 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign from Policies: Conservative Test-Time Adaptation for Offline Policy Optimization
Paper and Code
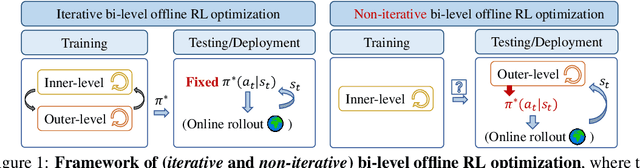

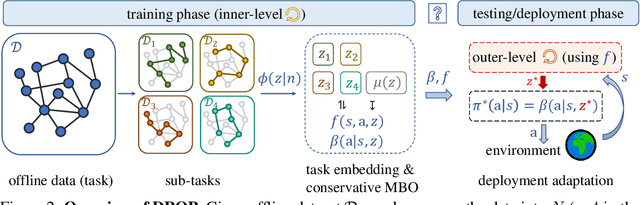
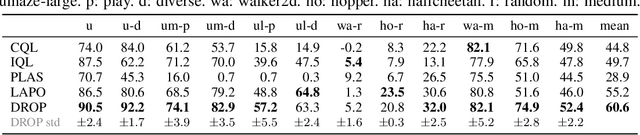
In this work, we decouple the iterative bi-level offline RL from the offline training phase, forming a non-iterative bi-level paradigm and avoiding the iterative error propagation over two levels. Specifically, this non-iterative paradigm allows us to conduct inner-level optimization in training (for OOD issues), while performing outer-level optimization in testing (for reward maximizing). Naturally, such a paradigm raises three core questions that are \textit{not} fully answered by prior non-iterative offline RL counterparts like reward-conditioned policy: Q1) What information should we transfer from the inner-level to the outer-level? Q2) What should we pay attention to when exploiting the transferred information in the outer-level optimization? Q3) What are the~benefits of concurrently conducting outer-level optimization during testing? Motivated by model-based optimization~{(MBO)}, we propose DROP (\textbf{D}esign f\textbf{RO}m \textbf{P}olicies), which fully answers the above questions. Specifically, in the inner-level, DROP decomposes offline data into multiple subsets and learns an {MBO} score model~(A1). To keep safe exploitation to the score model in the outer-level, we explicitly learn a behavior embedding and introduce a conservative regularization (A2). During testing, we show that DROP permits test-time adaptation, enabling an adaptive inference across states~(A3). Empirically, we find that DROP, compared to prior non-iterative offline RL counterparts, gains an average improvement probability of more than 80\%, and achieves comparable or better performance compared to prior iterative baselines.