 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Shared Geometry of Difficulty in Multilingual Language Models
Jan 19, 2026Predicting problem-difficulty in large language models (LLMs) refers to estimating how difficult a task is according to the model itself, typically by training linear probes on its internal representations. In this work, we study the multilingual geometry of problem-difficulty in LLMs by training linear probes using the AMC subset of the Easy2Hard benchmark, translated into 21 languages. We found that difficulty-related signals emerge at two distinct stages of the model internals, corresponding to shallow (early-layers) and deep (later-layers) internal representations, that exhibit functionally different behaviors. Probes trained on deep representations achieve high accuracy when evaluated on the same language but exhibit poor cross-lingual generalization. In contrast, probes trained on shallow representations generalize substantially better across languages, despite achieving lower within-language performance. Together, these results suggest that LLMs first form a language-agnostic representation of problem difficulty, which subsequently becomes language-specific. This closely aligns with existing findings in LLM interpretability showing that models tend to operate in an abstract conceptual space before producing language-specific outputs. We demonstrate that this two-stage representational process extends beyond semantic content to high-level meta-cognitive properties such as problem-difficulty estimation.
Spotting Persuasion: A Low-cost Model for Persuasion Detection in Political Ads on Social Media
Mar 18, 2025



In the realm of political advertising, persuasion operates as a pivotal element within the broader framework of propaganda, exerting profound influences on public opinion and electoral outcomes. In this paper, we (1) introduce a lightweight model for persuasive text detection that achieves state-of-the-art performance in Subtask 3 of SemEval 2023 Task 3, while significantly reducing the computational resource requirements; and (2) leverage the proposed model to gain insights into political campaigning strategies on social media platforms by applying it to a real-world dataset we curated, consisting of Facebook political ads from the 2022 Australian Federal election campaign. Our study shows how subtleties can be found in persuasive political advertisements and presents a pragmatic approach to detect and analyze such strategies with limited resources, enhancing transparency in social media political campaigns.
SubData: A Python Library to Collect and Combine Datasets for Evaluating LLM Alignment on Downstream Tasks
Dec 21, 2024With the release of ever more capable large language models (LLMs), researchers in NLP and related disciplines have started to explore the usability of LLMs for a wide variety of different annotation tasks. Very recently, a lot of this attention has shifted to tasks that are subjective in nature. Given that the latest generations of LLMs have digested and encoded extensive knowledge about different human subpopulations and individuals, the hope is that these models can be trained, tuned or prompted to align with a wide range of different human perspectives. While researchers already evaluate the success of this alignment via surveys and tests, there is a lack of resources to evaluate the alignment on what oftentimes matters the most in NLP; the actual downstream tasks. To fill this gap we present SubData, a Python library that offers researchers working on topics related to subjectivity in annotation tasks a convenient way of collecting, combining and using a range of suitable datasets.
Mapping and Influencing the Political Ideology of Large Language Models using Synthetic Personas
Dec 19, 2024



The analysis of political biases in large language models (LLMs) has primarily examined these systems as single entities with fixed viewpoints. While various methods exist for measuring such biases, the impact of persona-based prompting on LLMs' political orientation remains unexplored. In this work we leverage PersonaHub, a collection of synthetic persona descriptions, to map the political distribution of persona-based prompted LLMs using the Political Compass Test (PCT). We then examine whether these initial compass distributions can be manipulated through explicit ideological prompting towards diametrically opposed political orientations: right-authoritarian and left-libertarian. Our experiments reveal that synthetic personas predominantly cluster in the left-libertarian quadrant, with models demonstrating varying degrees of responsiveness when prompted with explicit ideological descriptors. While all models demonstrate significant shifts towards right-authoritarian positions, they exhibit more limited shifts towards left-libertarian positions, suggesting an asymmetric response to ideological manipulation that may reflect inherent biases in model training.
Optimizing LLMs with Direct Preferences: A Data Efficiency Perspective
Oct 22, 2024
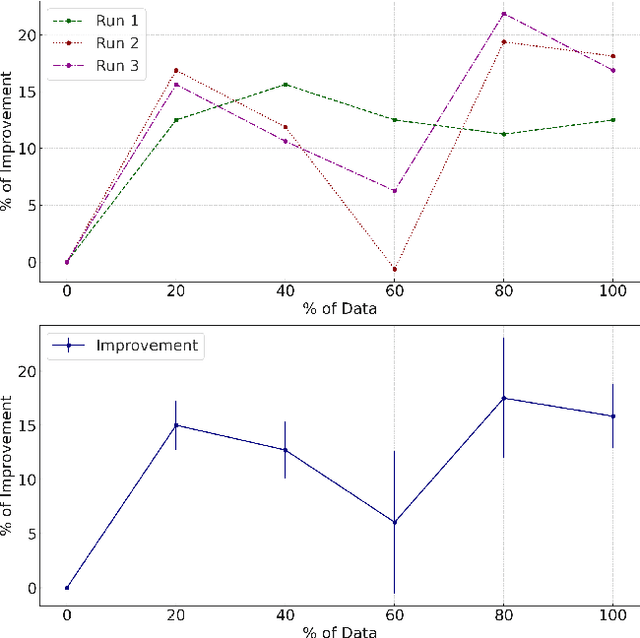
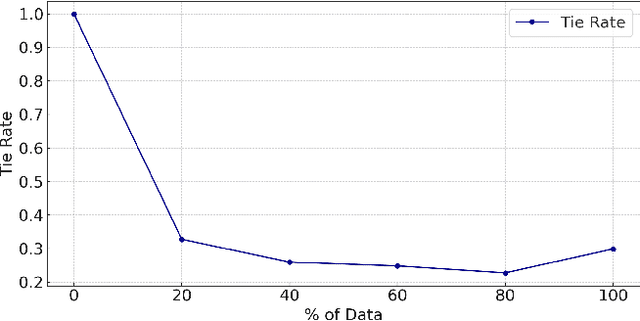

Aligning the output of Large Language Models (LLMs) with human preferences (e.g., by means of reinforcement learning with human feedback, or RLHF) is essential for ensuring their effectiveness in real-world scenarios. Despite significant advancements in LLM alignment techniques, the impact of different type of preference data on model performance has yet to be systematically explored. In this study, we investigate the scalability, data efficiency, and effectiveness of Direct Preference Optimization (DPO) in fine-tuning pre-trained LLMs, aiming to reduce their dependency on extensive amounts of preference data, which is expensive to collect. We (1) systematically compare the performance of models fine-tuned with varying percentages of a combined preference judgement dataset to define the improvement curve of DPO and assess its effectiveness in data-constrained environments; and (2) provide insights for the development of an optimal approach for selective preference data usage. Our study reveals that increasing the amount of data used for training generally enhances and stabilizes model performance. Moreover, the use of a combination of diverse datasets significantly improves model effectiveness. Furthermore, when models are trained separately using different types of prompts, models trained with conversational prompts outperformed those trained with question answering prompts.