 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAP: Domain-aware Prompt Learning for Vision-and-Language Navigation
Nov 30, 2023



Following language instructions to navigate in unseen environments is a challenging task for autonomous embodied agents. With strong representation capabilities, pretrained vision-and-language models are widely used in VLN. However, most of them are trained on web-crawled general-purpose datasets, which incurs a considerable domain gap when used for VLN tasks. To address the problem, we propose a novel and model-agnostic domain-aware prompt learning (DAP) framework. For equipping the pretrained models with specific object-level and scene-level cross-modal alignment in VLN tasks, DAP applies a low-cost prompt tuning paradigm to learn soft visual prompts for extracting in-domain image semantics. Specifically, we first generate a set of in-domain image-text pairs with the help of the CLIP model. Then we introduce soft visual prompts in the input space of the visual encoder in a pretrained model. DAP injects in-domain visual knowledge into the visual encoder of the pretrained model in an efficient way. Experimental results on both R2R and REVERIE show the superiority of DAP compared to existing state-of-the-art methods.
Prompt-based Context- and Domain-aware Pretraining for Vision and Language Navigation
Sep 07, 2023With strong representation capabilities, pretrained vision-language models are widely used in vision and language navigation (VLN). However, most of them are trained on web-crawled general-purpose datasets, which incurs a considerable domain gap when used for VLN tasks. Another challenge for VLN is how the agent understands the contextual relations between actions on a trajectory and performs cross-modal alignment sequentially. In this paper, we propose a novel Prompt-bAsed coNtext- and Domain-Aware (PANDA) pretraining framework to address these problems. It performs prompting in two stages. In the domain-aware stage, we apply a low-cost prompt tuning paradigm to learn soft visual prompts from an in-domain dataset for equipping the pretrained models with object-level and scene-level cross-modal alignment in VLN tasks. Furthermore, in the context-aware stage, we design a set of hard context prompts to capture the sequence-level semantics and instill both out-of-context and contextual knowledge in the instruction into cross-modal representations. They enable further tuning of the pretrained models via contrastive learning. Experimental results on both R2R and REVERIE show the superiority of PANDA compared to previous state-of-the-art methods.
Visual Prompt Based Personalized Federated Learning
Mar 15, 2023



As a popular paradigm of distributed learning, personalized federated learning (PFL) allows personalized models to improve generalization ability and robustness by utilizing knowledge from all distributed clients. Most existing PFL algorithms tackle personalization in a model-centric way, such as personalized layer partition, model regularization, and model interpolation, which all fail to take into account the data characteristics of distributed clients. In this paper, we propose a novel PFL framework for image classification tasks, dubbed pFedPT, that leverages personalized visual prompts to implicitly represent local data distribution information of clients and provides that information to the aggregation model to help with classification tasks. Specifically, in each round of pFedPT training, each client generates a local personalized prompt related to local data distribution. Then, the local model is trained on the input composed of raw data and a visual prompt to learn the distribution information contained in the prompt. During model testing, the aggregated model obtains prior knowledge of the data distributions based on the prompts, which can be seen as an adaptive fine-tuning of the aggregation model to improve model performances on different clients. Furthermore, the visual prompt can be added as an orthogonal method to implement personalization on the client for existing FL methods to boost their performance. Experiments on the CIFAR10 and CIFAR100 datasets show that pFedPT outperforms several state-of-the-art (SOTA) PFL algorithms by a large margin in various settings.
Visual-and-Language Navigation: A Survey and Taxonomy
Sep 01, 2021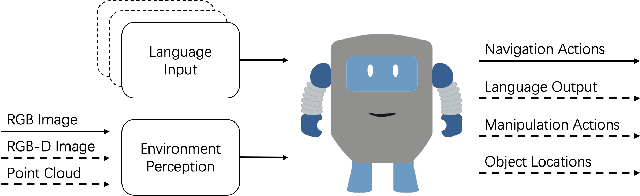
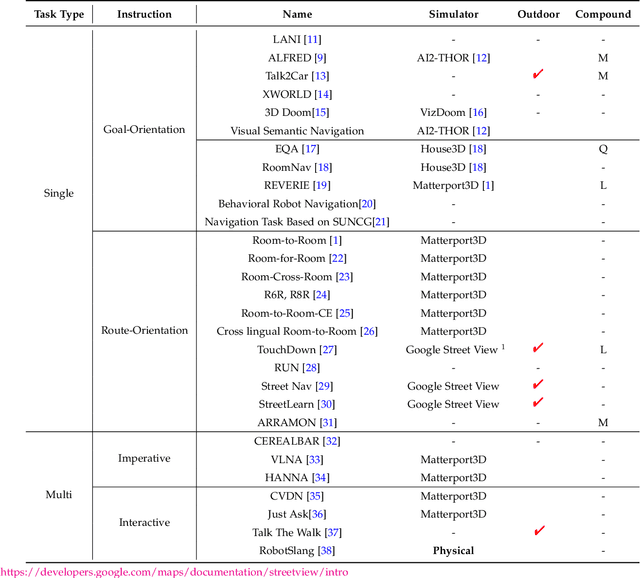
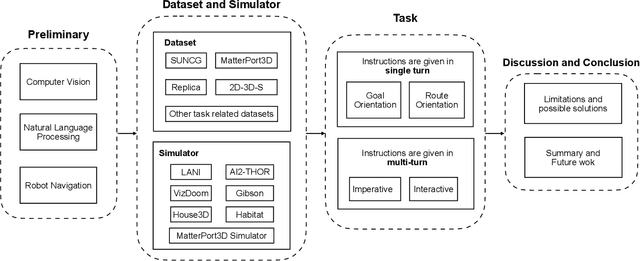

An agent that can understand natural-language instruction and carry out corresponding actions in the visual world is one of the long-term challenges of Artificial Intelligent (AI). Due to multifarious instructions from humans, it requires the agent can link natural language to vision and action in unstructured, previously unseen environments. If the instruction given by human is a navigation task, this challenge is called Visual-and-Language Navigation (VLN). It is a booming multi-disciplinary field of increasing importance and with extraordinary practicality. Instead of focusing on the details of specific methods, this paper provides a comprehensive survey on VLN tasks and makes a classification carefully according the different characteristics of language instructions in these tasks. According to when the instructions are given, the tasks can be divided into single-turn and multi-turn. For single-turn tasks, we further divided them into goal-orientation and route-orientation based on whether the instructions contain a route. For multi-turn tasks, we divided them into imperative task and interactive task based on whether the agent responses to the instructions. This taxonomy enable researchers to better grasp the key point of a specific task and identify directions for future research.
How to Evaluate Your Dialogue Models: A Review of Approaches
Aug 03, 2021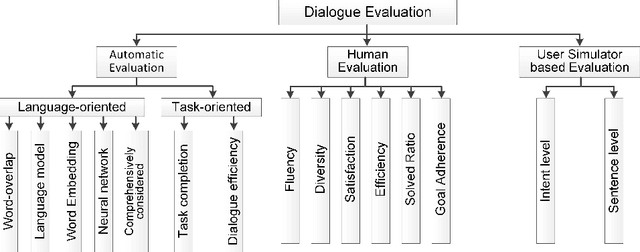

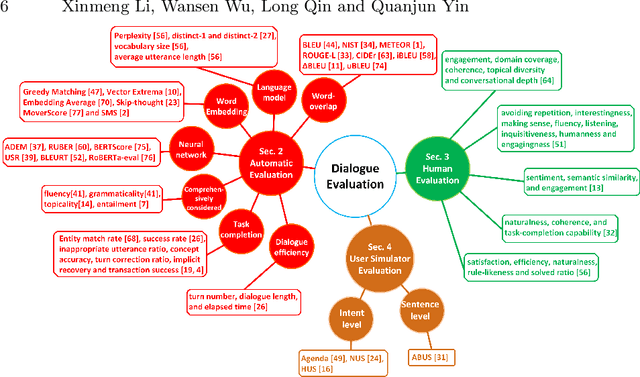
Evaluating the quality of a dialogue system is an understudied problem. The recent evolution of evaluation method motivated this survey, in which an explicit and comprehensive analysis of the existing methods is sought. We are first to divide the evaluation methods into three classes, i.e., automatic evaluation, human-involved evaluation and user simulator based evaluation. Then, each class is covered with main features and the related evaluation metrics. The existence of benchmarks, suitable for the evaluation of dialogue techniques are also discussed in detail. Finally, some open issues are pointed out to bring the evaluation method into a new frontier.