 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Spectral Prediction (ESP) Model for Metabolite Annotation
Mar 25, 2022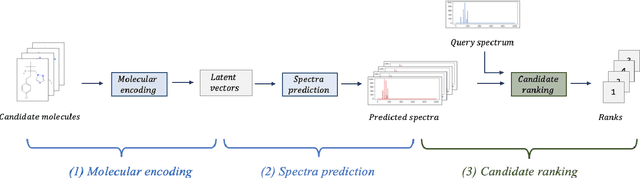
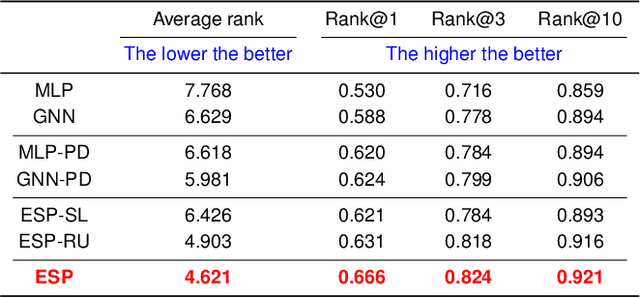
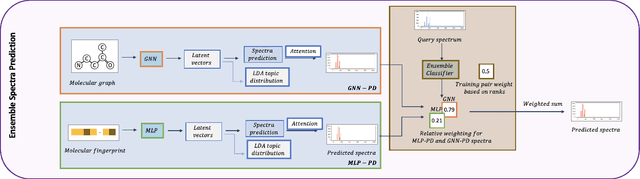
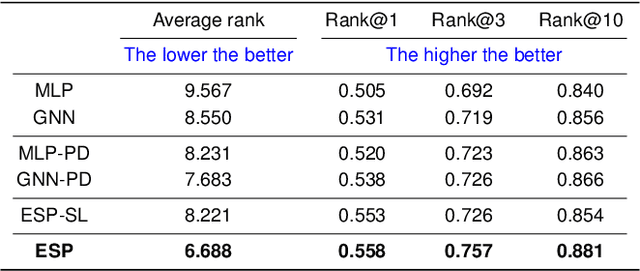
A key challenge in metabolomics is annotating measured spectra from a biological sample with chemical identities. Currently, only a small fraction of measurements can be assigned identities. Two complementary computational approaches have emerged to address the annotation problem: mapping candidate molecules to spectra, and mapping query spectra to molecular candidates. In essence, the candidate molecule with the spectrum that best explains the query spectrum is recommended as the target molecule. Despite candidate ranking being fundamental in both approaches, no prior works utilized rank learning tasks in determining the target molecule. We propose a novel machine learning model, Ensemble Spectral Prediction (ESP), for metabolite annotation. ESP takes advantage of prior neural network-based annotation models that utilize multilayer perceptron (MLP) networks and Graph Neural Networks (GNNs). Based on the ranking results of the MLP and GNN-based models, ESP learns a weighting for the outputs of MLP and GNN spectral predictors to generate a spectral prediction for a query molecule. Importantly, training data is stratified by molecular formula to provide candidate sets during model training. Further, baseline MLP and GNN models are enhanced by considering peak dependencies through multi-head attention mechanism and multi-tasking on spectral topic distributions. ESP improves average rank by 41% and 30% over the MLP and GNN baselines, respectively, demonstrating remarkable performance gain over state-of-the-art neural network approaches. We show that annotation performance, for ESP and other models, is a strong function of the number of molecules in the candidate set and their similarity to the target molecule.
Boost-RS: Boosted Embeddings for Recommender Systems and its Application to Enzyme-Substrate Interaction Prediction
Sep 28, 2021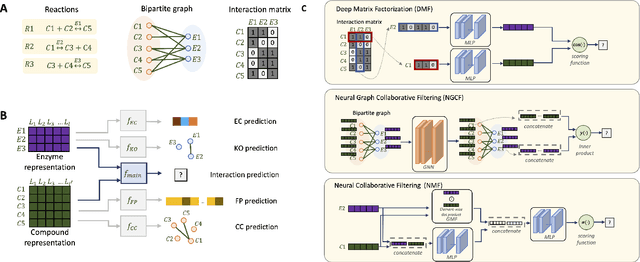
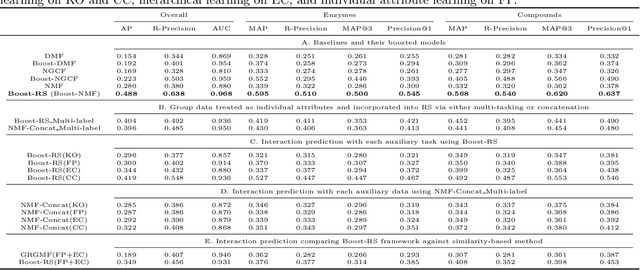
Despite experimental and curation efforts, the extent of enzyme promiscuity on substrates continues to be largely unexplored and under documented. Recommender systems (RS), which are currently unexplored for the enzyme-substrate interaction prediction problem, can be utilized to provide enzyme recommendations for substrates, and vice versa. The performance of Collaborative-Filtering (CF) recommender systems however hinges on the quality of embedding vectors of users and items (enzymes and substrates in our case). Importantly, enhancing CF embeddings with heterogeneous auxiliary data, specially relational data (e.g., hierarchical, pairwise, or groupings), remains a challenge. We propose an innovative general RS framework, termed Boost-RS, that enhances RS performance by "boosting" embedding vectors through auxiliary data. Specifically, Boost-RS is trained and dynamically tuned on multiple relevant auxiliary learning tasks Boost-RS utilizes contrastive learning tasks to exploit relational data. To show the efficacy of Boost-RS for the enzyme-substrate prediction interaction problem, we apply the Boost-RS framework to several baseline CF models. We show that each of our auxiliary tasks boosts learning of the embedding vectors, and that contrastive learning using Boost-RS outperforms attribute concatenation and multi-label learning. We also show that Boost-RS outperforms similarity-based models. Ablation studies and visualization of learned representations highlight the importance of using contrastive learning on some of the auxiliary data in boosting the embedding vectors.
Visual-and-Language Navigation: A Survey and Taxonomy
Sep 01, 2021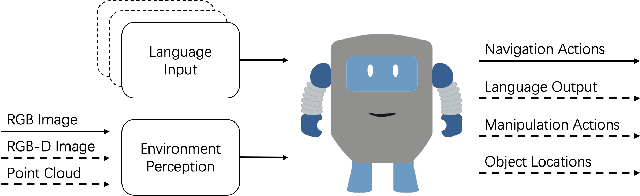
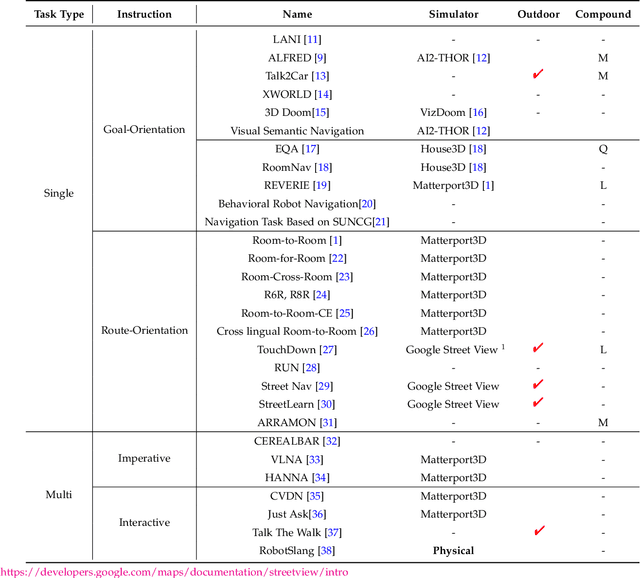
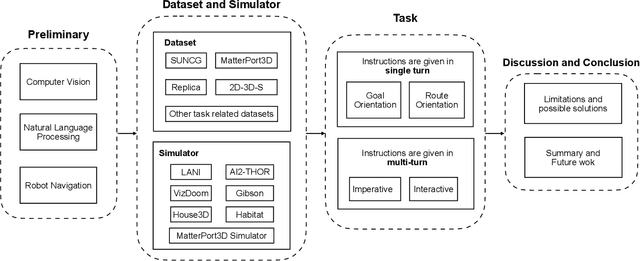

An agent that can understand natural-language instruction and carry out corresponding actions in the visual world is one of the long-term challenges of Artificial Intelligent (AI). Due to multifarious instructions from humans, it requires the agent can link natural language to vision and action in unstructured, previously unseen environments. If the instruction given by human is a navigation task, this challenge is called Visual-and-Language Navigation (VLN). It is a booming multi-disciplinary field of increasing importance and with extraordinary practicality. Instead of focusing on the details of specific methods, this paper provides a comprehensive survey on VLN tasks and makes a classification carefully according the different characteristics of language instructions in these tasks. According to when the instructions are given, the tasks can be divided into single-turn and multi-turn. For single-turn tasks, we further divided them into goal-orientation and route-orientation based on whether the instructions contain a route. For multi-turn tasks, we divided them into imperative task and interactive task based on whether the agent responses to the instructions. This taxonomy enable researchers to better grasp the key point of a specific task and identify directions for future research.
How to Evaluate Your Dialogue Models: A Review of Approaches
Aug 03, 2021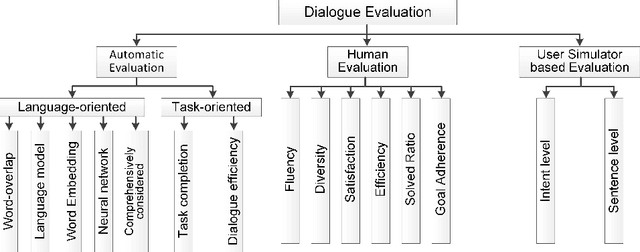

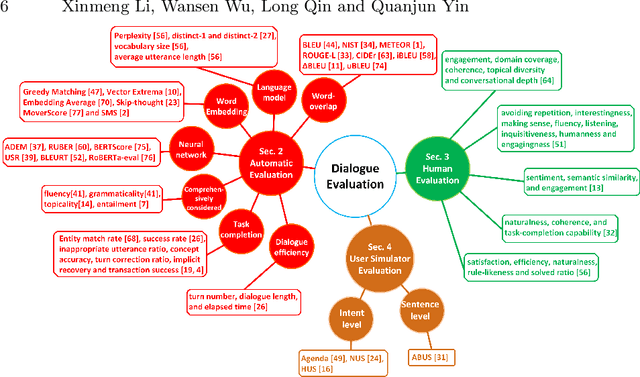
Evaluating the quality of a dialogue system is an understudied problem. The recent evolution of evaluation method motivated this survey, in which an explicit and comprehensive analysis of the existing methods is sought. We are first to divide the evaluation methods into three classes, i.e., automatic evaluation, human-involved evaluation and user simulator based evaluation. Then, each class is covered with main features and the related evaluation metrics. The existence of benchmarks, suitable for the evaluation of dialogue techniques are also discussed in detail. Finally, some open issues are pointed out to bring the evaluation method into a new frontier.
Question-Aware Memory Network for Multi-hop Question Answering in Human-Robot Interaction
Apr 27, 2021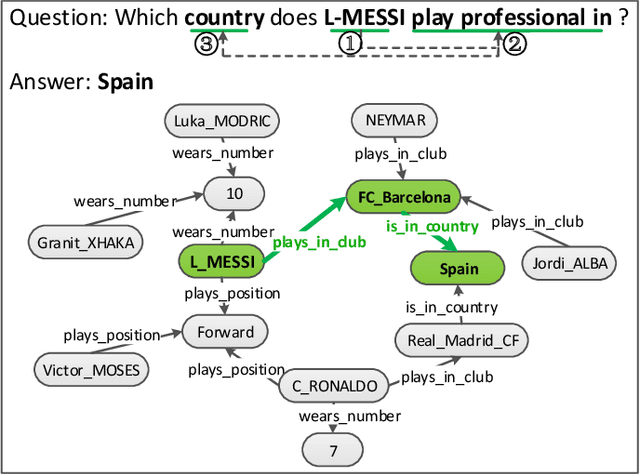

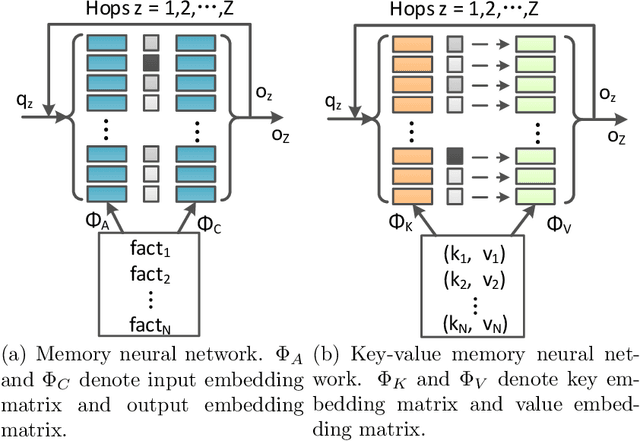
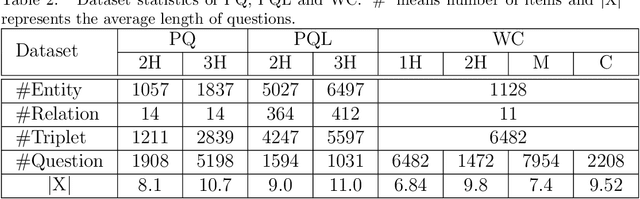
Knowledge graph question answering is an important technology in intelligent human-robot interaction, which aims at automatically giving answer to human natural language question with the given knowledge graph. For the multi-relation question with higher variety and complexity, the tokens of the question have different priority for the triples selection in the reasoning steps. Most existing models take the question as a whole and ignore the priority information in it. To solve this problem, we propose question-aware memory network for multi-hop question answering, named QA2MN, to update the attention on question timely in the reasoning process. In addition, we incorporate graph context information into knowledge graph embedding model to increase the ability to represent entities and relations. We use it to initialize the QA2MN model and fine-tune it in the training process. We evaluate QA2MN on PathQuestion and WorldCup2014, two representative datasets for complex multi-hop question answering. The result demonstrates that QA2MN achieves state-of-the-art Hits@1 accuracy on the two datasets, which validates the effectiveness of our model.