 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoost-RS: Boosted Embeddings for Recommender Systems and its Application to Enzyme-Substrate Interaction Prediction
Paper and Code
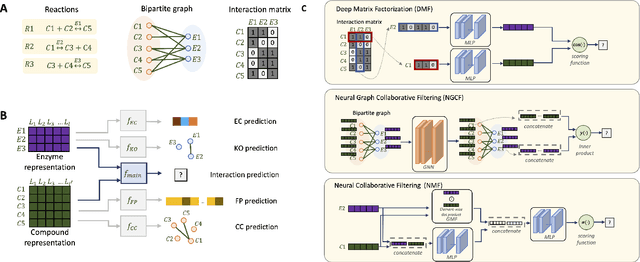
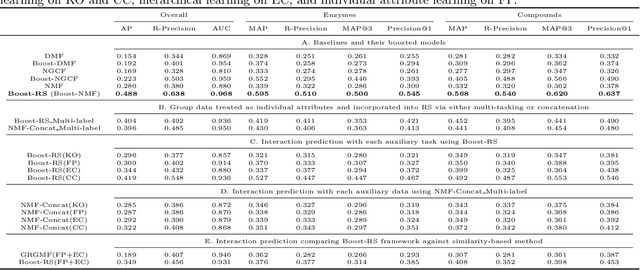
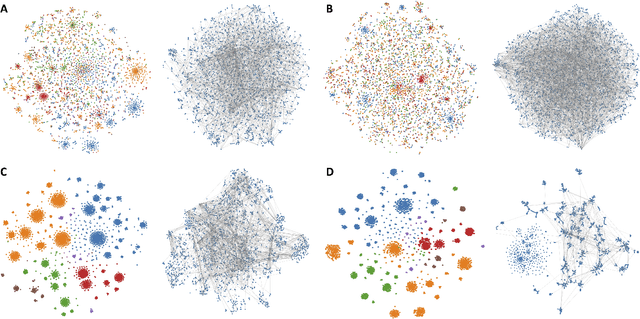
Despite experimental and curation efforts, the extent of enzyme promiscuity on substrates continues to be largely unexplored and under documented. Recommender systems (RS), which are currently unexplored for the enzyme-substrate interaction prediction problem, can be utilized to provide enzyme recommendations for substrates, and vice versa. The performance of Collaborative-Filtering (CF) recommender systems however hinges on the quality of embedding vectors of users and items (enzymes and substrates in our case). Importantly, enhancing CF embeddings with heterogeneous auxiliary data, specially relational data (e.g., hierarchical, pairwise, or groupings), remains a challenge. We propose an innovative general RS framework, termed Boost-RS, that enhances RS performance by "boosting" embedding vectors through auxiliary data. Specifically, Boost-RS is trained and dynamically tuned on multiple relevant auxiliary learning tasks Boost-RS utilizes contrastive learning tasks to exploit relational data. To show the efficacy of Boost-RS for the enzyme-substrate prediction interaction problem, we apply the Boost-RS framework to several baseline CF models. We show that each of our auxiliary tasks boosts learning of the embedding vectors, and that contrastive learning using Boost-RS outperforms attribute concatenation and multi-label learning. We also show that Boost-RS outperforms similarity-based models. Ablation studies and visualization of learned representations highlight the importance of using contrastive learning on some of the auxiliary data in boosting the embedding vectors.