 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Task Continual Offline Reinforcement Learning
Paper and Code
Apr 19, 2024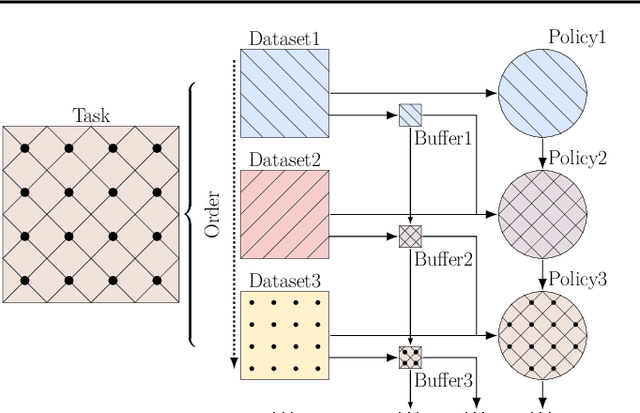



In this paper, we study the continual learning problem of single-task offline reinforcement learning. In the past, continual reinforcement learning usually only dealt with multitasking, that is, learning multiple related or unrelated tasks in a row, but once each learned task was learned, it was not relearned, but only used in subsequent processes. However, offline reinforcement learning tasks require the continuously learning of multiple different datasets for the same task. Existing algorithms will try their best to achieve the best results in each offline dataset they have learned and the skills of the network will overwrite the high-quality datasets that have been learned after learning the subsequent poor datasets. On the other hand, if too much emphasis is placed on stability, the network will learn the subsequent better dataset after learning the poor offline dataset, and the problem of insufficient plasticity and non-learning will occur. How to design a strategy that can always preserve the best performance for each state in the data that has been learned is a new challenge and the focus of this study. Therefore, this study proposes a new algorithm, called Ensemble Offline Reinforcement Learning Based on Experience Replay, which introduces multiple value networks to learn the same dataset and judge whether the strategy has been learned by the discrete degree of the value network, to improve the performance of the network in single-task offline reinforcement learning.