 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Memory-Aided World Models: Benchmarking via Spatial Consistency
May 29, 2025The ability to simulate the world in a spatially consistent manner is a crucial requirements for effective world models. Such a model enables high-quality visual generation, and also ensures the reliability of world models for downstream tasks such as simulation and planning. Designing a memory module is a crucial component for addressing spatial consistency: such a model must not only retain long-horizon observational information, but also enables the construction of explicit or implicit internal spatial representations. However, there are no dataset designed to promote the development of memory modules by explicitly enforcing spatial consistency constraints. Furthermore, most existing benchmarks primarily emphasize visual coherence or generation quality, neglecting the requirement of long-range spatial consistency. To bridge this gap, we construct a dataset and corresponding benchmark by sampling 150 distinct locations within the open-world environment of Minecraft, collecting about 250 hours (20 million frames) of loop-based navigation videos with actions. Our dataset follows a curriculum design of sequence lengths, allowing models to learn spatial consistency on increasingly complex navigation trajectories. Furthermore, our data collection pipeline is easily extensible to new Minecraft environments and modules. Four representative world model baselines are evaluated on our benchmark. Dataset, benchmark, and code are open-sourced to support future research.
Optimizing Latent Goal by Learning from Trajectory Preference
Dec 03, 2024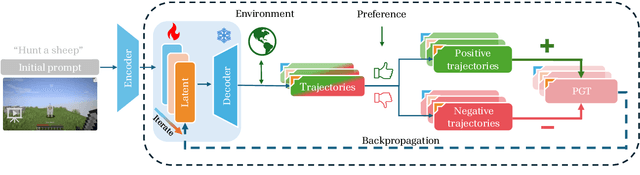
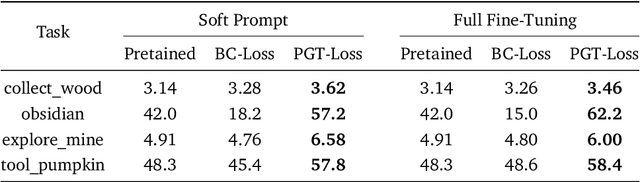
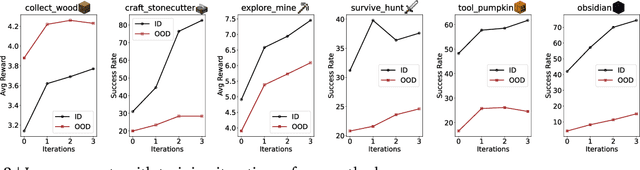
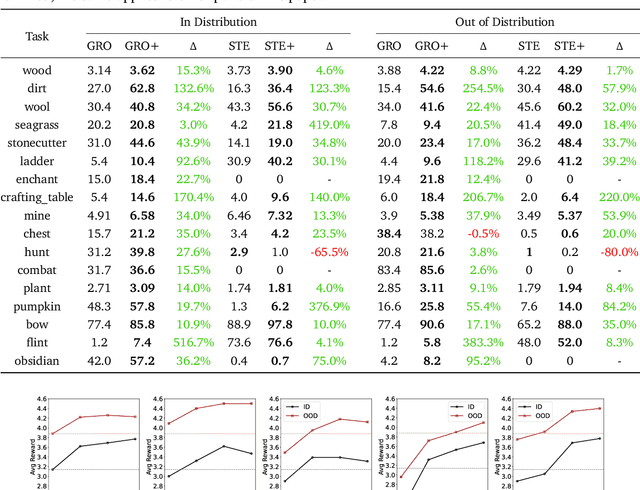
A glowing body of work has emerged focusing on instruction-following policies for open-world agents, aiming to better align the agent's behavior with human intentions. However, the performance of these policies is highly susceptible to the initial prompt, which leads to extra efforts in selecting the best instructions. We propose a framework named Preference Goal Tuning (PGT). PGT allows an instruction following policy to interact with the environment to collect several trajectories, which will be categorized into positive and negative samples based on preference. Then we use preference learning to fine-tune the initial goal latent representation with the categorized trajectories while keeping the policy backbone frozen. The experiment result shows that with minimal data and training, PGT achieves an average relative improvement of 72.0% and 81.6% over 17 tasks in 2 different foundation policies respectively, and outperforms the best human-selected instructions. Moreover, PGT surpasses full fine-tuning in the out-of-distribution (OOD) task-execution environments by 13.4%, indicating that our approach retains strong generalization capabilities. Since our approach stores a single latent representation for each task independently, it can be viewed as an efficient method for continual learning, without the risk of catastrophic forgetting or task interference. In short, PGT enhances the performance of agents across nearly all tasks in the Minecraft Skillforge benchmark and demonstrates robustness to the execution environment.
ROCKET-1: Master Open-World Interaction with Visual-Temporal Context Prompting
Oct 23, 2024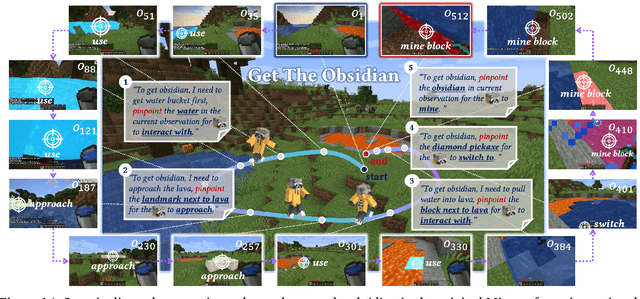
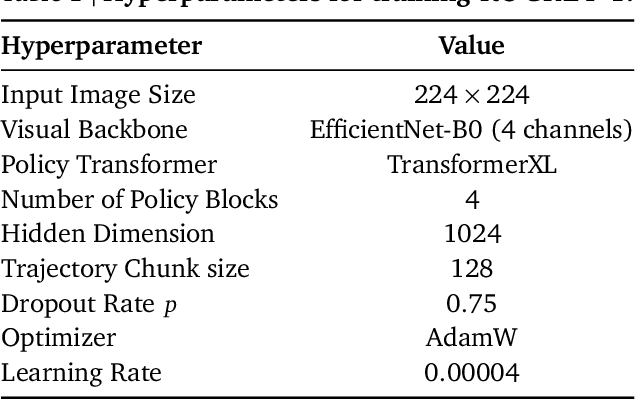
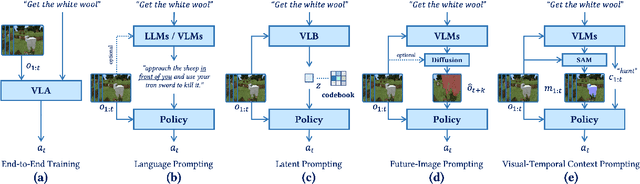
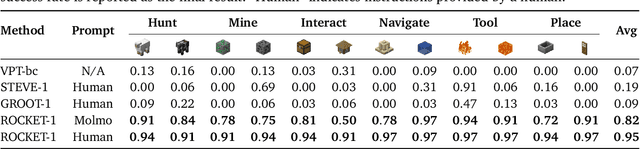
Vision-language models (VLMs) have excelled in multimodal tasks, but adapting them to embodied decision-making in open-world environments presents challenges. A key issue is the difficulty in smoothly connecting individual entities in low-level observations with abstract concepts required for planning. A common approach to address this problem is through the use of hierarchical agents, where VLMs serve as high-level reasoners that break down tasks into executable sub-tasks, typically specified using language and imagined observations. However, language often fails to effectively convey spatial information, while generating future images with sufficient accuracy remains challenging. To address these limitations, we propose visual-temporal context prompting, a novel communication protocol between VLMs and policy models. This protocol leverages object segmentation from both past and present observations to guide policy-environment interactions. Using this approach, we train ROCKET-1, a low-level policy that predicts actions based on concatenated visual observations and segmentation masks, with real-time object tracking provided by SAM-2. Our method unlocks the full potential of VLMs visual-language reasoning abilities, enabling them to solve complex creative tasks, especially those heavily reliant on spatial understanding. Experiments in Minecraft demonstrate that our approach allows agents to accomplish previously unattainable tasks, highlighting the effectiveness of visual-temporal context prompting in embodied decision-making. Codes and demos will be available on the project page: https://craftjarvis.github.io/ROCKET-1.