 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Uncalibrated Multi-View Video Anonymization in the Operating Room
Feb 02, 2026Privacy preservation is a prerequisite for using video data in Operating Room (OR) research. Effective anonymization relies on the exhaustive localization of every individual; even a single missed detection necessitates extensive manual correction. However, existing approaches face two critical scalability bottlenecks: (1) they usually require manual annotations of each new clinical site for high accuracy; (2) while multi-camera setups have been widely adopted to address single-view ambiguity, camera calibration is typically required whenever cameras are repositioned. To address these problems, we propose a novel self-supervised multi-view video anonymization framework consisting of whole-body person detection and whole-body pose estimation, without annotation or camera calibration. Our core strategy is to enhance the single-view detector by "retrieving" false negatives using temporal and multi-view context, and conducting self-supervised domain adaptation. We first run an off-the-shelf whole-body person detector in each view with a low-score threshold to gather candidate detections. Then, we retrieve the low-score false negatives that exhibit consistency with the high-score detections via tracking and self-supervised uncalibrated multi-view association. These recovered detections serve as pseudo labels to iteratively fine-tune the whole-body detector. Finally, we apply whole-body pose estimation on each detected person, and fine-tune the pose model using its own high-score predictions. Experiments on the 4D-OR dataset of simulated surgeries and our dataset of real surgeries show the effectiveness of our approach achieving over 97% recall. Moreover, we train a real-time whole-body detector using our pseudo labels, achieving comparable performance and highlighting our method's practical applicability. Code is available at https://github.com/CAMMA-public/OR_anonymization.
DExTeR: Weakly Semi-Supervised Object Detection with Class and Instance Experts for Medical Imaging
Jan 20, 2026Detecting anatomical landmarks in medical imaging is essential for diagnosis and intervention guidance. However, object detection models rely on costly bounding box annotations, limiting scalability. Weakly Semi-Supervised Object Detection (WSSOD) with point annotations proposes annotating each instance with a single point, minimizing annotation time while preserving localization signals. A Point-to-Box teacher model, trained on a small box-labeled subset, converts these point annotations into pseudo-box labels to train a student detector. Yet, medical imagery presents unique challenges, including overlapping anatomy, variable object sizes, and elusive structures, which hinder accurate bounding box inference. To overcome these challenges, we introduce DExTeR (DETR with Experts), a transformer-based Point-to-Box regressor tailored for medical imaging. Built upon Point-DETR, DExTeR encodes single-point annotations as object queries, refining feature extraction with the proposed class-guided deformable attention, which guides attention sampling using point coordinates and class labels to capture class-specific characteristics. To improve discrimination in complex structures, it introduces CLICK-MoE (CLass, Instance, and Common Knowledge Mixture of Experts), decoupling class and instance representations to reduce confusion among adjacent or overlapping instances. Finally, we implement a multi-point training strategy which promotes prediction consistency across different point placements, improving robustness to annotation variability. DExTeR achieves state-of-the-art performance across three datasets spanning different medical domains (endoscopy, chest X-rays, and endoscopic ultrasound) highlighting its potential to reduce annotation costs while maintaining high detection accuracy.
fine-CLIP: Enhancing Zero-Shot Fine-Grained Surgical Action Recognition with Vision-Language Models
Mar 25, 2025



While vision-language models like CLIP have advanced zero-shot surgical phase recognition, they struggle with fine-grained surgical activities, especially action triplets. This limitation arises because current CLIP formulations rely on global image features, which overlook the fine-grained semantics and contextual details crucial for complex tasks like zero-shot triplet recognition. Furthermore, these models do not explore the hierarchical structure inherent in triplets, reducing their ability to generalize to novel triplets. To address these challenges, we propose fine-CLIP, which learns object-centric features and lever- ages the hierarchy in triplet formulation. Our approach integrates three components: hierarchical prompt modeling to capture shared semantics, LoRA-based vision backbone adaptation for enhanced feature extraction, and a graph-based condensation strategy that groups similar patch features into meaningful object clusters. Since triplet classification is a challenging task, we introduce an alternative yet meaningful base-to-novel generalization benchmark with two settings on the CholecT50 dataset: Unseen-Target, assessing adaptability to triplets with novel anatomical structures, and Unseen-Instrument-Verb, where models need to generalize to novel instrument-verb interactions. fine-CLIP shows significant improvements in F1 and mAP, enhancing zero-shot recognition of novel surgical triplets.
Learning from Synchronization: Self-Supervised Uncalibrated Multi-View Person Association in Challenging Scenes
Mar 17, 2025Multi-view person association is a fundamental step towards multi-view analysis of human activities. Although the person re-identification features have been proven effective, they become unreliable in challenging scenes where persons share similar appearances. Therefore, cross-view geometric constraints are required for a more robust association. However, most existing approaches are either fully-supervised using ground-truth identity labels or require calibrated camera parameters that are hard to obtain. In this work, we investigate the potential of learning from synchronization, and propose a self-supervised uncalibrated multi-view person association approach, Self-MVA, without using any annotations. Specifically, we propose a self-supervised learning framework, consisting of an encoder-decoder model and a self-supervised pretext task, cross-view image synchronization, which aims to distinguish whether two images from different views are captured at the same time. The model encodes each person's unified geometric and appearance features, and we train it by utilizing synchronization labels for supervision after applying Hungarian matching to bridge the gap between instance-wise and image-wise distances. To further reduce the solution space, we propose two types of self-supervised linear constraints: multi-view re-projection and pairwise edge association. Extensive experiments on three challenging public benchmark datasets (WILDTRACK, MVOR, and SOLDIERS) show that our approach achieves state-of-the-art results, surpassing existing unsupervised and fully-supervised approaches. Code is available at https://github.com/CAMMA-public/Self-MVA.
S4M: Segment Anything with 4 Extreme Points
Mar 07, 2025The Segment Anything Model (SAM) has revolutionized open-set interactive image segmentation, inspiring numerous adapters for the medical domain. However, SAM primarily relies on sparse prompts such as point or bounding box, which may be suboptimal for fine-grained instance segmentation, particularly in endoscopic imagery, where precise localization is critical and existing prompts struggle to capture object boundaries effectively. To address this, we introduce S4M (Segment Anything with 4 Extreme Points), which augments SAM by leveraging extreme points -- the top-, bottom-, left-, and right-most points of an instance -- prompts. These points are intuitive to identify and provide a faster, structured alternative to box prompts. However, a na\"ive use of extreme points degrades performance, due to SAM's inability to interpret their semantic roles. To resolve this, we introduce dedicated learnable embeddings, enabling the model to distinguish extreme points from generic free-form points and better reason about their spatial relationships. We further propose an auxiliary training task through the Canvas module, which operates solely on prompts -- without vision input -- to predict a coarse instance mask. This encourages the model to internalize the relationship between extreme points and mask distributions, leading to more robust segmentation. S4M outperforms other SAM-based approaches on three endoscopic surgical datasets, demonstrating its effectiveness in complex scenarios. Finally, we validate our approach through a human annotation study on surgical endoscopic videos, confirming that extreme points are faster to acquire than bounding boxes.
Multi-view Video-Pose Pretraining for Operating Room Surgical Activity Recognition
Feb 19, 2025



Understanding the workflow of surgical procedures in complex operating rooms requires a deep understanding of the interactions between clinicians and their environment. Surgical activity recognition (SAR) is a key computer vision task that detects activities or phases from multi-view camera recordings. Existing SAR models often fail to account for fine-grained clinician movements and multi-view knowledge, or they require calibrated multi-view camera setups and advanced point-cloud processing to obtain better results. In this work, we propose a novel calibration-free multi-view multi-modal pretraining framework called Multiview Pretraining for Video-Pose Surgical Activity Recognition PreViPS, which aligns 2D pose and vision embeddings across camera views. Our model follows CLIP-style dual-encoder architecture: one encoder processes visual features, while the other encodes human pose embeddings. To handle the continuous 2D human pose coordinates, we introduce a tokenized discrete representation to convert the continuous 2D pose coordinates into discrete pose embeddings, thereby enabling efficient integration within the dual-encoder framework. To bridge the gap between these two modalities, we propose several pretraining objectives using cross- and in-modality geometric constraints within the embedding space and incorporating masked pose token prediction strategy to enhance representation learning. Extensive experiments and ablation studies demonstrate improvements over the strong baselines, while data-efficiency experiments on two distinct operating room datasets further highlight the effectiveness of our approach. We highlight the benefits of our approach for surgical activity recognition in both multi-view and single-view settings, showcasing its practical applicability in complex surgical environments. Code will be made available at: https://github.com/CAMMA-public/PreViPS.
When do they StOP?: A First Step Towards Automatically Identifying Team Communication in the Operating Room
Feb 12, 2025Purpose: Surgical performance depends not only on surgeons' technical skills but also on team communication within and across the different professional groups present during the operation. Therefore, automatically identifying team communication in the OR is crucial for patient safety and advances in the development of computer-assisted surgical workflow analysis and intra-operative support systems. To take the first step, we propose a new task of detecting communication briefings involving all OR team members, i.e. the team Time-out and the StOP?-protocol, by localizing their start and end times in video recordings of surgical operations. Methods: We generate an OR dataset of real surgeries, called Team-OR, with more than one hundred hours of surgical videos captured by the multi-view camera system in the OR. The dataset contains temporal annotations of 33 Time-out and 22 StOP?-protocol activities in total. We then propose a novel group activity detection approach, where we encode both scene context and action features, and use an efficient neural network model to output the results. Results: The experimental results on the Team-OR dataset show that our approach outperforms existing state-of-the-art temporal action detection approaches. It also demonstrates the lack of research on group activities in the OR, proving the significance of our dataset. Conclusion: We investigate the Team Time-Out and the StOP?-protocol in the OR, by presenting the first OR dataset with temporal annotations of group activities protocols, and introducing a novel group activity detection approach that outperforms existing approaches. Code is available at https://github.com/CAMMA-public/Team-OR .
Early Operative Difficulty Assessment in Laparoscopic Cholecystectomy via Snapshot-Centric Video Analysis
Feb 10, 2025Purpose: Laparoscopic cholecystectomy (LC) operative difficulty (LCOD) is highly variable and influences outcomes. Despite extensive LC studies in surgical workflow analysis, limited efforts explore LCOD using intraoperative video data. Early recog- nition of LCOD could allow prompt review by expert surgeons, enhance operating room (OR) planning, and improve surgical outcomes. Methods: We propose the clinical task of early LCOD assessment using limited video observations. We design SurgPrOD, a deep learning model to assess LCOD by analyzing features from global and local temporal resolutions (snapshots) of the observed LC video. Also, we propose a novel snapshot-centric attention (SCA) module, acting across snapshots, to enhance LCOD prediction. We introduce the CholeScore dataset, featuring video-level LCOD labels to validate our method. Results: We evaluate SurgPrOD on 3 LCOD assessment scales in the CholeScore dataset. On our new metric assessing early and stable correct predictions, SurgPrOD surpasses baselines by at least 0.22 points. SurgPrOD improves over baselines by at least 9 and 5 percentage points in F1 score and top1-accuracy, respectively, demonstrating its effectiveness in correct predictions. Conclusion: We propose a new task for early LCOD assessment and a novel model, SurgPrOD analyzing surgical video from global and local perspectives. Our results on the CholeScore dataset establishes a new benchmark to study LCOD using intraoperative video data.
UltraSam: A Foundation Model for Ultrasound using Large Open-Access Segmentation Datasets
Nov 25, 2024Purpose: Automated ultrasound image analysis is challenging due to anatomical complexity and limited annotated data. To tackle this, we take a data-centric approach, assembling the largest public ultrasound segmentation dataset and training a versatile visual foundation model tailored for ultrasound. Methods: We compile US-43d, a large-scale collection of 43 open-access ultrasound datasets with over 280,000 images and segmentation masks for more than 50 anatomical structures. We then introduce UltraSam, an adaptation of the Segment Anything Model (SAM) that is trained on US-43d and supports both point- and box-prompts. Finally, we introduce a new use case for SAM-style models by using UltraSam as a model initialization that can be fine-tuned for various downstream analysis tasks, demonstrating UltraSam's foundational capabilities. Results: UltraSam achieves vastly improved performance over existing SAM-style models for prompt-based segmentation on three diverse public datasets. Moreover, an UltraSam-initialized Vision Transformer surpasses ImageNet-, SAM-, and MedSAM-initialized models in various downstream segmentation and classification tasks, highlighting UltraSam's effectiveness as a foundation model. Conclusion: We compile US-43d, a large-scale unified ultrasound dataset, and introduce UltraSam, a powerful multi-purpose SAM-style model for ultrasound images. We release our code and pretrained models at https://github.com/CAMMA-public/UltraSam and invite the community to further this effort by contributing high-quality datasets.
CycleSAM: One-Shot Surgical Scene Segmentation using Cycle-Consistent Feature Matching to Prompt SAM
Jul 09, 2024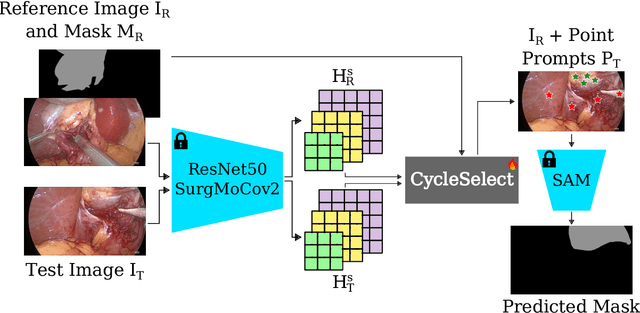
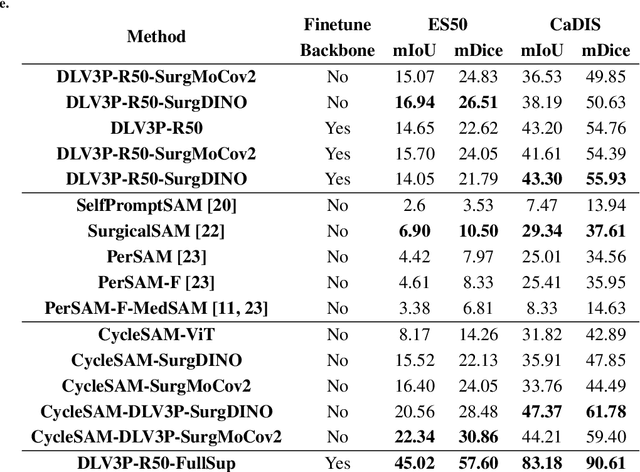

The recently introduced Segment-Anything Model (SAM) has the potential to greatly accelerate the development of segmentation models. However, directly applying SAM to surgical images has key limitations including (1) the requirement of image-specific prompts at test-time, thereby preventing fully automated segmentation, and (2) ineffectiveness due to substantial domain gap between natural and surgical images. In this work, we propose CycleSAM, an approach for one-shot surgical scene segmentation that uses the training image-mask pair at test-time to automatically identify points in the test images that correspond to each object class, which can then be used to prompt SAM to produce object masks. To produce high-fidelity matches, we introduce a novel spatial cycle-consistency constraint that enforces point proposals in the test image to rematch to points within the object foreground region in the training image. Then, to address the domain gap, rather than directly using the visual features from SAM, we employ a ResNet50 encoder pretrained on surgical images in a self-supervised fashion, thereby maintaining high label-efficiency. We evaluate CycleSAM for one-shot segmentation on two diverse surgical semantic segmentation datasets, comprehensively outperforming baseline approaches and reaching up to 50% of fully-supervised performance.