 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model based Situational Dialogues for Second Language Learning
Mar 29, 2024In second language learning, scenario-based conversation practice is important for language learners to achieve fluency in speaking, but students often lack sufficient opportunities to practice their conversational skills with qualified instructors or native speakers. To bridge this gap, we propose situational dialogue models for students to engage in conversational practice. Our situational dialogue models are fine-tuned on large language models (LLMs), with the aim of combining the engaging nature of an open-ended conversation with the focused practice of scenario-based tasks. Leveraging the generalization capabilities of LLMs, we demonstrate that our situational dialogue models perform effectively not only on training topics but also on topics not encountered during training. This offers a promising solution to support a wide range of conversational topics without extensive manual work. Additionally, research in the field of dialogue systems still lacks reliable automatic evaluation metrics, leading to human evaluation as the gold standard (Smith et al., 2022), which is typically expensive. To address the limitations of existing evaluation methods, we present a novel automatic evaluation method that employs fine-tuned LLMs to efficiently and effectively assess the performance of situational dialogue models.
Towards Self-supervised and Weight-preserving Neural Architecture Search
Jun 08, 2022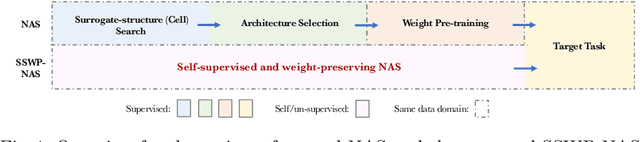
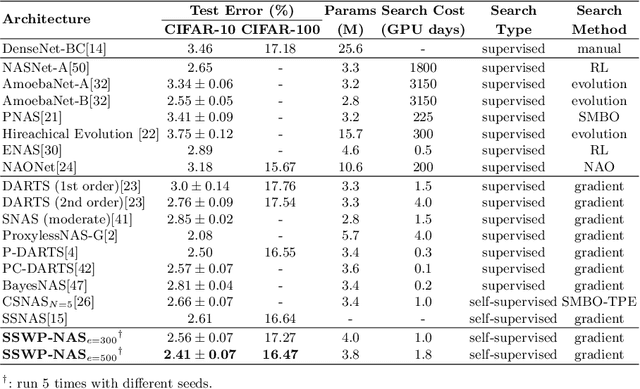
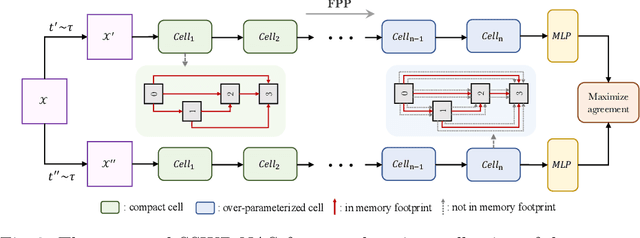
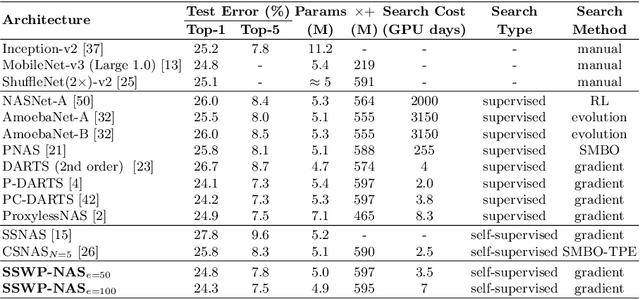
Neural architecture search (NAS) algorithms save tremendous labor from human experts. Recent advancements further reduce the computational overhead to an affordable level. However, it is still cumbersome to deploy the NAS techniques in real-world applications due to the fussy procedures and the supervised learning paradigm. In this work, we propose the self-supervised and weight-preserving neural architecture search (SSWP-NAS) as an extension of the current NAS framework by allowing the self-supervision and retaining the concomitant weights discovered during the search stage. As such, we simplify the workflow of NAS to a one-stage and proxy-free procedure. Experiments show that the architectures searched by the proposed framework achieve state-of-the-art accuracy on CIFAR-10, CIFAR-100, and ImageNet datasets without using manual labels. Moreover, we show that employing the concomitant weights as initialization consistently outperforms the random initialization and the two-stage weight pre-training method by a clear margin under semi-supervised learning scenarios. Codes are publicly available at https://github.com/LzVv123456/SSWP-NAS.