 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptTSS: A Prompting-Based Approach for Interactive Multi-Granularity Time Series Segmentation
Jun 12, 2025Multivariate time series data, collected across various fields such as manufacturing and wearable technology, exhibit states at multiple levels of granularity, from coarse-grained system behaviors to fine-grained, detailed events. Effectively segmenting and integrating states across these different granularities is crucial for tasks like predictive maintenance and performance optimization. However, existing time series segmentation methods face two key challenges: (1) the inability to handle multiple levels of granularity within a unified model, and (2) limited adaptability to new, evolving patterns in dynamic environments. To address these challenges, we propose PromptTSS, a novel framework for time series segmentation with multi-granularity states. PromptTSS uses a unified model with a prompting mechanism that leverages label and boundary information to guide segmentation, capturing both coarse- and fine-grained patterns while adapting dynamically to unseen patterns. Experiments show PromptTSS improves accuracy by 24.49% in multi-granularity segmentation, 17.88% in single-granularity segmentation, and up to 599.24% in transfer learning, demonstrating its adaptability to hierarchical states and evolving time series dynamics.
LLM-Based Routing in Mixture of Experts: A Novel Framework for Trading
Jan 16, 2025Recent advances in deep learning and large language models (LLMs) have facilitated the deployment of the mixture-of-experts (MoE) mechanism in the stock investment domain. While these models have demonstrated promising trading performance, they are often unimodal, neglecting the wealth of information available in other modalities, such as textual data. Moreover, the traditional neural network-based router selection mechanism fails to consider contextual and real-world nuances, resulting in suboptimal expert selection. To address these limitations, we propose LLMoE, a novel framework that employs LLMs as the router within the MoE architecture. Specifically, we replace the conventional neural network-based router with LLMs, leveraging their extensive world knowledge and reasoning capabilities to select experts based on historical price data and stock news. This approach provides a more effective and interpretable selection mechanism. Our experiments on multimodal real-world stock datasets demonstrate that LLMoE outperforms state-of-the-art MoE models and other deep neural network approaches. Additionally, the flexible architecture of LLMoE allows for easy adaptation to various downstream tasks.
Text2Freq: Learning Series Patterns from Text via Frequency Domain
Nov 01, 2024
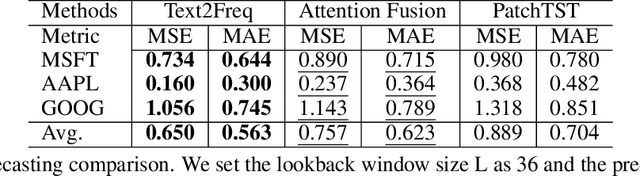


Traditional time series forecasting models mainly rely on historical numeric values to predict future outcomes.While these models have shown promising results, they often overlook the rich information available in other modalities, such as textual descriptions of special events, which can provide crucial insights into future dynamics.However, research that jointly incorporates text in time series forecasting remains relatively underexplored compared to other cross-modality work. Additionally, the modality gap between time series data and textual information poses a challenge for multimodal learning. To address this task, we propose Text2Freq, a cross-modality model that integrates text and time series data via the frequency domain. Specifically, our approach aligns textual information to the low-frequency components of time series data, establishing more effective and interpretable alignments between these two modalities. Our experiments on paired datasets of real-world stock prices and synthetic texts show that Text2Freq achieves state-of-the-art performance, with its adaptable architecture encouraging future research in this field.
Team Trifecta at Factify5WQA: Setting the Standard in Fact Verification with Fine-Tuning
Mar 15, 2024
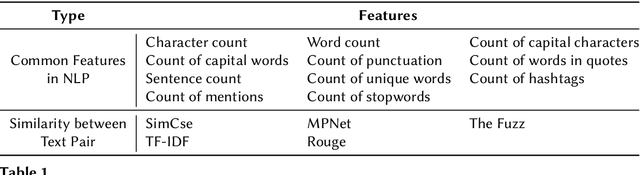
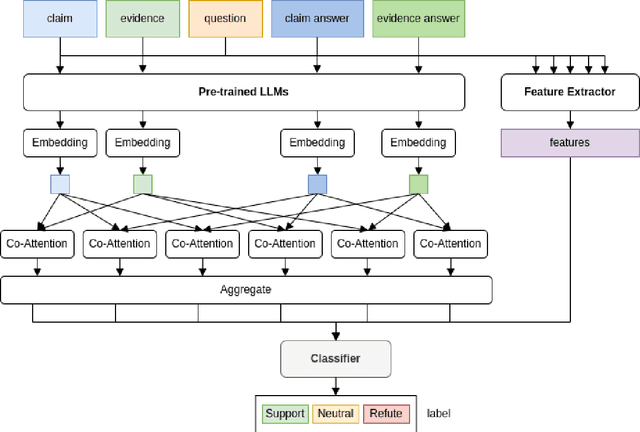
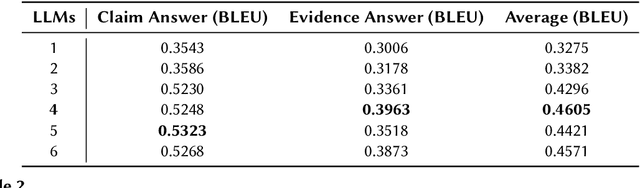
In this paper, we present Pre-CoFactv3, a comprehensive framework comprised of Question Answering and Text Classification components for fact verification. Leveraging In-Context Learning, Fine-tuned Large Language Models (LLMs), and the FakeNet model, we address the challenges of fact verification. Our experiments explore diverse approaches, comparing different Pre-trained LLMs, introducing FakeNet, and implementing various ensemble methods. Notably, our team, Trifecta, secured first place in the AAAI-24 Factify 3.0 Workshop, surpassing the baseline accuracy by 103% and maintaining a 70% lead over the second competitor. This success underscores the efficacy of our approach and its potential contributions to advancing fact verification research.