 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Precise Intent-Aligned VLA Aerial Navigation via Expert-Guided GRPO
Jun 01, 2026Vision-Language-Action (VLA) models offer a promising end-to-end paradigm for unmanned aerial vehicles (UAVs) to accomplish complex tasks specified by fine-grained instructions. However, standard supervised fine-tuning (SFT) suffers from data scarcity, limited generalization, and weak supervision for nuanced and complicated human intents. Reinforcement fine-tuning offers a natural way to mitigate these challenges and align policy behaviors with human intents through designable feedback, but applying it to aerial navigation remains challenging due to inefficient exploration in expansive continuous spaces. To address these challenges, we introduce an efficient reinforcement learning (RL) framework for VLA-based aerial navigation. At its core, we propose EG-GRPO (Expert-Guided Group Relative Policy Optimization) to augment online rollouts with few-shot expert data. Additionally, we design a heterogeneous pipeline enabling parallel simulation and inference, which reduces rollout time by 43.5%. Across multiple tasks specified by complex human intents, EG-GRPO improves the success rate to 2.13x that of the SFT baseline, while improving intent alignment performance by 60.9%. These results demonstrate that our framework can move aerial navigation toward precise intent-aligned flight.
Measurement-Adapted Eigentask Representations for Photon-Limited Optical Readout
May 11, 2026Optical readout in low-light imaging is fundamentally limited by measurement noise, including photon shot noise, detector noise, and quantization error. In this regime, downstream inference depends not only on the optical front end, but also on how noisy high-dimensional sensor measurements are represented before classification or decision-making. Here we show that eigentasks provide a measurement-adapted representation for optical sensor outputs by ordering readout features according to their resolvability under noise. Using experimental data from a lens-based optical imaging system and a reanalysis of published data from a single-photon-detection neural network, we find that eigentask representations frequently outperform standard baselines including principal component analysis and filtering-based compression. The advantage is most pronounced in photon-limited, few-shot, and higher-difficulty classification regimes. In few-shot MPEG-7 classification, for example, the advantage over other methods reaches about 10 percentage points as the number of classes increases. In these settings, eigentasks yield more informative low-dimensional features and improve sample-efficient downstream learning. These results identify measurement-adapted representation as a promising strategy for optical inference when photon budget, acquisition time, and task complexity are constrained.
Vision-Language-Action in Robotics: A Survey of Datasets, Benchmarks, and Data Engines
Apr 24, 2026Despite remarkable progress in Vision--Language--Action (VLA) models, a central bottleneck remains underexamined: the data infrastructure that underlies embodied learning. In this survey, we argue that future advances in VLA will depend less on model architecture and more on the co-design of high-fidelity data engines and structured evaluation protocols. To this end, we present a systematic, data-centric analysis of VLA research organized around three pillars: datasets, benchmarks, and data engines. For datasets, we categorize real-world and synthetic corpora along embodiment diversity, modality composition, and action space formulation, revealing a persistent fidelity-cost trade-off that fundamentally constrains large-scale collection. For benchmarks, we analyze task complexity and environment structure jointly, exposing structural gaps in compositional generalization and long-horizon reasoning evaluation that existing protocols fail to address. For data engines, we examine simulation-based, video-reconstruction, and automated task-generation paradigms, identifying their shared limitations in physical grounding and sim-to-real transfer. Synthesizing these analyses, we distill four open challenges: representation alignment, multimodal supervision, reasoning assessment, and scalable data generation. Addressing them, we argue, requires treating data infrastructure as a first-class research problem rather than a background concern.
Precise Aggressive Aerial Maneuvers with Sensorimotor Policies
Apr 07, 2026Precise aggressive maneuvers with lightweight onboard sensors remains a key bottleneck in fully exploiting the maneuverability of drones. Such maneuvers are critical for expanding the systems' accessible area by navigating through narrow openings in the environment. Among the most relevant problems, a representative one is aggressive traversal through narrow gaps with quadrotors under SE(3) constraints, which require the quadrotors to leverage a momentary tilted attitude and the asymmetry of the airframe to navigate through gaps. In this paper, we achieve such maneuvers by developing sensorimotor policies directly mapping onboard vision and proprioception into low-level control commands. The policies are trained using reinforcement learning (RL) with end-to-end policy distillation in simulation. We mitigate the fundamental hardness of model-free RL's exploration on the restricted solution space with an initialization strategy leveraging trajectories generated by a model-based planner. Careful sim-to-real design allows the policy to control a quadrotor through narrow gaps with low clearances and high repeatability. For instance, the proposed method enables a quadrotor to navigate a rectangular gap at a 5 cm clearance, tilted at up to 90-degree orientation, without knowledge of the gap's position or orientation. Without training on dynamic gaps, the policy can reactively servo the quadrotor to traverse through a moving gap. The proposed method is also validated by training and deploying policies on challenging tracks of narrow gaps placed closely. The flexibility of the policy learning method is demonstrated by developing policies for geometrically diverse gaps, without relying on manually defined traversal poses and visual features.
Whole-Body Control Through Narrow Gaps From Pixels To Action
Sep 02, 2024


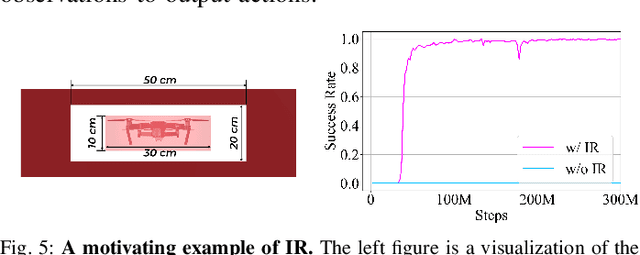
Flying through body-size narrow gaps in the environment is one of the most challenging moments for an underactuated multirotor. We explore a purely data-driven method to master this flight skill in simulation, where a neural network directly maps pixels and proprioception to continuous low-level control commands. This learned policy enables whole-body control through gaps with different geometries demanding sharp attitude changes (e.g., near-vertical roll angle). The policy is achieved by successive model-free reinforcement learning (RL) and online observation space distillation. The RL policy receives (virtual) point clouds of the gaps' edges for scalable simulation and is then distilled into the high-dimensional pixel space. However, this flight skill is fundamentally expensive to learn by exploring due to restricted feasible solution space. We propose to reset the agent as states on the trajectories by a model-based trajectory optimizer to alleviate this problem. The presented training pipeline is compared with baseline methods, and ablation studies are conducted to identify the key ingredients of our method. The immediate next step is to scale up the variation of gap sizes and geometries in anticipation of emergent policies and demonstrate the sim-to-real transformation.
Large Language Model based Situational Dialogues for Second Language Learning
Mar 29, 2024In second language learning, scenario-based conversation practice is important for language learners to achieve fluency in speaking, but students often lack sufficient opportunities to practice their conversational skills with qualified instructors or native speakers. To bridge this gap, we propose situational dialogue models for students to engage in conversational practice. Our situational dialogue models are fine-tuned on large language models (LLMs), with the aim of combining the engaging nature of an open-ended conversation with the focused practice of scenario-based tasks. Leveraging the generalization capabilities of LLMs, we demonstrate that our situational dialogue models perform effectively not only on training topics but also on topics not encountered during training. This offers a promising solution to support a wide range of conversational topics without extensive manual work. Additionally, research in the field of dialogue systems still lacks reliable automatic evaluation metrics, leading to human evaluation as the gold standard (Smith et al., 2022), which is typically expensive. To address the limitations of existing evaluation methods, we present a novel automatic evaluation method that employs fine-tuned LLMs to efficiently and effectively assess the performance of situational dialogue models.