 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model based Situational Dialogues for Second Language Learning
Mar 29, 2024In second language learning, scenario-based conversation practice is important for language learners to achieve fluency in speaking, but students often lack sufficient opportunities to practice their conversational skills with qualified instructors or native speakers. To bridge this gap, we propose situational dialogue models for students to engage in conversational practice. Our situational dialogue models are fine-tuned on large language models (LLMs), with the aim of combining the engaging nature of an open-ended conversation with the focused practice of scenario-based tasks. Leveraging the generalization capabilities of LLMs, we demonstrate that our situational dialogue models perform effectively not only on training topics but also on topics not encountered during training. This offers a promising solution to support a wide range of conversational topics without extensive manual work. Additionally, research in the field of dialogue systems still lacks reliable automatic evaluation metrics, leading to human evaluation as the gold standard (Smith et al., 2022), which is typically expensive. To address the limitations of existing evaluation methods, we present a novel automatic evaluation method that employs fine-tuned LLMs to efficiently and effectively assess the performance of situational dialogue models.
AnimateAnything: Fine-Grained Open Domain Image Animation with Motion Guidance
Dec 04, 2023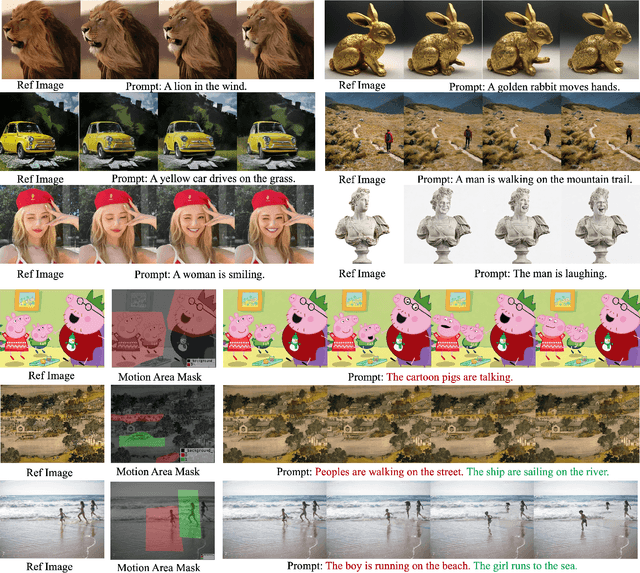
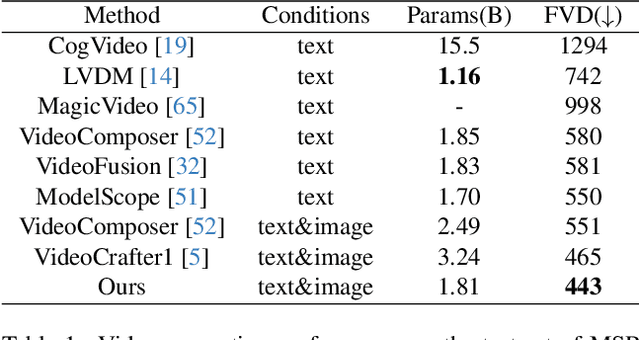
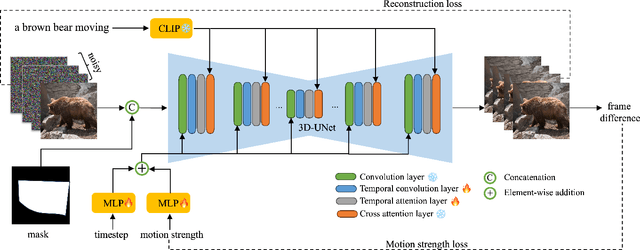
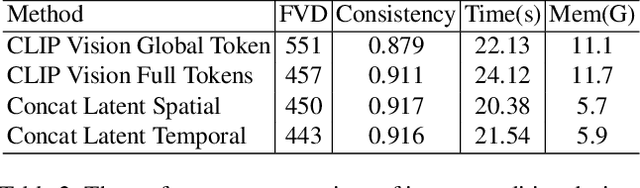
Image animation is a key task in computer vision which aims to generate dynamic visual content from static image. Recent image animation methods employ neural based rendering technique to generate realistic animations. Despite these advancements, achieving fine-grained and controllable image animation guided by text remains challenging, particularly for open-domain images captured in diverse real environments. In this paper, we introduce an open domain image animation method that leverages the motion prior of video diffusion model. Our approach introduces targeted motion area guidance and motion strength guidance, enabling precise control the movable area and its motion speed. This results in enhanced alignment between the animated visual elements and the prompting text, thereby facilitating a fine-grained and interactive animation generation process for intricate motion sequences. We validate the effectiveness of our method through rigorous experiments on an open-domain dataset, with the results showcasing its superior performance. Project page can be found at https://animationai.github.io/AnimateAnything.