 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Knowledge Distillation via Synthetic Text Generation
Paper and Code
Mar 01, 2024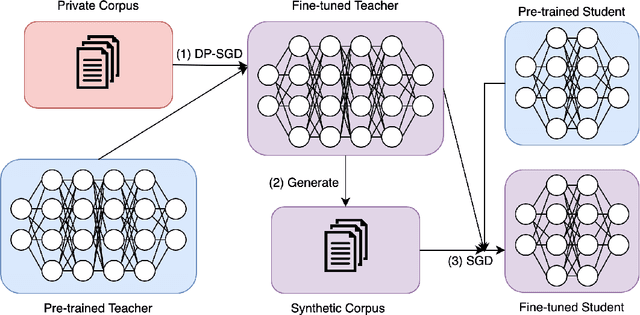
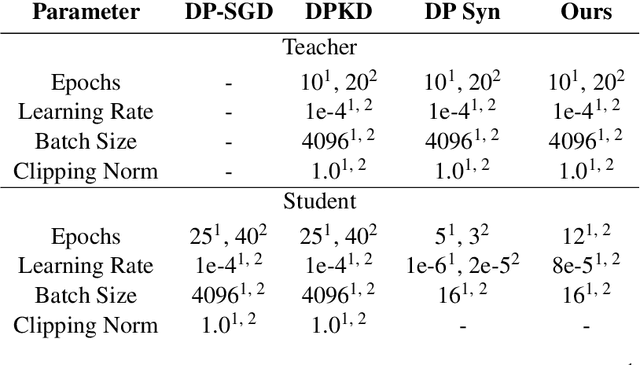
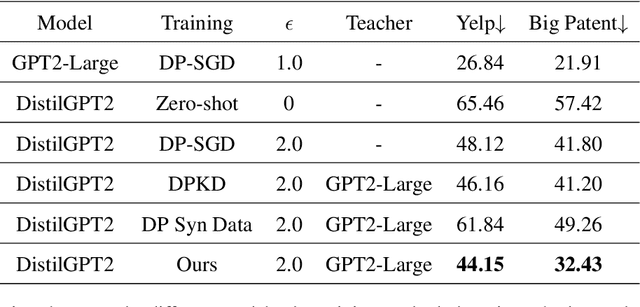
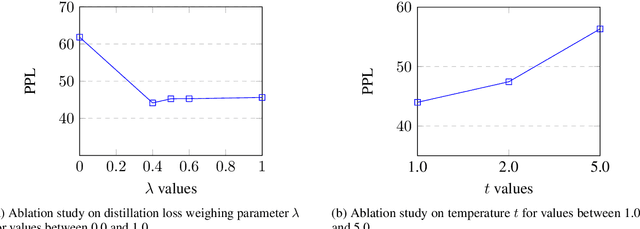
Large Language models (LLMs) are achieving state-of-the-art performance in many different downstream tasks. However, the increasing urgency of data privacy requires LLMs to train with Differential Privacy (DP) on private data. Concurrently it is also necessary to compress LLMs for real-life deployments on resource-constrained devices or latency-sensitive applications. Differential privacy and model compression generally must trade off utility loss to achieve their objectives. Moreover, concurrently achieving both can result in even more utility loss. To this end, we propose a novel differentially private knowledge distillation algorithm that exploits synthetic data generated by a differentially private LLM. The knowledge of a teacher model is transferred onto the student in two ways: one way from the synthetic data itself, the hard labels, and the other way by the output distribution of the teacher model evaluated on the synthetic data, the soft labels. Furthermore, if the teacher and student share a similar architectural structure, we can further distill knowledge by exploiting hidden representations. Our results show that our framework substantially improves the utility over existing baselines with strong privacy parameters, {\epsilon} = 2, validating that we can successfully compress autoregressive LLMs while preserving the privacy of training data.