 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Faceted Evaluation of Tool-Augmented Dialogue Systems
Oct 22, 2025Evaluating conversational AI systems that use external tools is challenging, as errors can arise from complex interactions among user, agent, and tools. While existing evaluation methods assess either user satisfaction or agents' tool-calling capabilities, they fail to capture critical errors in multi-turn tool-augmented dialogues-such as when agents misinterpret tool results yet appear satisfactory to users. We introduce TRACE, a benchmark of systematically synthesized tool-augmented conversations covering diverse error cases, and SCOPE, an evaluation framework that automatically discovers diverse error patterns and evaluation rubrics in tool-augmented dialogues. Experiments show SCOPE significantly outperforms the baseline, particularly on challenging cases where user satisfaction signals are misleading.
Dimension Reduction with Locally Adjusted Graphs
Dec 19, 2024Dimension reduction (DR) algorithms have proven to be extremely useful for gaining insight into large-scale high-dimensional datasets, particularly finding clusters in transcriptomic data. The initial phase of these DR methods often involves converting the original high-dimensional data into a graph. In this graph, each edge represents the similarity or dissimilarity between pairs of data points. However, this graph is frequently suboptimal due to unreliable high-dimensional distances and the limited information extracted from the high-dimensional data. This problem is exacerbated as the dataset size increases. If we reduce the size of the dataset by selecting points for a specific sections of the embeddings, the clusters observed through DR are more separable since the extracted subgraphs are more reliable. In this paper, we introduce LocalMAP, a new dimensionality reduction algorithm that dynamically and locally adjusts the graph to address this challenge. By dynamically extracting subgraphs and updating the graph on-the-fly, LocalMAP is capable of identifying and separating real clusters within the data that other DR methods may overlook or combine. We demonstrate the benefits of LocalMAP through a case study on biological datasets, highlighting its utility in helping users more accurately identify clusters for real-world problems.
Attention Head Purification: A New Perspective to Harness CLIP for Domain Generalization
Dec 10, 2024



Domain Generalization (DG) aims to learn a model from multiple source domains to achieve satisfactory performance on unseen target domains. Recent works introduce CLIP to DG tasks due to its superior image-text alignment and zeros-shot performance. Previous methods either utilize full fine-tuning or prompt-learning paradigms to harness CLIP for DG tasks. Those works focus on avoiding catastrophic forgetting of the original knowledge encoded in CLIP but ignore that the knowledge encoded in CLIP in nature may contain domain-specific cues that constrain its domain generalization performance. In this paper, we propose a new perspective to harness CLIP for DG, i.e., attention head purification. We observe that different attention heads may encode different properties of an image and selecting heads appropriately may yield remarkable performance improvement across domains. Based on such observations, we purify the attention heads of CLIP from two levels, including task-level purification and domain-level purification. For task-level purification, we design head-aware LoRA to make each head more adapted to the task we considered. For domain-level purification, we perform head selection via a simple gating strategy. We utilize MMD loss to encourage masked head features to be more domain-invariant to emphasize more generalizable properties/heads. During training, we jointly perform task-level purification and domain-level purification. We conduct experiments on various representative DG benchmarks. Though simple, extensive experiments demonstrate that our method performs favorably against previous state-of-the-arts.
Navigating the Effect of Parametrization for Dimensionality Reduction
Nov 24, 2024Parametric dimensionality reduction methods have gained prominence for their ability to generalize to unseen datasets, an advantage that traditional approaches typically lack. Despite their growing popularity, there remains a prevalent misconception among practitioners about the equivalence in performance between parametric and non-parametric methods. Here, we show that these methods are not equivalent -- parametric methods retain global structure but lose significant local details. To explain this, we provide evidence that parameterized approaches lack the ability to repulse negative pairs, and the choice of loss function also has an impact. Addressing these issues, we developed a new parametric method, ParamRepulsor, that incorporates Hard Negative Mining and a loss function that applies a strong repulsive force. This new method achieves state-of-the-art performance on local structure preservation for parametric methods without sacrificing the fidelity of global structural representation. Our code is available at https://github.com/hyhuang00/ParamRepulsor.
Understanding How Dimension Reduction Tools Work: An Empirical Approach to Deciphering t-SNE, UMAP, TriMAP, and PaCMAP for Data Visualization
Dec 08, 2020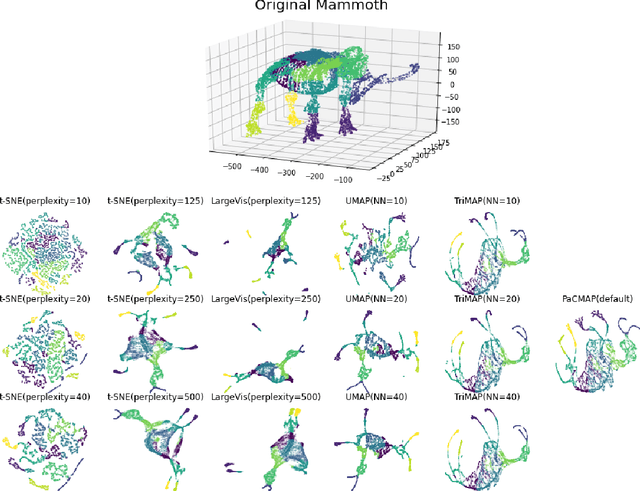

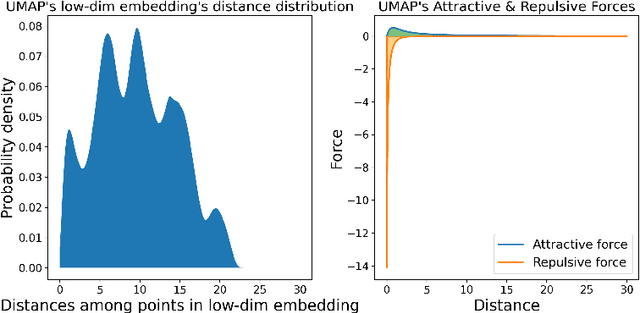
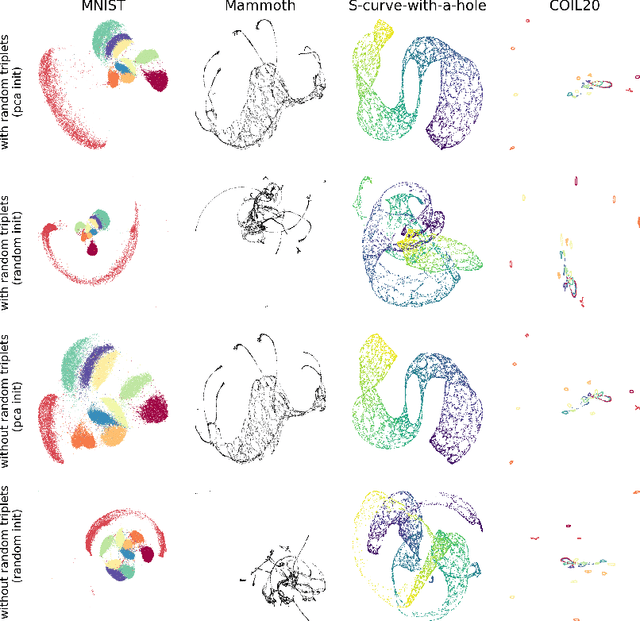
Dimension reduction (DR) techniques such as t-SNE, UMAP, and TriMAP have demonstrated impressive visualization performance on many real world datasets. One tension that has always faced these methods is the trade-off between preservation of global structure and preservation of local structure: these methods can either handle one or the other, but not both. In this work, our main goal is to understand what aspects of DR methods are important for preserving both local and global structure: it is difficult to design a better method without a true understanding of the choices we make in our algorithms and their empirical impact on the lower-dimensional embeddings they produce. Towards the goal of local structure preservation, we provide several useful design principles for DR loss functions based on our new understanding of the mechanisms behind successful DR methods. Towards the goal of global structure preservation, our analysis illuminates that the choice of which components to preserve is important. We leverage these insights to design a new algorithm for DR, called Pairwise Controlled Manifold Approximation Projection (PaCMAP), which preserves both local and global structure. Our work provides several unexpected insights into what design choices both to make and avoid when constructing DR algorithms.