 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptTSS: A Prompting-Based Approach for Interactive Multi-Granularity Time Series Segmentation
Jun 12, 2025Multivariate time series data, collected across various fields such as manufacturing and wearable technology, exhibit states at multiple levels of granularity, from coarse-grained system behaviors to fine-grained, detailed events. Effectively segmenting and integrating states across these different granularities is crucial for tasks like predictive maintenance and performance optimization. However, existing time series segmentation methods face two key challenges: (1) the inability to handle multiple levels of granularity within a unified model, and (2) limited adaptability to new, evolving patterns in dynamic environments. To address these challenges, we propose PromptTSS, a novel framework for time series segmentation with multi-granularity states. PromptTSS uses a unified model with a prompting mechanism that leverages label and boundary information to guide segmentation, capturing both coarse- and fine-grained patterns while adapting dynamically to unseen patterns. Experiments show PromptTSS improves accuracy by 24.49% in multi-granularity segmentation, 17.88% in single-granularity segmentation, and up to 599.24% in transfer learning, demonstrating its adaptability to hierarchical states and evolving time series dynamics.
Time-IMM: A Dataset and Benchmark for Irregular Multimodal Multivariate Time Series
Jun 12, 2025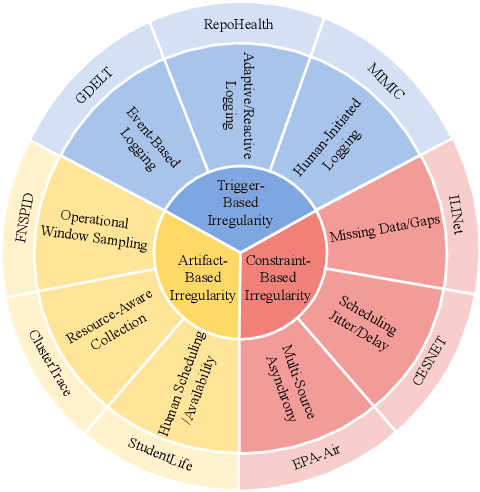
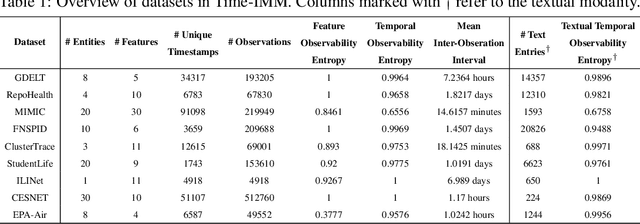
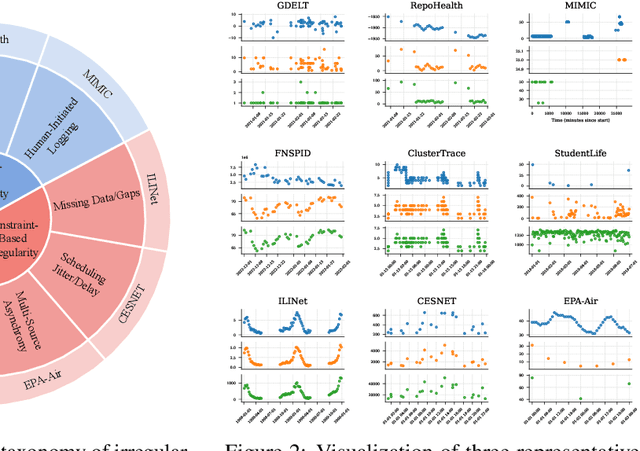
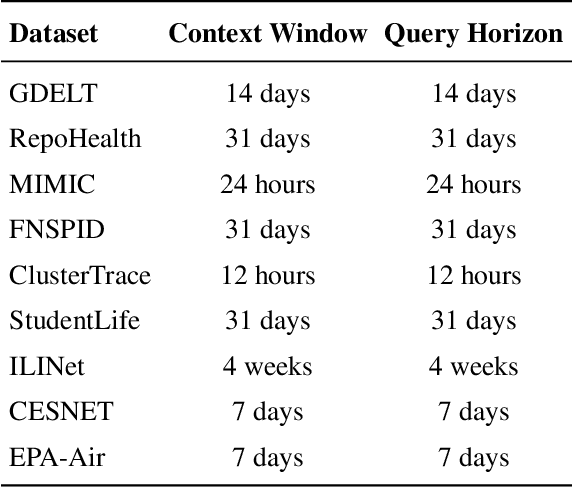
Time series data in real-world applications such as healthcare, climate modeling, and finance are often irregular, multimodal, and messy, with varying sampling rates, asynchronous modalities, and pervasive missingness. However, existing benchmarks typically assume clean, regularly sampled, unimodal data, creating a significant gap between research and real-world deployment. We introduce Time-IMM, a dataset specifically designed to capture cause-driven irregularity in multimodal multivariate time series. Time-IMM represents nine distinct types of time series irregularity, categorized into trigger-based, constraint-based, and artifact-based mechanisms. Complementing the dataset, we introduce IMM-TSF, a benchmark library for forecasting on irregular multimodal time series, enabling asynchronous integration and realistic evaluation. IMM-TSF includes specialized fusion modules, including a timestamp-to-text fusion module and a multimodality fusion module, which support both recency-aware averaging and attention-based integration strategies. Empirical results demonstrate that explicitly modeling multimodality on irregular time series data leads to substantial gains in forecasting performance. Time-IMM and IMM-TSF provide a foundation for advancing time series analysis under real-world conditions. The dataset is publicly available at https://www.kaggle.com/datasets/blacksnail789521/time-imm/data, and the benchmark library can be accessed at https://anonymous.4open.science/r/IMMTSF_NeurIPS2025.
FD-Bench: A Modular and Fair Benchmark for Data-driven Fluid Simulation
May 25, 2025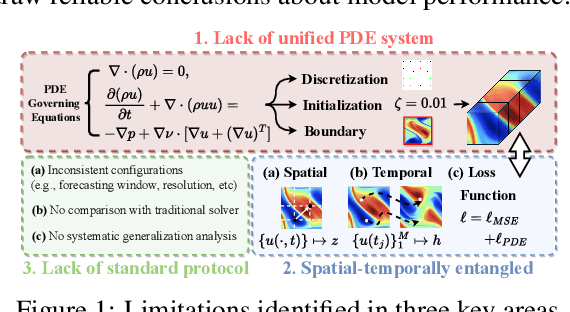

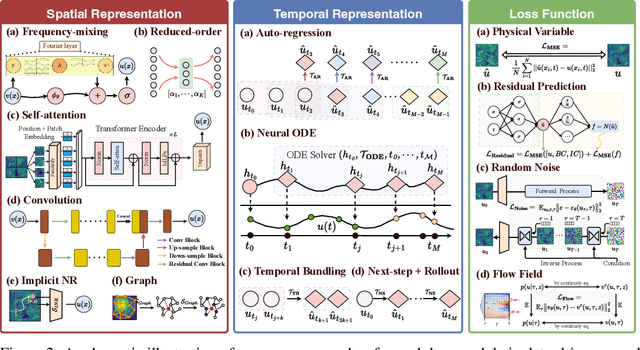
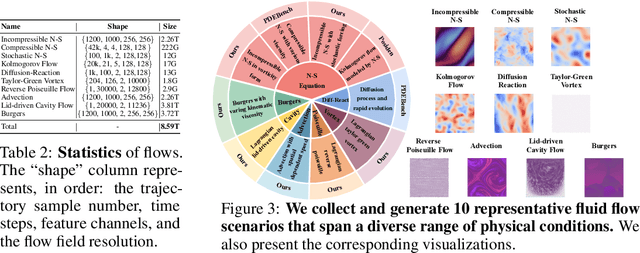
Data-driven modeling of fluid dynamics has advanced rapidly with neural PDE solvers, yet a fair and strong benchmark remains fragmented due to the absence of unified PDE datasets and standardized evaluation protocols. Although architectural innovations are abundant, fair assessment is further impeded by the lack of clear disentanglement between spatial, temporal and loss modules. In this paper, we introduce FD-Bench, the first fair, modular, comprehensive and reproducible benchmark for data-driven fluid simulation. FD-Bench systematically evaluates 85 baseline models across 10 representative flow scenarios under a unified experimental setup. It provides four key contributions: (1) a modular design enabling fair comparisons across spatial, temporal, and loss function modules; (2) the first systematic framework for direct comparison with traditional numerical solvers; (3) fine-grained generalization analysis across resolutions, initial conditions, and temporal windows; and (4) a user-friendly, extensible codebase to support future research. Through rigorous empirical studies, FD-Bench establishes the most comprehensive leaderboard to date, resolving long-standing issues in reproducibility and comparability, and laying a foundation for robust evaluation of future data-driven fluid models. The code is open-sourced at https://anonymous.4open.science/r/FD-Bench-15BC.
Text2Freq: Learning Series Patterns from Text via Frequency Domain
Nov 01, 2024
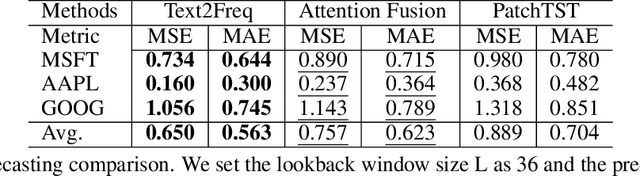


Traditional time series forecasting models mainly rely on historical numeric values to predict future outcomes.While these models have shown promising results, they often overlook the rich information available in other modalities, such as textual descriptions of special events, which can provide crucial insights into future dynamics.However, research that jointly incorporates text in time series forecasting remains relatively underexplored compared to other cross-modality work. Additionally, the modality gap between time series data and textual information poses a challenge for multimodal learning. To address this task, we propose Text2Freq, a cross-modality model that integrates text and time series data via the frequency domain. Specifically, our approach aligns textual information to the low-frequency components of time series data, establishing more effective and interpretable alignments between these two modalities. Our experiments on paired datasets of real-world stock prices and synthetic texts show that Text2Freq achieves state-of-the-art performance, with its adaptable architecture encouraging future research in this field.
Self-Supervised Learning of Disentangled Representations for Multivariate Time-Series
Oct 16, 2024


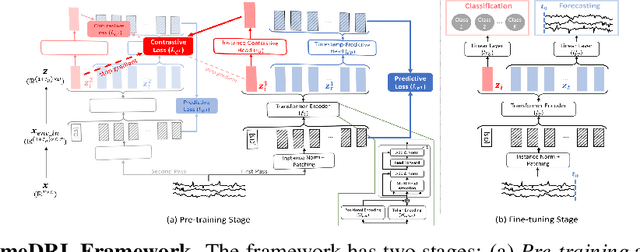
Multivariate time-series data in fields like healthcare and industry are informative but challenging due to high dimensionality and lack of labels. Recent self-supervised learning methods excel in learning rich representations without labels but struggle with disentangled embeddings and inductive bias issues like transformation-invariance. To address these challenges, we introduce TimeDRL, a framework for multivariate time-series representation learning with dual-level disentangled embeddings. TimeDRL features: (i) disentangled timestamp-level and instance-level embeddings using a [CLS] token strategy; (ii) timestamp-predictive and instance-contrastive tasks for representation learning; and (iii) avoidance of augmentation methods to eliminate inductive biases. Experiments on forecasting and classification datasets show TimeDRL outperforms existing methods, with further validation in semi-supervised settings with limited labeled data.
COKE: Causal Discovery with Chronological Order and Expert Knowledge in High Proportion of Missing Manufacturing Data
Jul 17, 2024Understanding causal relationships between machines is crucial for fault diagnosis and optimization in manufacturing processes. Real-world datasets frequently exhibit up to 90% missing data and high dimensionality from hundreds of sensors. These datasets also include domain-specific expert knowledge and chronological order information, reflecting the recording order across different machines, which is pivotal for discerning causal relationships within the manufacturing data. However, previous methods for handling missing data in scenarios akin to real-world conditions have not been able to effectively utilize expert knowledge. Conversely, prior methods that can incorporate expert knowledge struggle with datasets that exhibit missing values. Therefore, we propose COKE to construct causal graphs in manufacturing datasets by leveraging expert knowledge and chronological order among sensors without imputing missing data. Utilizing the characteristics of the recipe, we maximize the use of samples with missing values, derive embeddings from intersections with an initial graph that incorporates expert knowledge and chronological order, and create a sensor ordering graph. The graph-generating process has been optimized by an actor-critic architecture to obtain a final graph that has a maximum reward. Experimental evaluations in diverse settings of sensor quantities and missing proportions demonstrate that our approach compared with the benchmark methods shows an average improvement of 39.9% in the F1-score. Moreover, the F1-score improvement can reach 62.6% when considering the configuration similar to real-world datasets, and 85.0% in real-world semiconductor datasets. The source code is available at https://github.com/OuTingYun/COKE.
Root Cause Analysis In Microservice Using Neural Granger Causal Discovery
Feb 02, 2024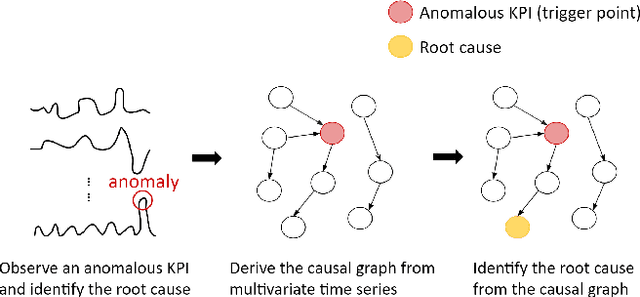
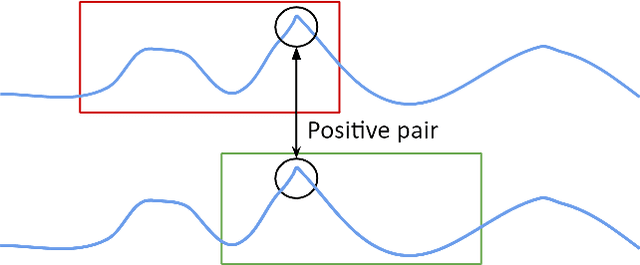
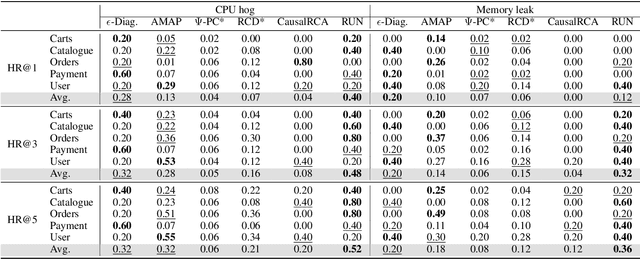
In recent years, microservices have gained widespread adoption in IT operations due to their scalability, maintenance, and flexibility. However, it becomes challenging for site reliability engineers (SREs) to pinpoint the root cause due to the complex relationships in microservices when facing system malfunctions. Previous research employed structured learning methods (e.g., PC-algorithm) to establish causal relationships and derive root causes from causal graphs. Nevertheless, they ignored the temporal order of time series data and failed to leverage the rich information inherent in the temporal relationships. For instance, in cases where there is a sudden spike in CPU utilization, it can lead to an increase in latency for other microservices. However, in this scenario, the anomaly in CPU utilization occurs before the latency increase, rather than simultaneously. As a result, the PC-algorithm fails to capture such characteristics. To address these challenges, we propose RUN, a novel approach for root cause analysis using neural Granger causal discovery with contrastive learning. RUN enhances the backbone encoder by integrating contextual information from time series, and leverages a time series forecasting model to conduct neural Granger causal discovery. In addition, RUN incorporates Pagerank with a personalization vector to efficiently recommend the top-k root causes. Extensive experiments conducted on the synthetic and real-world microservice-based datasets demonstrate that RUN noticeably outperforms the state-of-the-art root cause analysis methods. Moreover, we provide an analysis scenario for the sock-shop case to showcase the practicality and efficacy of RUN in microservice-based applications. Our code is publicly available at https://github.com/zmlin1998/RUN.
TimeDRL: Disentangled Representation Learning for Multivariate Time-Series
Dec 07, 2023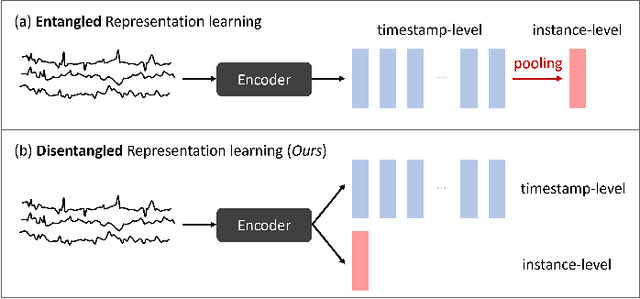
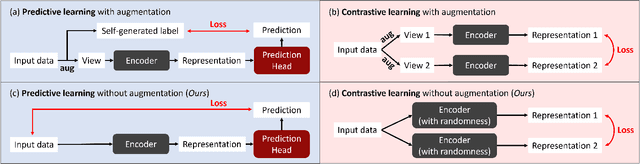
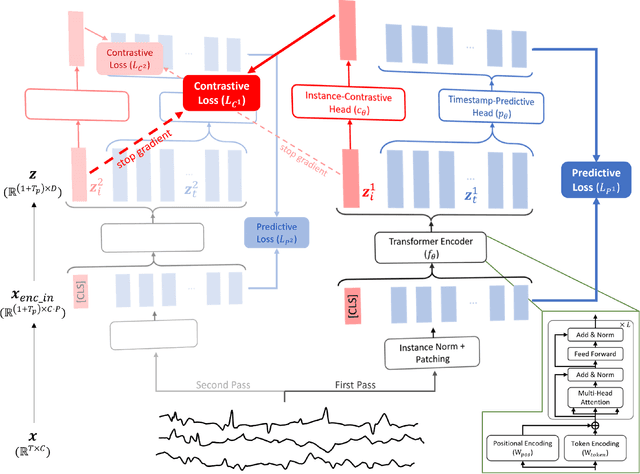
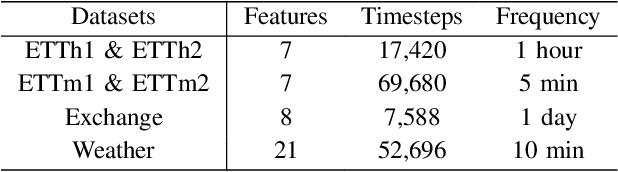
Multivariate time-series data in numerous real-world applications (e.g., healthcare and industry) are informative but challenging due to the lack of labels and high dimensionality. Recent studies in self-supervised learning have shown their potential in learning rich representations without relying on labels, yet they fall short in learning disentangled embeddings and addressing issues of inductive bias (e.g., transformation-invariance). To tackle these challenges, we propose TimeDRL, a generic multivariate time-series representation learning framework with disentangled dual-level embeddings. TimeDRL is characterized by three novel features: (i) disentangled derivation of timestamp-level and instance-level embeddings from patched time-series data using a [CLS] token strategy; (ii) utilization of timestamp-predictive and instance-contrastive tasks for disentangled representation learning, with the former optimizing timestamp-level embeddings with predictive loss, and the latter optimizing instance-level embeddings with contrastive loss; and (iii) avoidance of augmentation methods to eliminate inductive biases, such as transformation-invariance from cropping and masking. Comprehensive experiments on 6 time-series forecasting datasets and 5 time-series classification datasets have shown that TimeDRL consistently surpasses existing representation learning approaches, achieving an average improvement of forecasting by 57.98% in MSE and classification by 1.25% in accuracy. Furthermore, extensive ablation studies confirmed the relative contribution of each component in TimeDRL's architecture, and semi-supervised learning evaluations demonstrated its effectiveness in real-world scenarios, even with limited labeled data.
LLM4TS: Two-Stage Fine-Tuning for Time-Series Forecasting with Pre-Trained LLMs
Aug 16, 2023
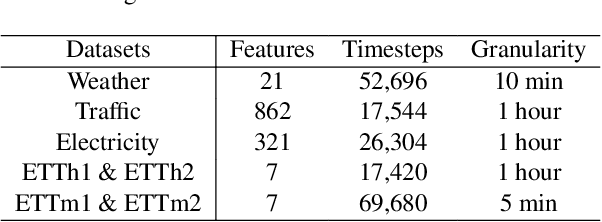
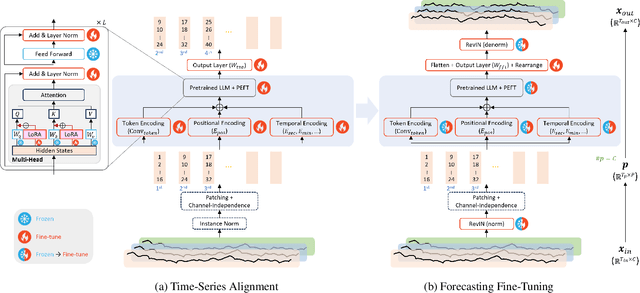

In this work, we leverage pre-trained Large Language Models (LLMs) to enhance time-series forecasting. Mirroring the growing interest in unifying models for Natural Language Processing and Computer Vision, we envision creating an analogous model for long-term time-series forecasting. Due to limited large-scale time-series data for building robust foundation models, our approach LLM4TS focuses on leveraging the strengths of pre-trained LLMs. By combining time-series patching with temporal encoding, we have enhanced the capability of LLMs to handle time-series data effectively. Inspired by the supervised fine-tuning in chatbot domains, we prioritize a two-stage fine-tuning process: first conducting supervised fine-tuning to orient the LLM towards time-series data, followed by task-specific downstream fine-tuning. Furthermore, to unlock the flexibility of pre-trained LLMs without extensive parameter adjustments, we adopt several Parameter-Efficient Fine-Tuning (PEFT) techniques. Drawing on these innovations, LLM4TS has yielded state-of-the-art results in long-term forecasting. Our model has also shown exceptional capabilities as both a robust representation learner and an effective few-shot learner, thanks to the knowledge transferred from the pre-trained LLM.
Detecting and Ranking Causal Anomalies in End-to-End Complex System
Jan 18, 2023With the rapid development of technology, the automated monitoring systems of large-scale factories are becoming more and more important. By collecting a large amount of machine sensor data, we can have many ways to find anomalies. We believe that the real core value of an automated monitoring system is to identify and track the cause of the problem. The most famous method for finding causal anomalies is RCA, but there are many problems that cannot be ignored. They used the AutoRegressive eXogenous (ARX) model to create a time-invariant correlation network as a machine profile, and then use this profile to track the causal anomalies by means of a method called fault propagation. There are two major problems in describing the behavior of a machine by using the correlation network established by ARX: (1) It does not take into account the diversity of states (2) It does not separately consider the correlations with different time-lag. Based on these problems, we propose a framework called Ranking Causal Anomalies in End-to-End System (RCAE2E), which completely solves the problems mentioned above. In the experimental part, we use synthetic data and real-world large-scale photoelectric factory data to verify the correctness and existence of our method hypothesis.