 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeFlow: Decoupling Manifold Modeling and Value Maximization for Offline Policy Extraction
Jan 15, 2026We present DeFlow, a decoupled offline RL framework that leverages flow matching to faithfully capture complex behavior manifolds. Optimizing generative policies is computationally prohibitive, typically necessitating backpropagation through ODE solvers. We address this by learning a lightweight refinement module within an explicit, data-derived trust region of the flow manifold, rather than sacrificing the iterative generation capability via single-step distillation. This way, we bypass solver differentiation and eliminate the need for balancing loss terms, ensuring stable improvement while fully preserving the flow's iterative expressivity. Empirically, DeFlow achieves superior performance on the challenging OGBench benchmark and demonstrates efficient offline-to-online adaptation.
Scalable Multi-Task Reinforcement Learning for Generalizable Spatial Intelligence in Visuomotor Agents
Jul 31, 2025While Reinforcement Learning (RL) has achieved remarkable success in language modeling, its triumph hasn't yet fully translated to visuomotor agents. A primary challenge in RL models is their tendency to overfit specific tasks or environments, thereby hindering the acquisition of generalizable behaviors across diverse settings. This paper provides a preliminary answer to this challenge by demonstrating that RL-finetuned visuomotor agents in Minecraft can achieve zero-shot generalization to unseen worlds. Specifically, we explore RL's potential to enhance generalizable spatial reasoning and interaction capabilities in 3D worlds. To address challenges in multi-task RL representation, we analyze and establish cross-view goal specification as a unified multi-task goal space for visuomotor policies. Furthermore, to overcome the significant bottleneck of manual task design, we propose automated task synthesis within the highly customizable Minecraft environment for large-scale multi-task RL training, and we construct an efficient distributed RL framework to support this. Experimental results show RL significantly boosts interaction success rates by $4\times$ and enables zero-shot generalization of spatial reasoning across diverse environments, including real-world settings. Our findings underscore the immense potential of RL training in 3D simulated environments, especially those amenable to large-scale task generation, for significantly advancing visuomotor agents' spatial reasoning.
ROCKET-2: Steering Visuomotor Policy via Cross-View Goal Alignment
Mar 04, 2025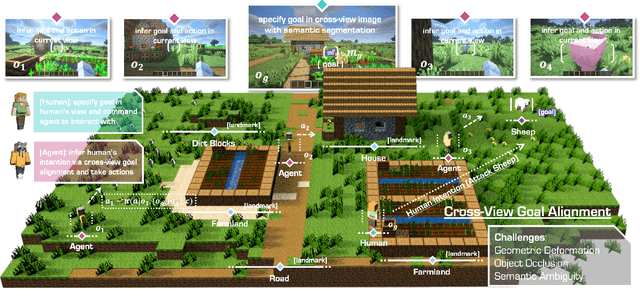
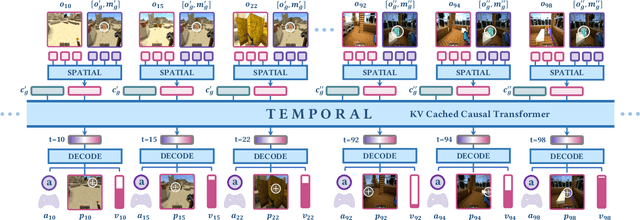

We aim to develop a goal specification method that is semantically clear, spatially sensitive, and intuitive for human users to guide agent interactions in embodied environments. Specifically, we propose a novel cross-view goal alignment framework that allows users to specify target objects using segmentation masks from their own camera views rather than the agent's observations. We highlight that behavior cloning alone fails to align the agent's behavior with human intent when the human and agent camera views differ significantly. To address this, we introduce two auxiliary objectives: cross-view consistency loss and target visibility loss, which explicitly enhance the agent's spatial reasoning ability. According to this, we develop ROCKET-2, a state-of-the-art agent trained in Minecraft, achieving an improvement in the efficiency of inference 3x to 6x. We show ROCKET-2 can directly interpret goals from human camera views for the first time, paving the way for better human-agent interaction.
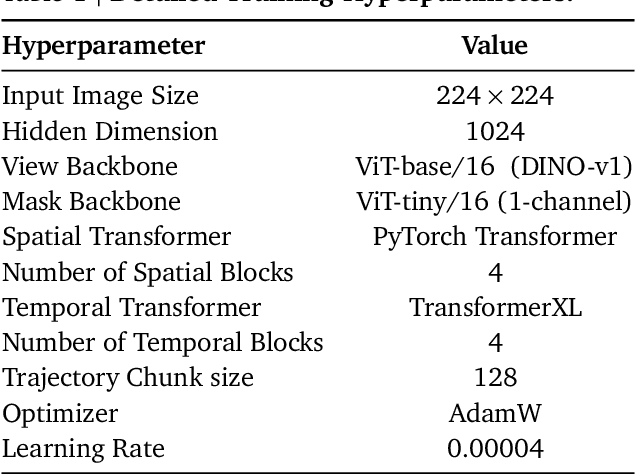
MineStudio: A Streamlined Package for Minecraft AI Agent Development
Dec 25, 2024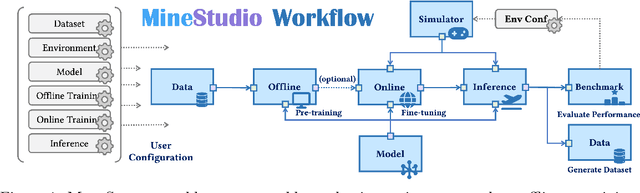
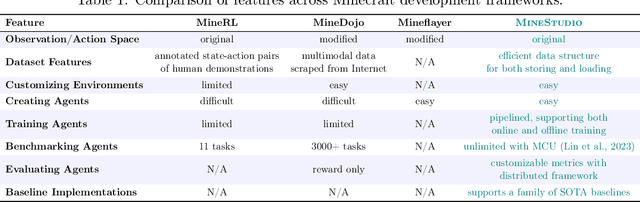
Minecraft has emerged as a valuable testbed for embodied intelligence and sequential decision-making research, yet the development and validation of novel agents remains hindered by significant engineering challenges. This paper presents MineStudio, an open-source software package designed to streamline embodied policy development in Minecraft. MineStudio represents the first comprehensive integration of seven critical engineering components: simulator, data, model, offline pretraining, online finetuning, inference, and benchmark, thereby allowing users to concentrate their efforts on algorithm innovation. We provide a user-friendly API design accompanied by comprehensive documentation and tutorials. The complete codebase is publicly available at https://github.com/CraftJarvis/MineStudio.
MinsStudio: A Streamlined Package for Minecraft AI Agent Development
Dec 24, 2024Minecraft has emerged as a valuable testbed for embodied intelligence and sequential decision-making research, yet the development and validation of novel agents remains hindered by significant engineering challenges. This paper presents MineStudio, an open-source software package designed to streamline embodied policy development in Minecraft. MineStudio represents the first comprehensive integration of seven critical engineering components: simulator, data, model, offline pretraining, online finetuning, inference, and benchmark, thereby allowing users to concentrate their efforts on algorithm innovation. We provide a user-friendly API design accompanied by comprehensive documentation and tutorials. The complete codebase is publicly available at https://github.com/CraftJarvis/MineStudio.
ROCKET-1: Master Open-World Interaction with Visual-Temporal Context Prompting
Oct 23, 2024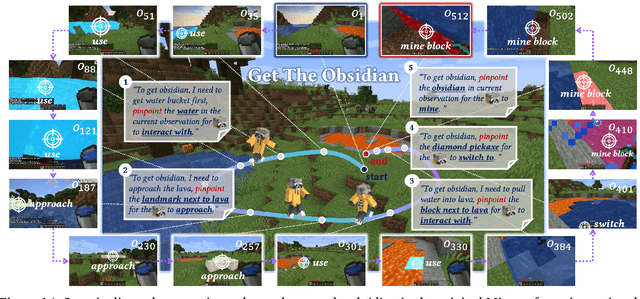
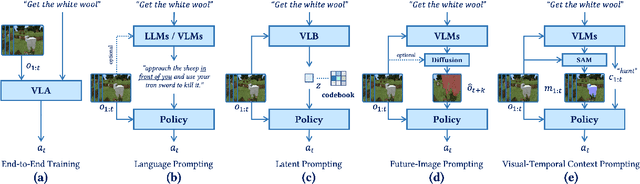
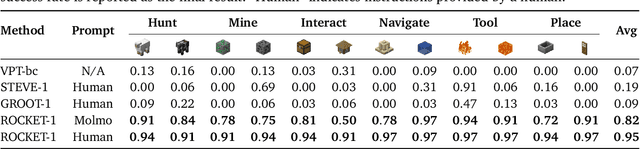
Vision-language models (VLMs) have excelled in multimodal tasks, but adapting them to embodied decision-making in open-world environments presents challenges. A key issue is the difficulty in smoothly connecting individual entities in low-level observations with abstract concepts required for planning. A common approach to address this problem is through the use of hierarchical agents, where VLMs serve as high-level reasoners that break down tasks into executable sub-tasks, typically specified using language and imagined observations. However, language often fails to effectively convey spatial information, while generating future images with sufficient accuracy remains challenging. To address these limitations, we propose visual-temporal context prompting, a novel communication protocol between VLMs and policy models. This protocol leverages object segmentation from both past and present observations to guide policy-environment interactions. Using this approach, we train ROCKET-1, a low-level policy that predicts actions based on concatenated visual observations and segmentation masks, with real-time object tracking provided by SAM-2. Our method unlocks the full potential of VLMs visual-language reasoning abilities, enabling them to solve complex creative tasks, especially those heavily reliant on spatial understanding. Experiments in Minecraft demonstrate that our approach allows agents to accomplish previously unattainable tasks, highlighting the effectiveness of visual-temporal context prompting in embodied decision-making. Codes and demos will be available on the project page: https://craftjarvis.github.io/ROCKET-1.
A Contextual Combinatorial Bandit Approach to Negotiation
Jun 30, 2024



Learning effective negotiation strategies poses two key challenges: the exploration-exploitation dilemma and dealing with large action spaces. However, there is an absence of learning-based approaches that effectively address these challenges in negotiation. This paper introduces a comprehensive formulation to tackle various negotiation problems. Our approach leverages contextual combinatorial multi-armed bandits, with the bandits resolving the exploration-exploitation dilemma, and the combinatorial nature handles large action spaces. Building upon this formulation, we introduce NegUCB, a novel method that also handles common issues such as partial observations and complex reward functions in negotiation. NegUCB is contextual and tailored for full-bandit feedback without constraints on the reward functions. Under mild assumptions, it ensures a sub-linear regret upper bound. Experiments conducted on three negotiation tasks demonstrate the superiority of our approach.
OmniJARVIS: Unified Vision-Language-Action Tokenization Enables Open-World Instruction Following Agents
Jun 27, 2024



We present OmniJARVIS, a novel Vision-Language-Action (VLA) model for open-world instruction-following agents in open-world Minecraft. Compared to prior works that either emit textual goals to separate controllers or produce the control command directly, OmniJARVIS seeks a different path to ensure both strong reasoning and efficient decision-making capabilities via unified tokenization of multimodal interaction data. First, we introduce a self-supervised approach to learn a behavior encoder that produces discretized tokens for behavior trajectories $\tau$ = {$o_0$, $a_0$, $\dots$} and an imitation learning (IL) policy decoder conditioned on these tokens. These additional behavior tokens will be augmented to the vocabulary of pretrained Multimodal Language Models (MLMs). With this encoder, we then pack long-term multimodal interactions involving task instructions, memories, thoughts, observations, textual responses, behavior trajectories, etc. into unified token sequences and model them with autoregressive transformers. Thanks to the semantically meaningful behavior tokens, the resulting VLA model, OmniJARVIS, can reason (by producing chain-of-thoughts), plan, answer questions, and act (by producing behavior tokens for the IL policy decoder). OmniJARVIS demonstrates excellent performances on a comprehensive collection of atomic, programmatic, and open-ended tasks in open-world Minecraft. Our analysis further unveils the crucial design principles in interaction data formation, unified tokenization, and its scaling potentials.