 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgeons Awareness, Expectations, and Involvement with Artificial Intelligence: a Survey Pre and Post the GPT Era
Jun 09, 2025Artificial Intelligence (AI) is transforming medicine, with generative AI models like ChatGPT reshaping perceptions of its potential. This study examines surgeons' awareness, expectations, and involvement with AI in surgery through comparative surveys conducted in 2021 and 2024. Two cross-sectional surveys were distributed globally in 2021 and 2024, the first before an IRCAD webinar and the second during the annual EAES meeting. The surveys assessed demographics, AI awareness, expectations, involvement, and ethics (2024 only). The surveys collected a total of 671 responses from 98 countries, 522 in 2021 and 149 in 2024. Awareness of AI courses rose from 14.5% in 2021 to 44.6% in 2024, while course attendance increased from 12.9% to 23%. Despite this, familiarity with foundational AI concepts remained limited. Expectations for AI's role shifted in 2024, with hospital management gaining relevance. Ethical concerns gained prominence, with 87.2% of 2024 participants emphasizing accountability and transparency. Infrastructure limitations remained the primary obstacle to implementation. Interdisciplinary collaboration and structured training were identified as critical for successful AI adoption. Optimism about AI's transformative potential remained high, with 79.9% of respondents believing AI would positively impact surgery and 96.6% willing to integrate AI into their clinical practice. Surgeons' perceptions of AI are evolving, driven by the rise of generative AI and advancements in surgical data science. While enthusiasm for integration is strong, knowledge gaps and infrastructural challenges persist. Addressing these through education, ethical frameworks, and infrastructure development is essential.
The Endoscapes Dataset for Surgical Scene Segmentation, Object Detection, and Critical View of Safety Assessment: Official Splits and Benchmark
Dec 19, 2023



This technical report provides a detailed overview of Endoscapes, a dataset of laparoscopic cholecystectomy (LC) videos with highly intricate annotations targeted at automated assessment of the Critical View of Safety (CVS). Endoscapes comprises 201 LC videos with frames annotated sparsely but regularly with segmentation masks, bounding boxes, and CVS assessment by three different clinical experts. Altogether, there are 11090 frames annotated with CVS and 1933 frames annotated with tool and anatomy bounding boxes from the 201 videos, as well as an additional 422 frames from 50 of the 201 videos annotated with tool and anatomy segmentation masks. In this report, we provide detailed dataset statistics (size, class distribution, dataset splits, etc.) and a comprehensive performance benchmark for instance segmentation, object detection, and CVS prediction. The dataset and model checkpoints are publically available at https://github.com/CAMMA-public/Endoscapes.
Real-Time Artificial Intelligence Assistance for Safe Laparoscopic Cholecystectomy: Early-Stage Clinical Evaluation
Dec 13, 2022
Artificial intelligence is set to be deployed in operating rooms to improve surgical care. This early-stage clinical evaluation shows the feasibility of concurrently attaining real-time, high-quality predictions from several deep neural networks for endoscopic video analysis deployed for assistance during three laparoscopic cholecystectomies.
Temporally Constrained Neural Networks (TCNN): A framework for semi-supervised video semantic segmentation
Dec 27, 2021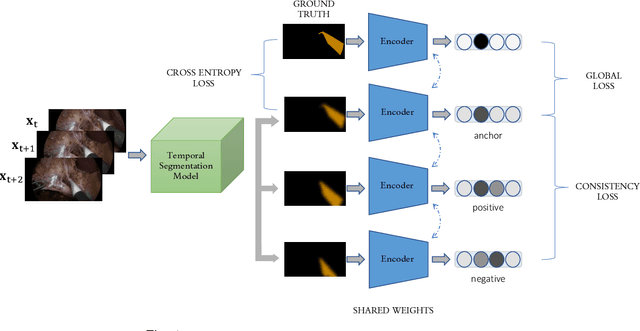
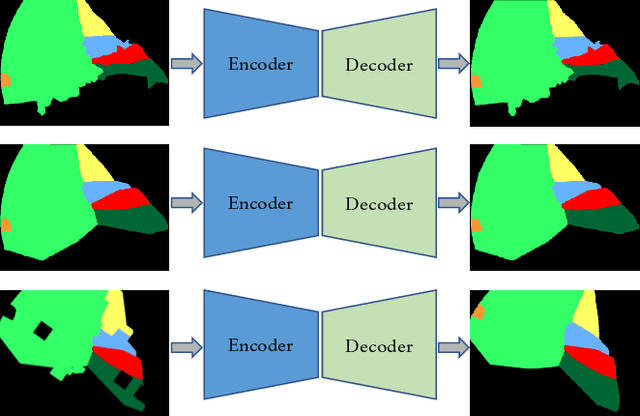
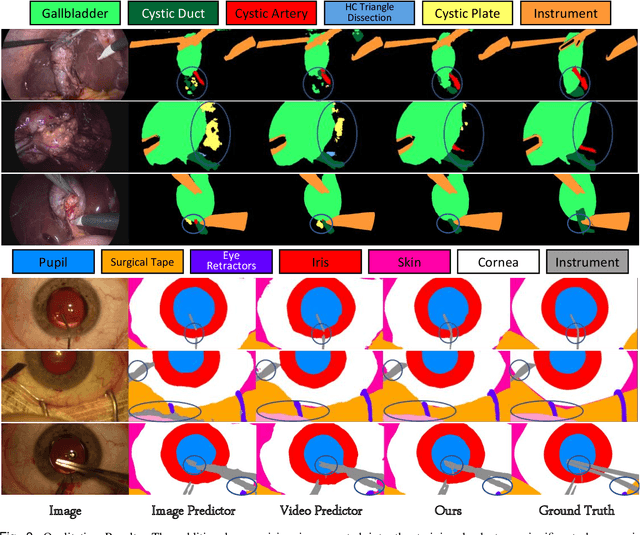
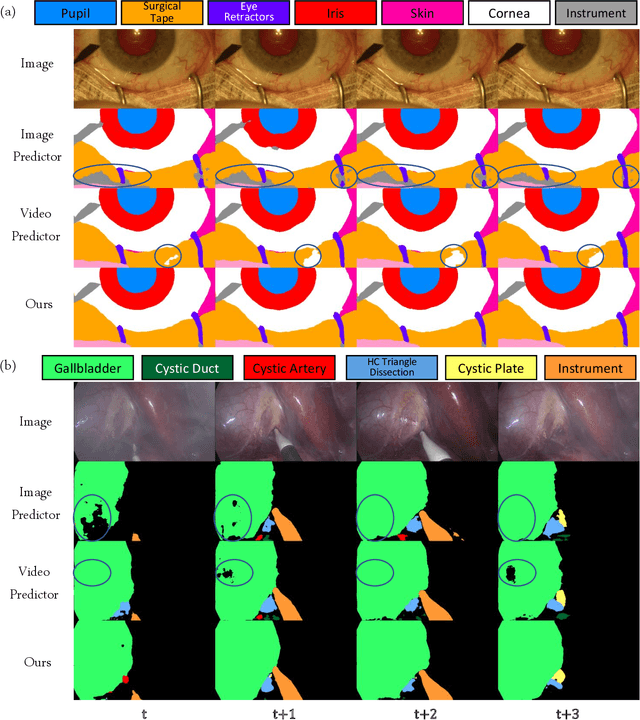
A major obstacle to building models for effective semantic segmentation, and particularly video semantic segmentation, is a lack of large and well annotated datasets. This bottleneck is particularly prohibitive in highly specialized and regulated fields such as medicine and surgery, where video semantic segmentation could have important applications but data and expert annotations are scarce. In these settings, temporal clues and anatomical constraints could be leveraged during training to improve performance. Here, we present Temporally Constrained Neural Networks (TCNN), a semi-supervised framework used for video semantic segmentation of surgical videos. In this work, we show that autoencoder networks can be used to efficiently provide both spatial and temporal supervisory signals to train deep learning models. We test our method on a newly introduced video dataset of laparoscopic cholecystectomy procedures, Endoscapes, and an adaptation of a public dataset of cataract surgeries, CaDIS. We demonstrate that lower-dimensional representations of predicted masks can be leveraged to provide a consistent improvement on both sparsely labeled datasets with no additional computational cost at inference time. Further, the TCNN framework is model-agnostic and can be used in conjunction with other model design choices with minimal additional complexity.
Surgical data science for safe cholecystectomy: a protocol for segmentation of hepatocystic anatomy and assessment of the critical view of safety
Jun 21, 2021
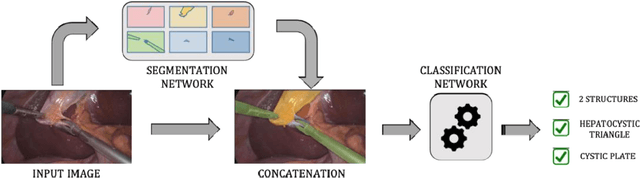
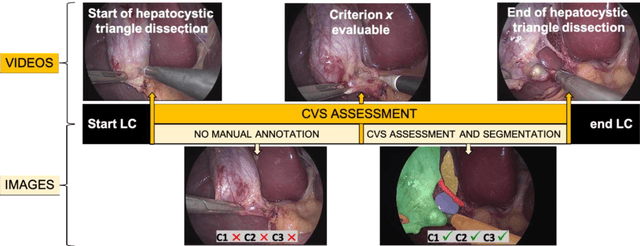
Minimally invasive image-guided surgery heavily relies on vision. Deep learning models for surgical video analysis could therefore support visual tasks such as assessing the critical view of safety (CVS) in laparoscopic cholecystectomy (LC), potentially contributing to surgical safety and efficiency. However, the performance, reliability and reproducibility of such models are deeply dependent on the quality of data and annotations used in their development. Here, we present a protocol, checklists, and visual examples to promote consistent annotation of hepatocystic anatomy and CVS criteria. We believe that sharing annotation guidelines can help build trustworthy multicentric datasets for assessing generalizability of performance, thus accelerating the clinical translation of deep learning models for surgical video analysis.