 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserve Support, Not Correspondence: Dynamic Routing for Offline Reinforcement Learning
Apr 24, 2026One-step offline RL actors are attractive because they avoid backpropagating through long iterative samplers and keep inference cheap, but they still have to improve under a critic without drifting away from actions that the dataset can support. In recent one-step extraction pipelines, a strong iterative teacher provides one target action for each latent draw, and the same student output is asked to do both jobs: move toward higher Q and stay near that paired endpoint. If those two directions disagree, the loss resolves them as a compromise on that same sample, even when a nearby better action remains locally supported by the data. We propose DROL, a latent-conditioned one-step actor trained with top-1 dynamic routing. For each state, the actor samples $K$ candidate actions from a bounded latent prior, assigns each dataset action to its nearest candidate, and updates only that winner with Behavior Cloning and critic guidance. Because the routing is recomputed from the current candidate geometry, ownership of a supported region can shift across candidates over the course of learning. This gives a one-step actor room to make local improvements that pointwise extraction struggles to capture, while retaining single-pass inference at test time. On OGBench and D4RL, DROL is competitive with the one-step FQL baseline, improving many OGBench task groups while remaining strong on both AntMaze and Adroit. Project page: https://muzhancun.github.io/preprints/DROL.
System Design for Maintaining Internal State Consistency in Long-Horizon Robotic Tabletop Games
Mar 26, 2026Long-horizon tabletop games pose a distinct systems challenge for robotics: small perceptual or execution errors can invalidate accumulated task state, propagate across decision-making modules, and ultimately derail interaction. This paper studies how to maintain internal state consistency in turn-based, multi-human robotic tabletop games through deliberate system design rather than isolated component improvement. Using Mahjong as a representative long-horizon setting, we present an integrated architecture that explicitly maintains perceptual, execution, and interaction state, partitions high-level semantic reasoning from time-critical perception and control, and incorporates verified action primitives with tactile-triggered recovery to prevent premature state corruption. We further introduce interaction-level monitoring mechanisms to detect turn violations and hidden-information breaches that threaten execution assumptions. Beyond demonstrating complete-game operation, we provide an empirical characterization of failure modes, recovery effectiveness, cross-module error propagation, and hardware-algorithm trade-offs observed during deployment. Our results show that explicit partitioning, monitored state transitions, and recovery mechanisms are critical for sustaining executable consistency over extended play, whereas monolithic or unverified pipelines lead to measurable degradation in end-to-end reliability. The proposed system serves as an empirical platform for studying system-level design principles in long-horizon, turn-based interaction.
Optimizing Latent Goal by Learning from Trajectory Preference
Dec 03, 2024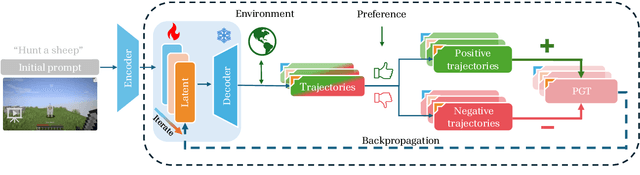
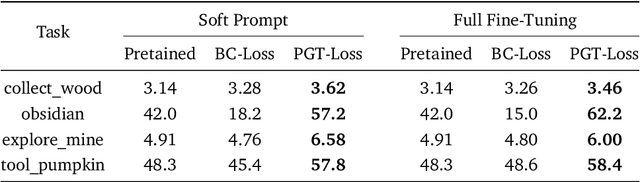
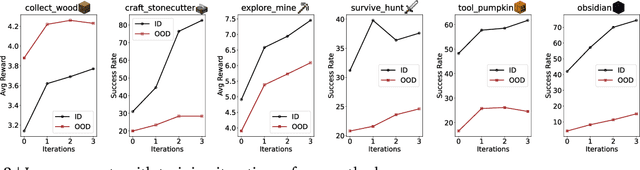
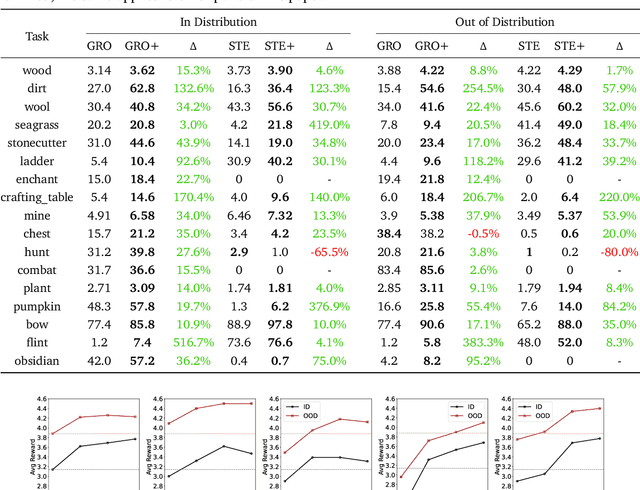
A glowing body of work has emerged focusing on instruction-following policies for open-world agents, aiming to better align the agent's behavior with human intentions. However, the performance of these policies is highly susceptible to the initial prompt, which leads to extra efforts in selecting the best instructions. We propose a framework named Preference Goal Tuning (PGT). PGT allows an instruction following policy to interact with the environment to collect several trajectories, which will be categorized into positive and negative samples based on preference. Then we use preference learning to fine-tune the initial goal latent representation with the categorized trajectories while keeping the policy backbone frozen. The experiment result shows that with minimal data and training, PGT achieves an average relative improvement of 72.0% and 81.6% over 17 tasks in 2 different foundation policies respectively, and outperforms the best human-selected instructions. Moreover, PGT surpasses full fine-tuning in the out-of-distribution (OOD) task-execution environments by 13.4%, indicating that our approach retains strong generalization capabilities. Since our approach stores a single latent representation for each task independently, it can be viewed as an efficient method for continual learning, without the risk of catastrophic forgetting or task interference. In short, PGT enhances the performance of agents across nearly all tasks in the Minecraft Skillforge benchmark and demonstrates robustness to the execution environment.
Whole-Body Control Through Narrow Gaps From Pixels To Action
Sep 02, 2024


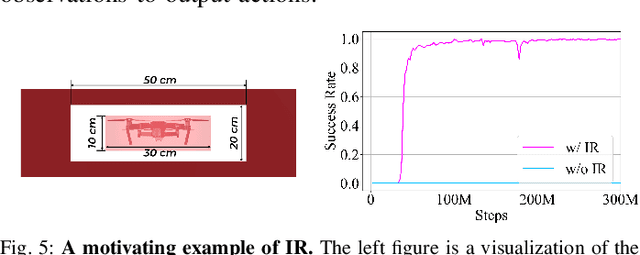
Flying through body-size narrow gaps in the environment is one of the most challenging moments for an underactuated multirotor. We explore a purely data-driven method to master this flight skill in simulation, where a neural network directly maps pixels and proprioception to continuous low-level control commands. This learned policy enables whole-body control through gaps with different geometries demanding sharp attitude changes (e.g., near-vertical roll angle). The policy is achieved by successive model-free reinforcement learning (RL) and online observation space distillation. The RL policy receives (virtual) point clouds of the gaps' edges for scalable simulation and is then distilled into the high-dimensional pixel space. However, this flight skill is fundamentally expensive to learn by exploring due to restricted feasible solution space. We propose to reset the agent as states on the trajectories by a model-based trajectory optimizer to alleviate this problem. The presented training pipeline is compared with baseline methods, and ablation studies are conducted to identify the key ingredients of our method. The immediate next step is to scale up the variation of gap sizes and geometries in anticipation of emergent policies and demonstrate the sim-to-real transformation.
Learning Agility Adaptation for Flight in Clutter
Mar 07, 2024



Animals learn to adapt agility of their movements to their capabilities and the environment they operate in. Mobile robots should also demonstrate this ability to combine agility and safety. The aim of this work is to endow flight vehicles with the ability of agility adaptation in prior unknown and partially observable cluttered environments. We propose a hierarchical learning and planning framework where we utilize both trial and error to comprehensively learn an agility policy with the vehicle's observation as the input, and well-established methods of model-based trajectory generation. Technically, we use online model-free reinforcement learning and a pre-training-fine-tuning reward scheme to obtain the deployable policy. The statistical results in simulation demonstrate the advantages of our method over the constant agility baselines and an alternative method in terms of flight efficiency and safety. In particular, the policy leads to intelligent behaviors, such as perception awareness, which distinguish it from other approaches. By deploying the policy to hardware, we verify that these advantages can be brought to the real world.