 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGDiffZero: Text-to-image Diffusion Models Can Be Zero-shot Visual Grounders
Sep 03, 2023



Large-scale text-to-image diffusion models have shown impressive capabilities across various generative tasks, enabled by strong vision-language alignment obtained through pre-training. However, most vision-language discriminative tasks require extensive fine-tuning on carefully-labeled datasets to acquire such alignment, with great cost in time and computing resources. In this work, we explore directly applying a pre-trained generative diffusion model to the challenging discriminative task of visual grounding without any fine-tuning and additional training dataset. Specifically, we propose VGDiffZero, a simple yet effective zero-shot visual grounding framework based on text-to-image diffusion models. We also design a comprehensive region-scoring method considering both global and local contexts of each isolated proposal. Extensive experiments on RefCOCO, RefCOCO+, and RefCOCOg show that VGDiffZero achieves strong performance on zero-shot visual grounding.
STRAPPER: Preference-based Reinforcement Learning via Self-training Augmentation and Peer Regularization
Jul 19, 2023Preference-based reinforcement learning (PbRL) promises to learn a complex reward function with binary human preference. However, such human-in-the-loop formulation requires considerable human effort to assign preference labels to segment pairs, hindering its large-scale applications. Recent approache has tried to reuse unlabeled segments, which implicitly elucidates the distribution of segments and thereby alleviates the human effort. And consistency regularization is further considered to improve the performance of semi-supervised learning. However, we notice that, unlike general classification tasks, in PbRL there exits a unique phenomenon that we defined as similarity trap in this paper. Intuitively, human can have diametrically opposite preferredness for similar segment pairs, but such similarity may trap consistency regularization fail in PbRL. Due to the existence of similarity trap, such consistency regularization improperly enhances the consistency possiblity of the model's predictions between segment pairs, and thus reduces the confidence in reward learning, since the augmented distribution does not match with the original one in PbRL. To overcome such issue, we present a self-training method along with our proposed peer regularization, which penalizes the reward model memorizing uninformative labels and acquires confident predictions. Empirically, we demonstrate that our approach is capable of learning well a variety of locomotion and robotic manipulation behaviors using different semi-supervised alternatives and peer regularization.
Design from Policies: Conservative Test-Time Adaptation for Offline Policy Optimization
Jun 26, 2023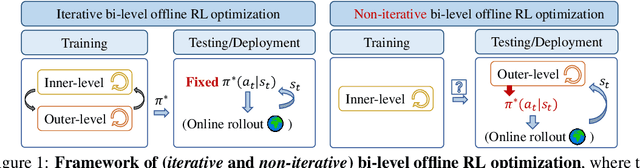

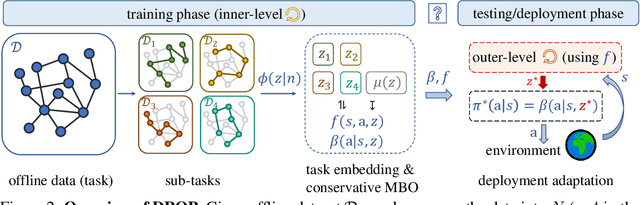
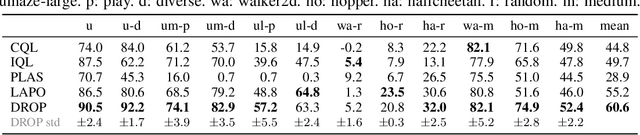
In this work, we decouple the iterative bi-level offline RL from the offline training phase, forming a non-iterative bi-level paradigm and avoiding the iterative error propagation over two levels. Specifically, this non-iterative paradigm allows us to conduct inner-level optimization in training (for OOD issues), while performing outer-level optimization in testing (for reward maximizing). Naturally, such a paradigm raises three core questions that are \textit{not} fully answered by prior non-iterative offline RL counterparts like reward-conditioned policy: Q1) What information should we transfer from the inner-level to the outer-level? Q2) What should we pay attention to when exploiting the transferred information in the outer-level optimization? Q3) What are the~benefits of concurrently conducting outer-level optimization during testing? Motivated by model-based optimization~{(MBO)}, we propose DROP (\textbf{D}esign f\textbf{RO}m \textbf{P}olicies), which fully answers the above questions. Specifically, in the inner-level, DROP decomposes offline data into multiple subsets and learns an {MBO} score model~(A1). To keep safe exploitation to the score model in the outer-level, we explicitly learn a behavior embedding and introduce a conservative regularization (A2). During testing, we show that DROP permits test-time adaptation, enabling an adaptive inference across states~(A3). Empirically, we find that DROP, compared to prior non-iterative offline RL counterparts, gains an average improvement probability of more than 80\%, and achieves comparable or better performance compared to prior iterative baselines.
CEIL: Generalized Contextual Imitation Learning
Jun 26, 2023



In this paper, we present \textbf{C}ont\textbf{E}xtual \textbf{I}mitation \textbf{L}earning~(CEIL), a general and broadly applicable algorithm for imitation learning (IL). Inspired by the formulation of hindsight information matching, we derive CEIL by explicitly learning a hindsight embedding function together with a contextual policy using the hindsight embeddings. To achieve the expert matching objective for IL, we advocate for optimizing a contextual variable such that it biases the contextual policy towards mimicking expert behaviors. Beyond the typical learning from demonstrations (LfD) setting, CEIL is a generalist that can be effectively applied to multiple settings including: 1)~learning from observations (LfO), 2)~offline IL, 3)~cross-domain IL (mismatched experts), and 4) one-shot IL settings. Empirically, we evaluate CEIL on the popular MuJoCo tasks (online) and the D4RL dataset (offline). Compared to prior state-of-the-art baselines, we show that CEIL is more sample-efficient in most online IL tasks and achieves better or competitive performances in offline tasks.
Beyond OOD State Actions: Supported Cross-Domain Offline Reinforcement Learning
Jun 22, 2023



Offline reinforcement learning (RL) aims to learn a policy using only pre-collected and fixed data. Although avoiding the time-consuming online interactions in RL, it poses challenges for out-of-distribution (OOD) state actions and often suffers from data inefficiency for training. Despite many efforts being devoted to addressing OOD state actions, the latter (data inefficiency) receives little attention in offline RL. To address this, this paper proposes the cross-domain offline RL, which assumes offline data incorporate additional source-domain data from varying transition dynamics (environments), and expects it to contribute to the offline data efficiency. To do so, we identify a new challenge of OOD transition dynamics, beyond the common OOD state actions issue, when utilizing cross-domain offline data. Then, we propose our method BOSA, which employs two support-constrained objectives to address the above OOD issues. Through extensive experiments in the cross-domain offline RL setting, we demonstrate BOSA can greatly improve offline data efficiency: using only 10\% of the target data, BOSA could achieve {74.4\%} of the SOTA offline RL performance that uses 100\% of the target data. Additionally, we also show BOSA can be effortlessly plugged into model-based offline RL and noising data augmentation techniques (used for generating source-domain data), which naturally avoids the potential dynamics mismatch between target-domain data and newly generated source-domain data.
Beyond Reward: Offline Preference-guided Policy Optimization
May 25, 2023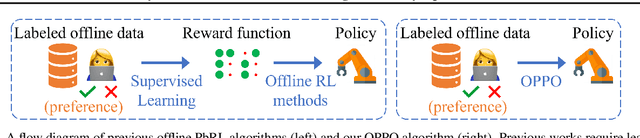
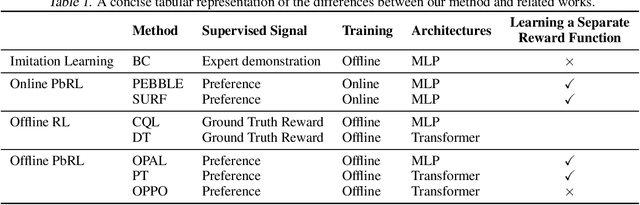
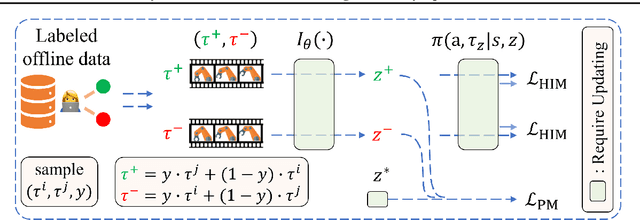
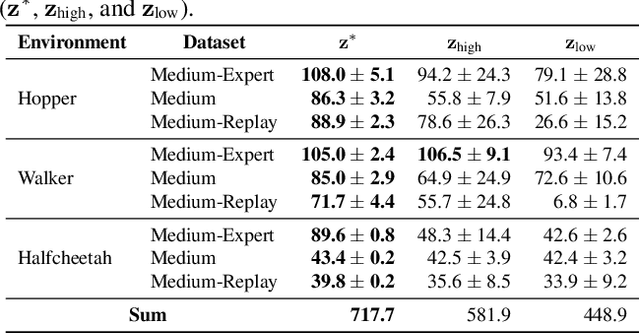
This study focuses on the topic of offline preference-based reinforcement learning (PbRL), a variant of conventional reinforcement learning that dispenses with the need for online interaction or specification of reward functions. Instead, the agent is provided with pre-existing offline trajectories and human preferences between pairs of trajectories to extract the dynamics and task information, respectively. Since the dynamics and task information are orthogonal, a naive approach would involve using preference-based reward learning followed by an off-the-shelf offline RL algorithm. However, this requires the separate learning of a scalar reward function, which is assumed to be an information bottleneck. To address this issue, we propose the offline preference-guided policy optimization (OPPO) paradigm, which models offline trajectories and preferences in a one-step process, eliminating the need for separately learning a reward function. OPPO achieves this by introducing an offline hindsight information matching objective for optimizing a contextual policy and a preference modeling objective for finding the optimal context. OPPO further integrates a well-performing decision policy by optimizing the two objectives iteratively. Our empirical results demonstrate that OPPO effectively models offline preferences and outperforms prior competing baselines, including offline RL algorithms performed over either true or pseudo reward function specifications. Our code is available at https://github.com/bkkgbkjb/OPPO .
Unsupervised Domain Adaptation with Dynamics-Aware Rewards in Reinforcement Learning
Oct 26, 2021
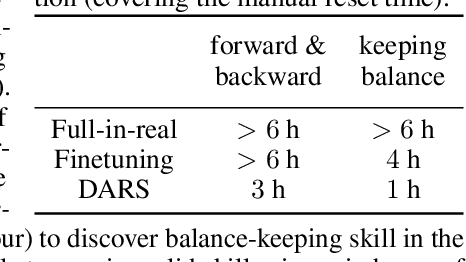
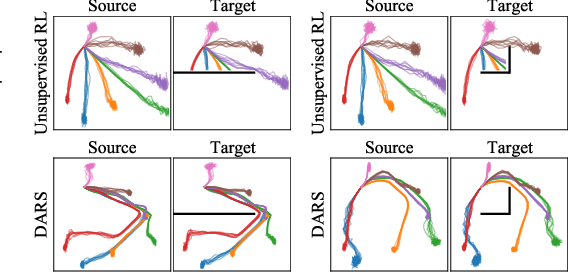
Unsupervised reinforcement learning aims to acquire skills without prior goal representations, where an agent automatically explores an open-ended environment to represent goals and learn the goal-conditioned policy. However, this procedure is often time-consuming, limiting the rollout in some potentially expensive target environments. The intuitive approach of training in another interaction-rich environment disrupts the reproducibility of trained skills in the target environment due to the dynamics shifts and thus inhibits direct transferring. Assuming free access to a source environment, we propose an unsupervised domain adaptation method to identify and acquire skills across dynamics. Particularly, we introduce a KL regularized objective to encourage emergence of skills, rewarding the agent for both discovering skills and aligning its behaviors respecting dynamics shifts. This suggests that both dynamics (source and target) shape the reward to facilitate the learning of adaptive skills. We also conduct empirical experiments to demonstrate that our method can effectively learn skills that can be smoothly deployed in target.
Off-Dynamics Inverse Reinforcement Learning from Hetero-Domain
Oct 21, 2021
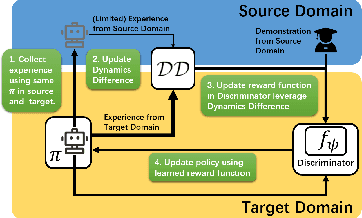
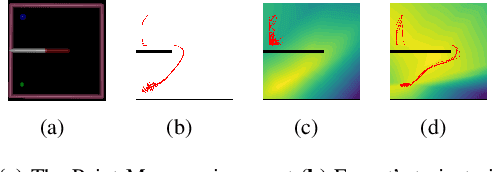
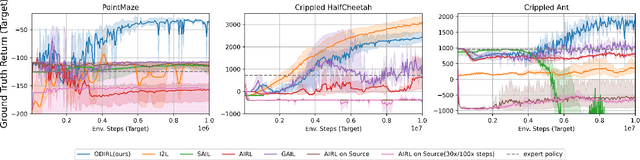
We propose an approach for inverse reinforcement learning from hetero-domain which learns a reward function in the simulator, drawing on the demonstrations from the real world. The intuition behind the method is that the reward function should not only be oriented to imitate the experts, but should encourage actions adjusted for the dynamics difference between the simulator and the real world. To achieve this, the widely used GAN-inspired IRL method is adopted, and its discriminator, recognizing policy-generating trajectories, is modified with the quantification of dynamics difference. The training process of the discriminator can yield the transferable reward function suitable for simulator dynamics, which can be guaranteed by derivation. Effectively, our method assigns higher rewards for demonstration trajectories which do not exploit discrepancies between the two domains. With extensive experiments on continuous control tasks, our method shows its effectiveness and demonstrates its scalability to high-dimensional tasks.
Attributes-Guided and Pure-Visual Attention Alignment for Few-Shot Recognition
Sep 10, 2020
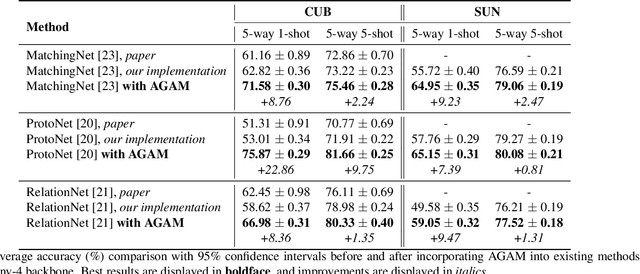
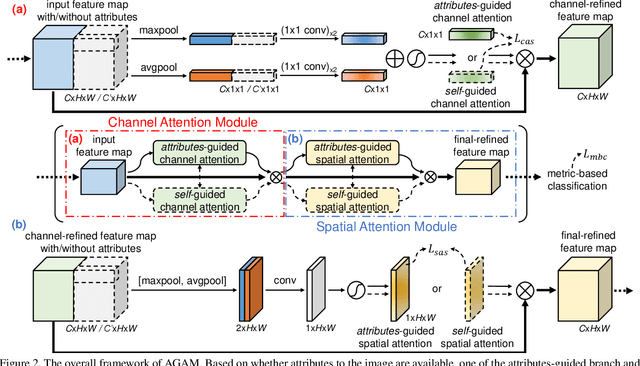
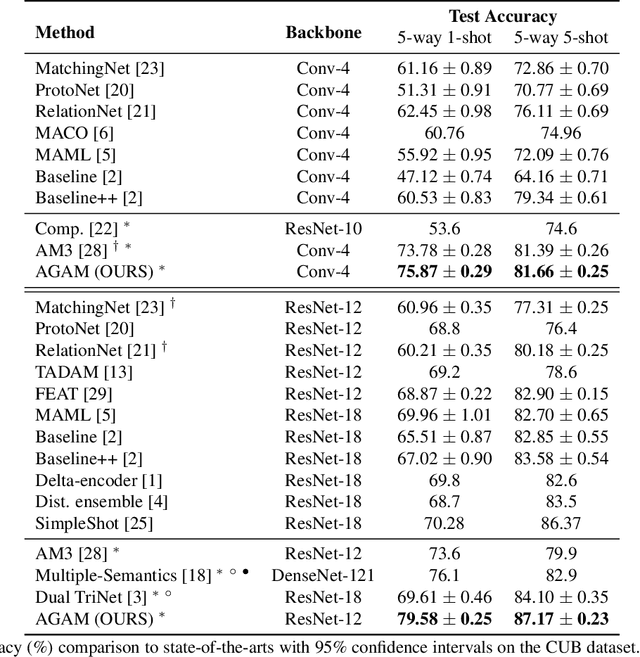
The purpose of few-shot recognition is to recognize novel categories with a limited number of labeled examples in each class. To encourage learning from a supplementary view, recent approaches have introduced auxiliary semantic modalities into effective metric-learning frameworks that aim to learn a feature similarity between training samples (support set) and test samples (query set). However, these approaches only augment the representations of samples with available semantics while ignoring the query set, which loses the potential for the improvement and may lead to a shift between the modalities combination and the pure-visual representation. In this paper, we devise an attributes-guided attention module (AGAM) to utilize human-annotated attributes and learn more discriminative features. This plug-and-play module enables visual contents and corresponding attributes to collectively focus on important channels and regions for support set. And the feature selection is also achieved for query set with only visual information while the attributes are not available. Therefore, representations from both sets are improved in a fine-grained manner. Moreover, an attention alignment mechanism is proposed to distill knowledge from the guidance of attributes to the pure-visual branch for samples without attributes. Extensive experiments and analysis show that our proposed module can significantly improve simple metric-based approaches to achieve state-of-the-art performance on different datasets and settings.