to support future research. Through rigorous empirical studies, FD-Bench establishes the most comprehensive leaderboard to date, resolving long-standing issues in reproducibility and comparability, and laying a foundation for robust evaluation of future data-driven fluid models. The code is open-sourced at https://anonymous.4open.science/r/FD-Bench-15BC.
Concept-Reversed Winograd Schema Challenge: Evaluating and Improving Robust Reasoning in Large Language Models via Abstraction
Oct 15, 2024



While Large Language Models (LLMs) have showcased remarkable proficiency in reasoning, there is still a concern about hallucinations and unreliable reasoning issues due to semantic associations and superficial logical chains. To evaluate the extent to which LLMs perform robust reasoning instead of relying on superficial logical chains, we propose a new evaluation dataset, the Concept-Reversed Winograd Schema Challenge (CR-WSC), based on the famous Winograd Schema Challenge (WSC) dataset. By simply reversing the concepts to those that are more associated with the wrong answer, we find that the performance of LLMs drops significantly despite the rationale of reasoning remaining the same. Furthermore, we propose Abstraction-of-Thought (AoT), a novel prompt method for recovering adversarial cases to normal cases using conceptual abstraction to improve LLMs' robustness and consistency in reasoning, as demonstrated by experiments on CR-WSC.
Exploring Correlations of Self-supervised Tasks for Graphs
May 07, 2024



Graph self-supervised learning has sparked a research surge in training informative representations without accessing any labeled data. However, our understanding of graph self-supervised learning remains limited, and the inherent relationships between various self-supervised tasks are still unexplored. Our paper aims to provide a fresh understanding of graph self-supervised learning based on task correlations. Specifically, we evaluate the performance of the representations trained by one specific task on other tasks and define correlation values to quantify task correlations. Through this process, we unveil the task correlations between various self-supervised tasks and can measure their expressive capabilities, which are closely related to downstream performance. By analyzing the correlation values between tasks across various datasets, we reveal the complexity of task correlations and the limitations of existing multi-task learning methods. To obtain more capable representations, we propose Graph Task Correlation Modeling (GraphTCM) to illustrate the task correlations and utilize it to enhance graph self-supervised training. The experimental results indicate that our method significantly outperforms existing methods across various downstream tasks.
BrainODE: Dynamic Brain Signal Analysis via Graph-Aided Neural Ordinary Differential Equations
Apr 30, 2024



Brain network analysis is vital for understanding the neural interactions regarding brain structures and functions, and identifying potential biomarkers for clinical phenotypes. However, widely used brain signals such as Blood Oxygen Level Dependent (BOLD) time series generated from functional Magnetic Resonance Imaging (fMRI) often manifest three challenges: (1) missing values, (2) irregular samples, and (3) sampling misalignment, due to instrumental limitations, impacting downstream brain network analysis and clinical outcome predictions. In this work, we propose a novel model called BrainODE to achieve continuous modeling of dynamic brain signals using Ordinary Differential Equations (ODE). By learning latent initial values and neural ODE functions from irregular time series, BrainODE effectively reconstructs brain signals at any time point, mitigating the aforementioned three data challenges of brain signals altogether. Comprehensive experimental results on real-world neuroimaging datasets demonstrate the superior performance of BrainODE and its capability of addressing the three data challenges.
Can GNN be Good Adapter for LLMs?
Feb 20, 2024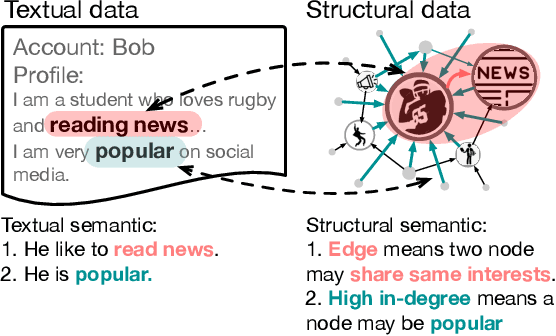
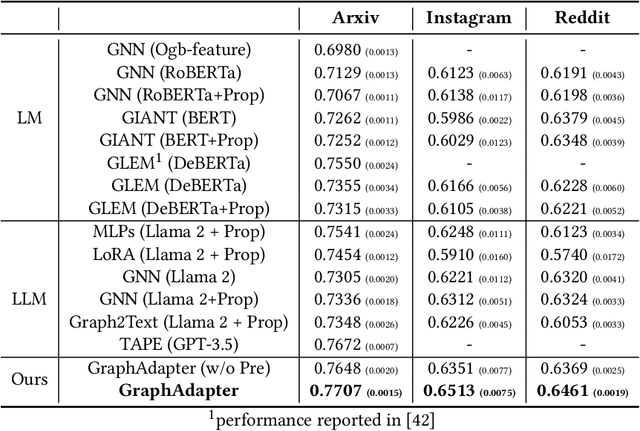
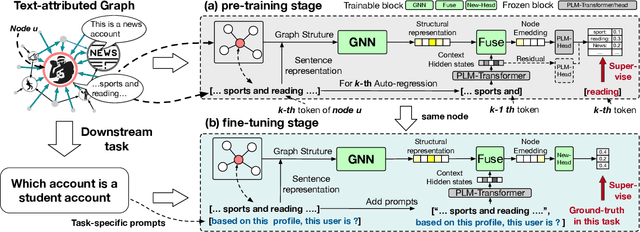

Recently, large language models (LLMs) have demonstrated superior capabilities in understanding and zero-shot learning on textual data, promising significant advances for many text-related domains. In the graph domain, various real-world scenarios also involve textual data, where tasks and node features can be described by text. These text-attributed graphs (TAGs) have broad applications in social media, recommendation systems, etc. Thus, this paper explores how to utilize LLMs to model TAGs. Previous methods for TAG modeling are based on million-scale LMs. When scaled up to billion-scale LLMs, they face huge challenges in computational costs. Additionally, they also ignore the zero-shot inference capabilities of LLMs. Therefore, we propose GraphAdapter, which uses a graph neural network (GNN) as an efficient adapter in collaboration with LLMs to tackle TAGs. In terms of efficiency, the GNN adapter introduces only a few trainable parameters and can be trained with low computation costs. The entire framework is trained using auto-regression on node text (next token prediction). Once trained, GraphAdapter can be seamlessly fine-tuned with task-specific prompts for various downstream tasks. Through extensive experiments across multiple real-world TAGs, GraphAdapter based on Llama 2 gains an average improvement of approximately 5\% in terms of node classification. Furthermore, GraphAdapter can also adapt to other language models, including RoBERTa, GPT-2. The promising results demonstrate that GNNs can serve as effective adapters for LLMs in TAG modeling.
GraphLLM: Boosting Graph Reasoning Ability of Large Language Model
Oct 09, 2023



The advancement of Large Language Models (LLMs) has remarkably pushed the boundaries towards artificial general intelligence (AGI), with their exceptional ability on understanding diverse types of information, including but not limited to images and audio. Despite this progress, a critical gap remains in empowering LLMs to proficiently understand and reason on graph data. Recent studies underscore LLMs' underwhelming performance on fundamental graph reasoning tasks. In this paper, we endeavor to unearth the obstacles that impede LLMs in graph reasoning, pinpointing the common practice of converting graphs into natural language descriptions (Graph2Text) as a fundamental bottleneck. To overcome this impediment, we introduce GraphLLM, a pioneering end-to-end approach that synergistically integrates graph learning models with LLMs. This synergy equips LLMs with the ability to proficiently interpret and reason on graph data, harnessing the superior expressive power of graph learning models. Our empirical evaluations across four fundamental graph reasoning tasks validate the effectiveness of GraphLLM. The results exhibit a substantial average accuracy enhancement of 54.44%, alongside a noteworthy context reduction of 96.45% across various graph reasoning tasks.