 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWound Segmentation with Dynamic Illumination Correction and Dual-view Semantic Fusion
Paper and Code
Jul 12, 2022
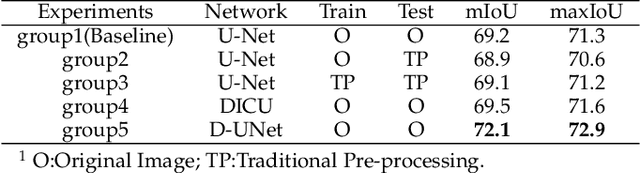
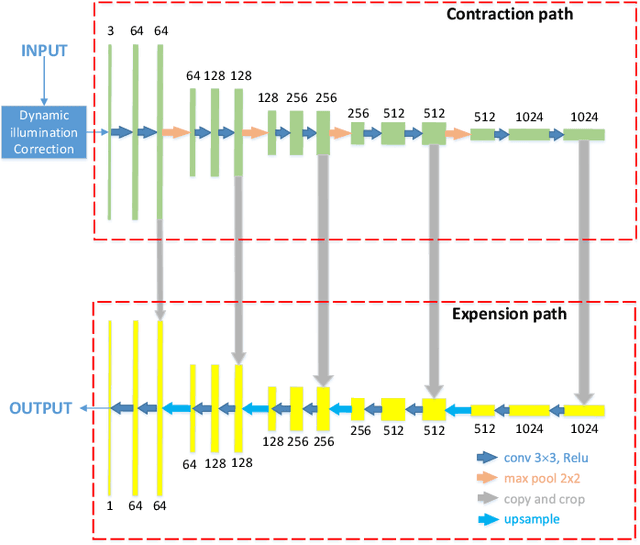

Wound image segmentation is a critical component for the clinical diagnosis and in-time treatment of wounds. Recently, deep learning has become the mainstream methodology for wound image segmentation. However, the pre-processing of the wound image, such as the illumination correction, is required before the training phase as the performance can be greatly improved. The correction procedure and the training of deep models are independent of each other, which leads to sub-optimal segmentation performance as the fixed illumination correction may not be suitable for all images. To address aforementioned issues, an end-to-end dual-view segmentation approach was proposed in this paper, by incorporating a learn-able illumination correction module into the deep segmentation models. The parameters of the module can be learned and updated during the training stage automatically, while the dual-view fusion can fully employ the features from both the raw images and the enhanced ones. To demonstrate the effectiveness and robustness of the proposed framework, the extensive experiments are conducted on the benchmark datasets. The encouraging results suggest that our framework can significantly improve the segmentation performance, compared to the state-of-the-art methods.