 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Task Continual Offline Reinforcement Learning
Apr 19, 2024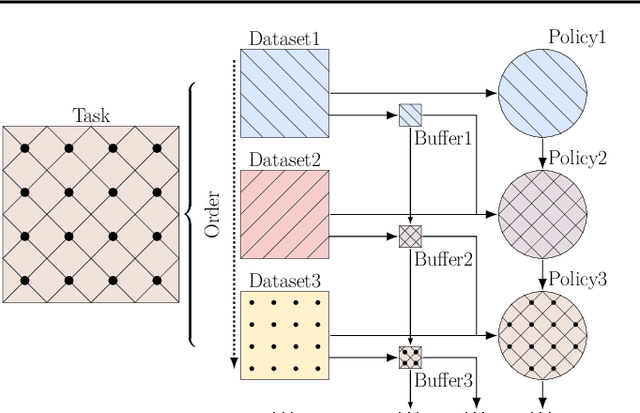



In this paper, we study the continual learning problem of single-task offline reinforcement learning. In the past, continual reinforcement learning usually only dealt with multitasking, that is, learning multiple related or unrelated tasks in a row, but once each learned task was learned, it was not relearned, but only used in subsequent processes. However, offline reinforcement learning tasks require the continuously learning of multiple different datasets for the same task. Existing algorithms will try their best to achieve the best results in each offline dataset they have learned and the skills of the network will overwrite the high-quality datasets that have been learned after learning the subsequent poor datasets. On the other hand, if too much emphasis is placed on stability, the network will learn the subsequent better dataset after learning the poor offline dataset, and the problem of insufficient plasticity and non-learning will occur. How to design a strategy that can always preserve the best performance for each state in the data that has been learned is a new challenge and the focus of this study. Therefore, this study proposes a new algorithm, called Ensemble Offline Reinforcement Learning Based on Experience Replay, which introduces multiple value networks to learn the same dataset and judge whether the strategy has been learned by the discrete degree of the value network, to improve the performance of the network in single-task offline reinforcement learning.
RSG: Fast Learning Adaptive Skills for Quadruped Robots by Skill Graph
Nov 10, 2023Developing robotic intelligent systems that can adapt quickly to unseen wild situations is one of the critical challenges in pursuing autonomous robotics. Although some impressive progress has been made in walking stability and skill learning in the field of legged robots, their ability to fast adaptation is still inferior to that of animals in nature. Animals are born with massive skills needed to survive, and can quickly acquire new ones, by composing fundamental skills with limited experience. Inspired by this, we propose a novel framework, named Robot Skill Graph (RSG) for organizing massive fundamental skills of robots and dexterously reusing them for fast adaptation. Bearing a structure similar to the Knowledge Graph (KG), RSG is composed of massive dynamic behavioral skills instead of static knowledge in KG and enables discovering implicit relations that exist in be-tween of learning context and acquired skills of robots, serving as a starting point for understanding subtle patterns existing in robots' skill learning. Extensive experimental results demonstrate that RSG can provide rational skill inference upon new tasks and environments and enable quadruped robots to adapt to new scenarios and learn new skills rapidly.
Beyond OOD State Actions: Supported Cross-Domain Offline Reinforcement Learning
Jun 22, 2023



Offline reinforcement learning (RL) aims to learn a policy using only pre-collected and fixed data. Although avoiding the time-consuming online interactions in RL, it poses challenges for out-of-distribution (OOD) state actions and often suffers from data inefficiency for training. Despite many efforts being devoted to addressing OOD state actions, the latter (data inefficiency) receives little attention in offline RL. To address this, this paper proposes the cross-domain offline RL, which assumes offline data incorporate additional source-domain data from varying transition dynamics (environments), and expects it to contribute to the offline data efficiency. To do so, we identify a new challenge of OOD transition dynamics, beyond the common OOD state actions issue, when utilizing cross-domain offline data. Then, we propose our method BOSA, which employs two support-constrained objectives to address the above OOD issues. Through extensive experiments in the cross-domain offline RL setting, we demonstrate BOSA can greatly improve offline data efficiency: using only 10\% of the target data, BOSA could achieve {74.4\%} of the SOTA offline RL performance that uses 100\% of the target data. Additionally, we also show BOSA can be effortlessly plugged into model-based offline RL and noising data augmentation techniques (used for generating source-domain data), which naturally avoids the potential dynamics mismatch between target-domain data and newly generated source-domain data.
Offline Experience Replay for Continual Offline Reinforcement Learning
May 23, 2023



The capability of continuously learning new skills via a sequence of pre-collected offline datasets is desired for an agent. However, consecutively learning a sequence of offline tasks likely leads to the catastrophic forgetting issue under resource-limited scenarios. In this paper, we formulate a new setting, continual offline reinforcement learning (CORL), where an agent learns a sequence of offline reinforcement learning tasks and pursues good performance on all learned tasks with a small replay buffer without exploring any of the environments of all the sequential tasks. For consistently learning on all sequential tasks, an agent requires acquiring new knowledge and meanwhile preserving old knowledge in an offline manner. To this end, we introduced continual learning algorithms and experimentally found experience replay (ER) to be the most suitable algorithm for the CORL problem. However, we observe that introducing ER into CORL encounters a new distribution shift problem: the mismatch between the experiences in the replay buffer and trajectories from the learned policy. To address such an issue, we propose a new model-based experience selection (MBES) scheme to build the replay buffer, where a transition model is learned to approximate the state distribution. This model is used to bridge the distribution bias between the replay buffer and the learned model by filtering the data from offline data that most closely resembles the learned model for storage. Moreover, in order to enhance the ability on learning new tasks, we retrofit the experience replay method with a new dual behavior cloning (DBC) architecture to avoid the disturbance of behavior-cloning loss on the Q-learning process. In general, we call our algorithm offline experience replay (OER). Extensive experiments demonstrate that our OER method outperforms SOTA baselines in widely-used Mujoco environments.