 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Latent Goal by Learning from Trajectory Preference
Paper and Code
Dec 03, 2024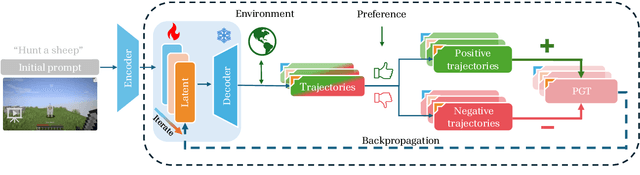
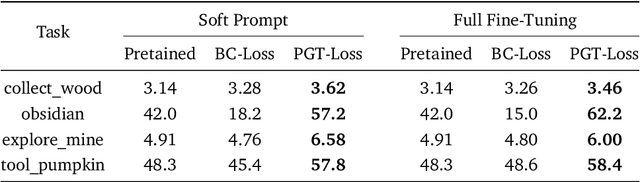
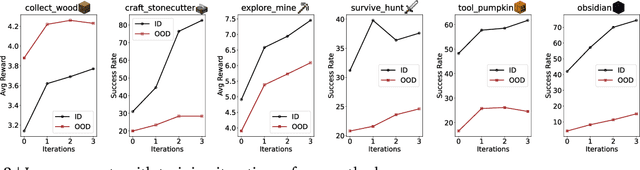
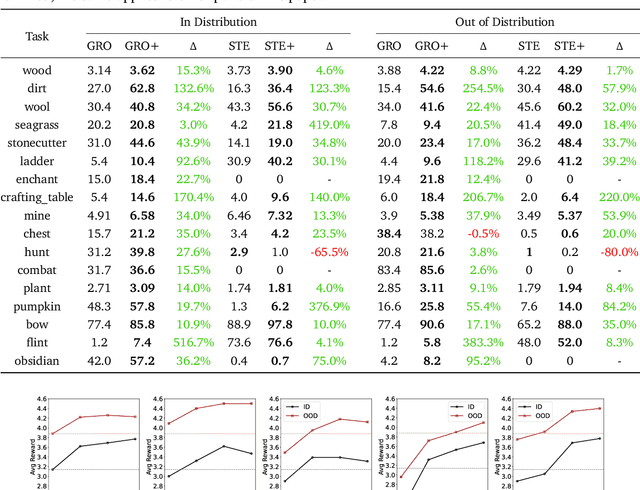
A glowing body of work has emerged focusing on instruction-following policies for open-world agents, aiming to better align the agent's behavior with human intentions. However, the performance of these policies is highly susceptible to the initial prompt, which leads to extra efforts in selecting the best instructions. We propose a framework named Preference Goal Tuning (PGT). PGT allows an instruction following policy to interact with the environment to collect several trajectories, which will be categorized into positive and negative samples based on preference. Then we use preference learning to fine-tune the initial goal latent representation with the categorized trajectories while keeping the policy backbone frozen. The experiment result shows that with minimal data and training, PGT achieves an average relative improvement of 72.0% and 81.6% over 17 tasks in 2 different foundation policies respectively, and outperforms the best human-selected instructions. Moreover, PGT surpasses full fine-tuning in the out-of-distribution (OOD) task-execution environments by 13.4%, indicating that our approach retains strong generalization capabilities. Since our approach stores a single latent representation for each task independently, it can be viewed as an efficient method for continual learning, without the risk of catastrophic forgetting or task interference. In short, PGT enhances the performance of agents across nearly all tasks in the Minecraft Skillforge benchmark and demonstrates robustness to the execution environment.