 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRB Minimization for RIS-aided mmWave Integrated Sensing and Communications
Jan 02, 2024In this paper, reconfigurable intelligent surface (RIS) is employed in a millimeter wave (mmWave) integrated sensing and communications (ISAC) system. To alleviate the multi-hop attenuation, the semi-self sensing RIS approach is adopted, wherein sensors are configured at the RIS to receive the radar echo signal. Focusing on the estimation accuracy, the Cramer-Rao bound (CRB) for estimating the direction-of-the-angles is derived as the metric for sensing performance. A joint optimization problem on hybrid beamforming and RIS phaseshifts is proposed to minimize the CRB, while maintaining satisfactory communication performance evaluated by the achievable data rate. The CRB minimization problem is first transformed as a more tractable form based on Fisher information matrix (FIM). To solve the complex non-convex problem, a double layer loop algorithm is proposed based on penalty concave-convex procedure (penalty-CCCP) and block coordinate descent (BCD) method with two sub-problems. Successive convex approximation (SCA) algorithm and second order cone (SOC) constraints are employed to tackle the non-convexity in the hybrid beamforming optimization. To optimize the unit modulus constrained analog beamforming and phase shifts, manifold optimization (MO) is adopted. Finally, the numerical results verify the effectiveness of the proposed CRB minimization algorithm, and show the performance improvement compared with other baselines. Additionally, the proposed hybrid beamforming algorithm can achieve approximately 96% of the sensing performance exhibited by the full digital approach within only a limited number of radio frequency (RF) chains.
Mutual Information-Based Integrated Sensing and Communications: A WMMSE Framework
Oct 19, 2023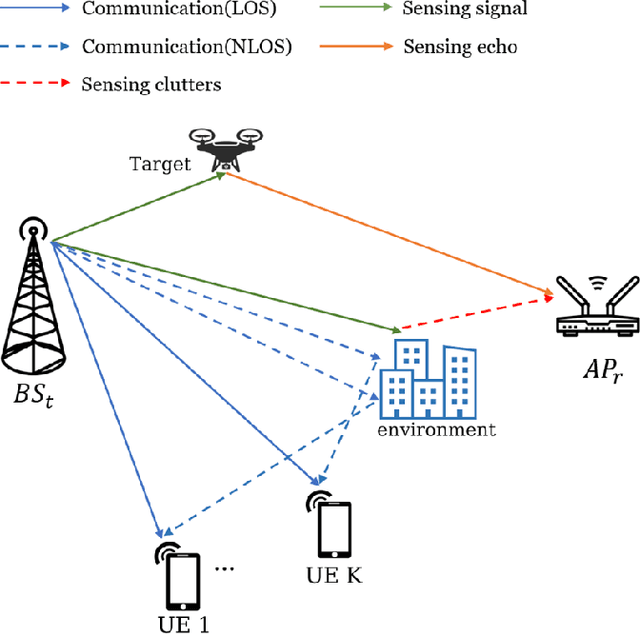
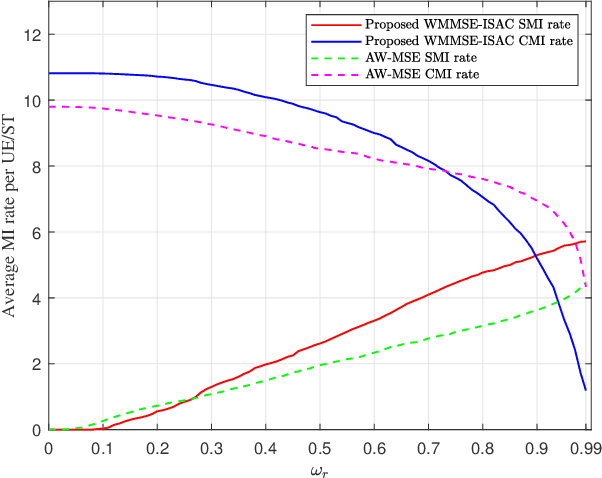
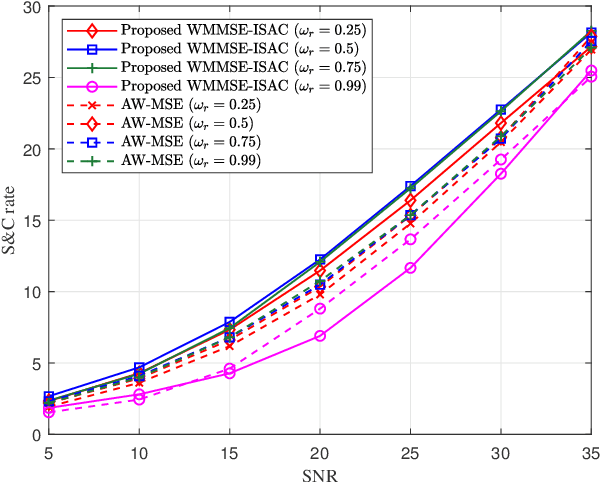
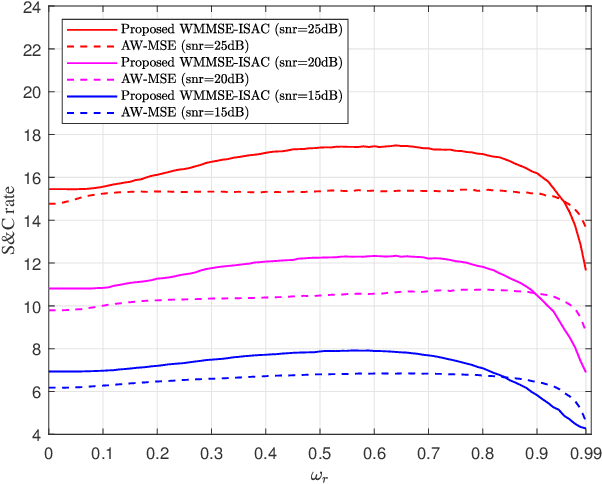
In this letter, a weighted minimum mean square error (WMMSE) empowered integrated sensing and communication (ISAC) system is investigated. One transmitting base station and one receiving wireless access point are considered to serve multiple users a sensing target. Based on the theory of mutual-information (MI), communication MI and sensing MI rate are utilized as the performance metrics under the presence of clutters. In particular, we propose an novel MI-based WMMSE-ISAC method by developing a unique transceiver design mechanism to maximize the weighted sensing and communication sum-rate of this system. Such a maximization process is achieved by utilizing the classical method -- WMMSE, aiming to better manage the effect of sensing clutters and the interference among users. Numerical results show the effectiveness of our proposed method, and the performance trade-off between sensing and communication is also validated.
Multi-resolution Monocular Depth Map Fusion by Self-supervised Gradient-based Composition
Dec 03, 2022
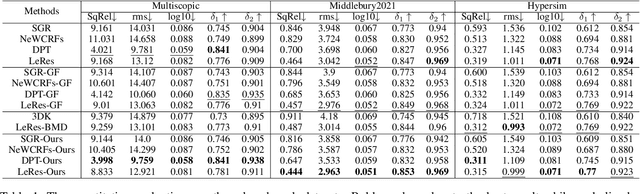
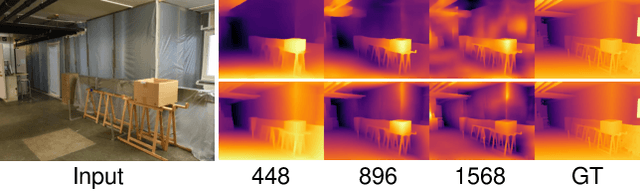
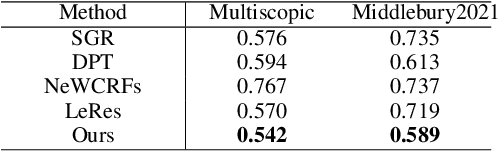
Monocular depth estimation is a challenging problem on which deep neural networks have demonstrated great potential. However, depth maps predicted by existing deep models usually lack fine-grained details due to the convolution operations and the down-samplings in networks. We find that increasing input resolution is helpful to preserve more local details while the estimation at low resolution is more accurate globally. Therefore, we propose a novel depth map fusion module to combine the advantages of estimations with multi-resolution inputs. Instead of merging the low- and high-resolution estimations equally, we adopt the core idea of Poisson fusion, trying to implant the gradient domain of high-resolution depth into the low-resolution depth. While classic Poisson fusion requires a fusion mask as supervision, we propose a self-supervised framework based on guided image filtering. We demonstrate that this gradient-based composition performs much better at noisy immunity, compared with the state-of-the-art depth map fusion method. Our lightweight depth fusion is one-shot and runs in real-time, making our method 80X faster than a state-of-the-art depth fusion method. Quantitative evaluations demonstrate that the proposed method can be integrated into many fully convolutional monocular depth estimation backbones with a significant performance boost, leading to state-of-the-art results of detail enhancement on depth maps.
Wound Segmentation with Dynamic Illumination Correction and Dual-view Semantic Fusion
Jul 12, 2022
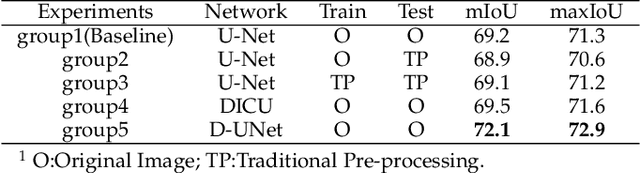
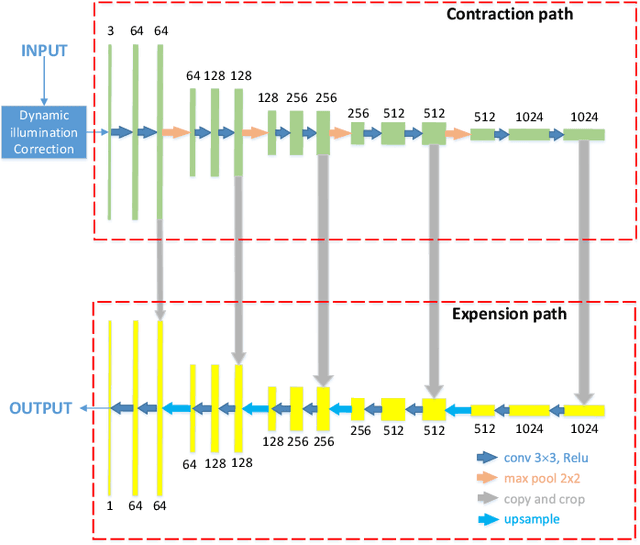

Wound image segmentation is a critical component for the clinical diagnosis and in-time treatment of wounds. Recently, deep learning has become the mainstream methodology for wound image segmentation. However, the pre-processing of the wound image, such as the illumination correction, is required before the training phase as the performance can be greatly improved. The correction procedure and the training of deep models are independent of each other, which leads to sub-optimal segmentation performance as the fixed illumination correction may not be suitable for all images. To address aforementioned issues, an end-to-end dual-view segmentation approach was proposed in this paper, by incorporating a learn-able illumination correction module into the deep segmentation models. The parameters of the module can be learned and updated during the training stage automatically, while the dual-view fusion can fully employ the features from both the raw images and the enhanced ones. To demonstrate the effectiveness and robustness of the proposed framework, the extensive experiments are conducted on the benchmark datasets. The encouraging results suggest that our framework can significantly improve the segmentation performance, compared to the state-of-the-art methods.