 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere are they looking in the operating room?
Apr 22, 2026Purpose: Gaze-following, the task of inferring where individuals are looking, has been widely studied in computer vision, advancing research in visual attention modeling, social scene understanding, and human-robot interaction. However, gaze-following has never been explored in the operating room (OR), a complex, high-stakes environment where visual attention plays an important role in surgical workflow analysis. In this work, we introduce the concept of gaze-following to the surgical domain, and demonstrate its great potential for understanding clinical roles, surgical phases, and team communications in the OR. Methods: We extend the 4D-OR dataset with gaze-following annotations, and extend the Team-OR dataset with gaze-following and a new team communication activity annotations. Then, we propose novel approaches to address clinical role prediction, surgical phase recognition, and team communication detection using a gaze-following model. For role and phase recognition, we propose a gaze heatmap-based approach that uses gaze predictions solely; for team communication detection, we train a spatial-temporal model in a self-supervised way that encodes gaze-based clip features, and then feed the features into a temporal activity detection model. Results: Experimental results on the 4D-OR and Team-OR datasets demonstrate that our approach achieves state-of-the-art performance on all downstream tasks. Quantitatively, our approach obtains F1 scores of 0.92 for clinical role prediction and 0.95 for surgical phase recognition. Furthermore, it significantly outperforms existing baselines in team communication detection, improving previous best performances by over 30%. Conclusion: We introduce gaze-following in the OR as a novel research direction in surgical data science, highlighting its great potential to advance surgical workflow analysis in computer-assisted interventions.
Self-Supervised Uncalibrated Multi-View Video Anonymization in the Operating Room
Feb 02, 2026Privacy preservation is a prerequisite for using video data in Operating Room (OR) research. Effective anonymization relies on the exhaustive localization of every individual; even a single missed detection necessitates extensive manual correction. However, existing approaches face two critical scalability bottlenecks: (1) they usually require manual annotations of each new clinical site for high accuracy; (2) while multi-camera setups have been widely adopted to address single-view ambiguity, camera calibration is typically required whenever cameras are repositioned. To address these problems, we propose a novel self-supervised multi-view video anonymization framework consisting of whole-body person detection and whole-body pose estimation, without annotation or camera calibration. Our core strategy is to enhance the single-view detector by "retrieving" false negatives using temporal and multi-view context, and conducting self-supervised domain adaptation. We first run an off-the-shelf whole-body person detector in each view with a low-score threshold to gather candidate detections. Then, we retrieve the low-score false negatives that exhibit consistency with the high-score detections via tracking and self-supervised uncalibrated multi-view association. These recovered detections serve as pseudo labels to iteratively fine-tune the whole-body detector. Finally, we apply whole-body pose estimation on each detected person, and fine-tune the pose model using its own high-score predictions. Experiments on the 4D-OR dataset of simulated surgeries and our dataset of real surgeries show the effectiveness of our approach achieving over 97% recall. Moreover, we train a real-time whole-body detector using our pseudo labels, achieving comparable performance and highlighting our method's practical applicability. Code is available at https://github.com/CAMMA-public/OR_anonymization.
Learning from Synchronization: Self-Supervised Uncalibrated Multi-View Person Association in Challenging Scenes
Mar 17, 2025Multi-view person association is a fundamental step towards multi-view analysis of human activities. Although the person re-identification features have been proven effective, they become unreliable in challenging scenes where persons share similar appearances. Therefore, cross-view geometric constraints are required for a more robust association. However, most existing approaches are either fully-supervised using ground-truth identity labels or require calibrated camera parameters that are hard to obtain. In this work, we investigate the potential of learning from synchronization, and propose a self-supervised uncalibrated multi-view person association approach, Self-MVA, without using any annotations. Specifically, we propose a self-supervised learning framework, consisting of an encoder-decoder model and a self-supervised pretext task, cross-view image synchronization, which aims to distinguish whether two images from different views are captured at the same time. The model encodes each person's unified geometric and appearance features, and we train it by utilizing synchronization labels for supervision after applying Hungarian matching to bridge the gap between instance-wise and image-wise distances. To further reduce the solution space, we propose two types of self-supervised linear constraints: multi-view re-projection and pairwise edge association. Extensive experiments on three challenging public benchmark datasets (WILDTRACK, MVOR, and SOLDIERS) show that our approach achieves state-of-the-art results, surpassing existing unsupervised and fully-supervised approaches. Code is available at https://github.com/CAMMA-public/Self-MVA.
Psy-Copilot: Visual Chain of Thought for Counseling
Mar 05, 2025

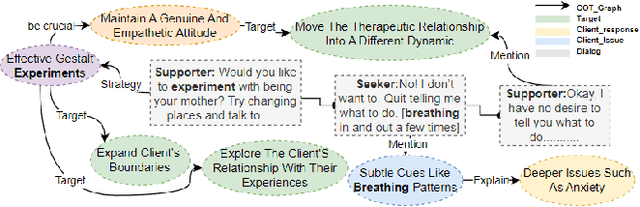

Large language models (LLMs) are becoming increasingly popular in the field of psychological counseling. However, when human therapists work with LLMs in therapy sessions, it is hard to understand how the model gives the answers. To address this, we have constructed Psy-COT, a graph designed to visualize the thought processes of LLMs during therapy sessions. The Psy-COT graph presents semi-structured counseling conversations alongside step-by-step annotations that capture the reasoning and insights of therapists. Moreover, we have developed Psy-Copilot, which is a conversational AI assistant designed to assist human psychological therapists in their consultations. It can offer traceable psycho-information based on retrieval, including response candidates, similar dialogue sessions, related strategies, and visual traces of results. We have also built an interactive platform for AI-assisted counseling. It has an interface that displays the relevant parts of the retrieval sub-graph. The Psy-Copilot is designed not to replace psychotherapists but to foster collaboration between AI and human therapists, thereby promoting mental health development. Our code and demo are both open-sourced and available for use.
Psy-Insight: Explainable Multi-turn Bilingual Dataset for Mental Health Counseling
Mar 05, 2025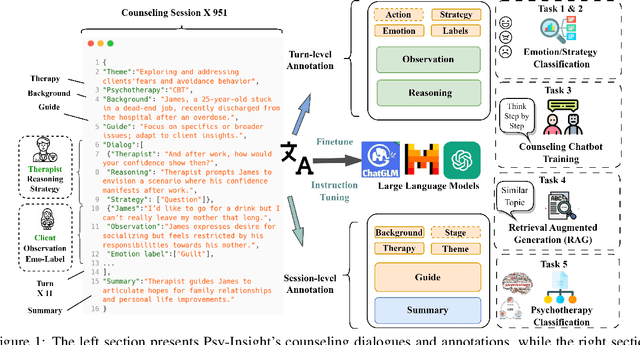
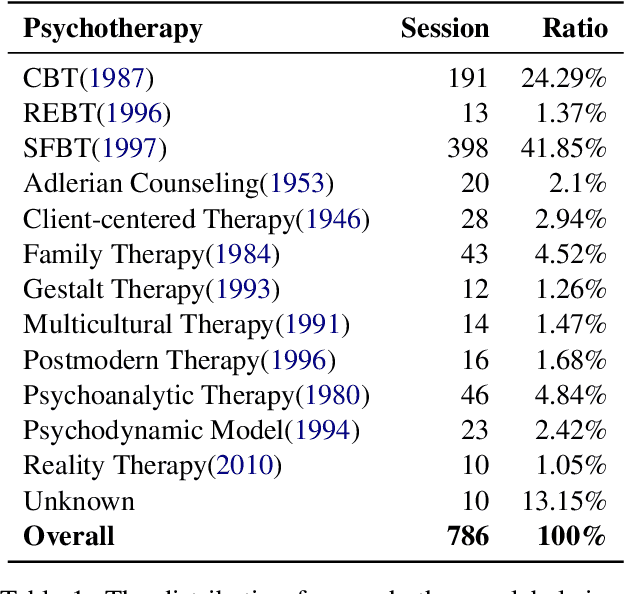
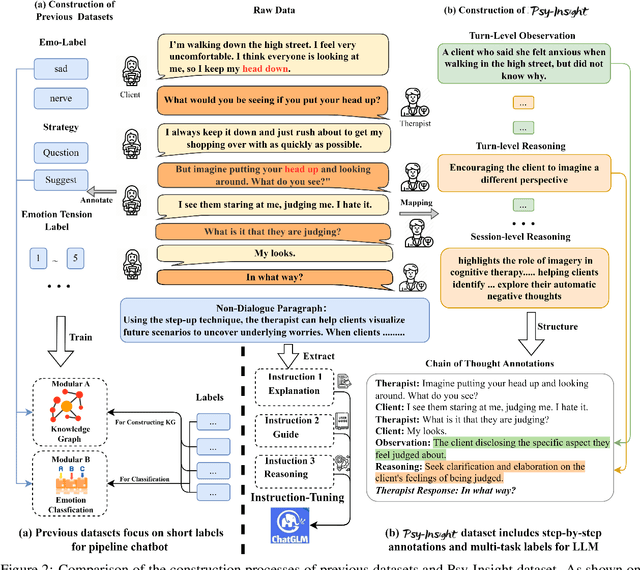
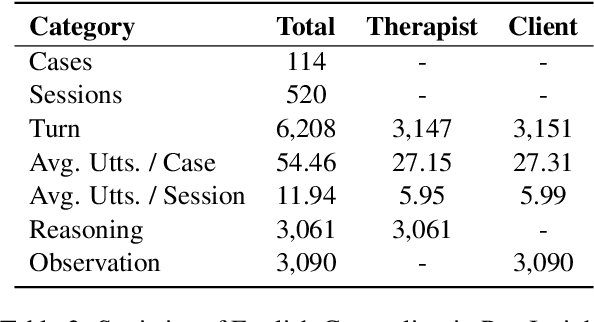
The in-context learning capabilities of large language models (LLMs) show great potential in mental health support. However, the lack of counseling datasets, particularly in Chinese corpora, restricts their application in this field. To address this, we constructed Psy-Insight, the first mental health-oriented explainable multi-task bilingual dataset. We collected face-to-face multi-turn counseling dialogues, which are annotated with multi-task labels and conversation process explanations. Our annotations include psychotherapy, emotion, strategy, and topic labels, as well as turn-level reasoning and session-level guidance. Psy-Insight is not only suitable for tasks such as label recognition but also meets the need for training LLMs to act as empathetic counselors through logical reasoning. Experiments show that training LLMs on Psy-Insight enables the models to not only mimic the conversation style but also understand the underlying strategies and reasoning of counseling.
When do they StOP?: A First Step Towards Automatically Identifying Team Communication in the Operating Room
Feb 12, 2025Purpose: Surgical performance depends not only on surgeons' technical skills but also on team communication within and across the different professional groups present during the operation. Therefore, automatically identifying team communication in the OR is crucial for patient safety and advances in the development of computer-assisted surgical workflow analysis and intra-operative support systems. To take the first step, we propose a new task of detecting communication briefings involving all OR team members, i.e. the team Time-out and the StOP?-protocol, by localizing their start and end times in video recordings of surgical operations. Methods: We generate an OR dataset of real surgeries, called Team-OR, with more than one hundred hours of surgical videos captured by the multi-view camera system in the OR. The dataset contains temporal annotations of 33 Time-out and 22 StOP?-protocol activities in total. We then propose a novel group activity detection approach, where we encode both scene context and action features, and use an efficient neural network model to output the results. Results: The experimental results on the Team-OR dataset show that our approach outperforms existing state-of-the-art temporal action detection approaches. It also demonstrates the lack of research on group activities in the OR, proving the significance of our dataset. Conclusion: We investigate the Team Time-Out and the StOP?-protocol in the OR, by presenting the first OR dataset with temporal annotations of group activities protocols, and introducing a novel group activity detection approach that outperforms existing approaches. Code is available at https://github.com/CAMMA-public/Team-OR .
SelfPose3d: Self-Supervised Multi-Person Multi-View 3d Pose Estimation
Apr 02, 2024



We present a new self-supervised approach, SelfPose3d, for estimating 3d poses of multiple persons from multiple camera views. Unlike current state-of-the-art fully-supervised methods, our approach does not require any 2d or 3d ground-truth poses and uses only the multi-view input images from a calibrated camera setup and 2d pseudo poses generated from an off-the-shelf 2d human pose estimator. We propose two self-supervised learning objectives: self-supervised person localization in 3d space and self-supervised 3d pose estimation. We achieve self-supervised 3d person localization by training the model on synthetically generated 3d points, serving as 3d person root positions, and on the projected root-heatmaps in all the views. We then model the 3d poses of all the localized persons with a bottleneck representation, map them onto all views obtaining 2d joints, and render them using 2d Gaussian heatmaps in an end-to-end differentiable manner. Afterwards, we use the corresponding 2d joints and heatmaps from the pseudo 2d poses for learning. To alleviate the intrinsic inaccuracy of the pseudo labels, we propose an adaptive supervision attention mechanism to guide the self-supervision. Our experiments and analysis on three public benchmark datasets, including Panoptic, Shelf, and Campus, show the effectiveness of our approach, which is comparable to fully-supervised methods. Code is available at \url{https://github.com/CAMMA-public/SelfPose3D}