 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHopPG: Self-Iterative Program Generation for Multi-Hop Question Answering over Heterogeneous Knowledge
Sep 10, 2023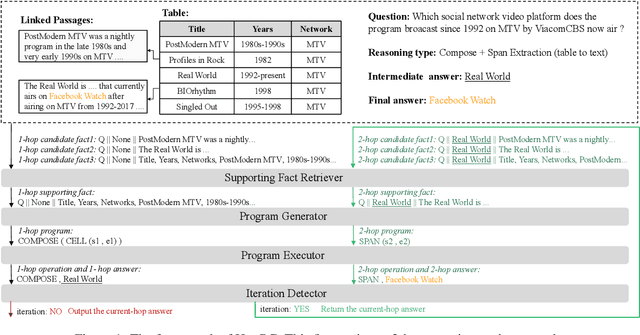
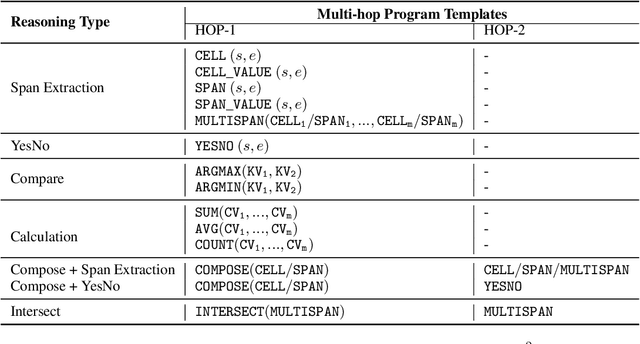
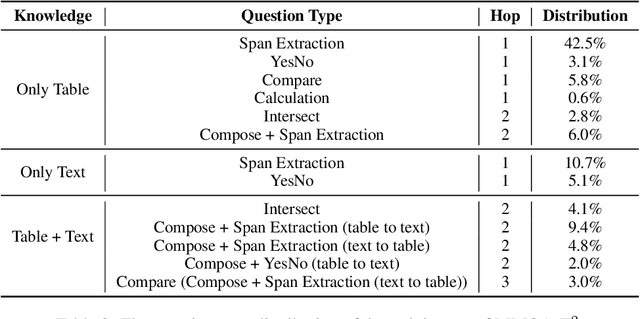

The semantic parsing-based method is an important research branch for knowledge-based question answering. It usually generates executable programs lean upon the question and then conduct them to reason answers over a knowledge base. Benefit from this inherent mechanism, it has advantages in the performance and the interpretability. However, traditional semantic parsing methods usually generate a complete program before executing it, which struggles with multi-hop question answering over heterogeneous knowledge. On one hand, generating a complete multi-hop program relies on multiple heterogeneous supporting facts, and it is difficult for generators to understand these facts simultaneously. On the other hand, this way ignores the semantic information of the intermediate answers at each hop, which is beneficial for subsequent generation. To alleviate these challenges, we propose a self-iterative framework for multi-hop program generation (HopPG) over heterogeneous knowledge, which leverages the previous execution results to retrieve supporting facts and generate subsequent programs hop by hop. We evaluate our model on MMQA-T^2, and the experimental results show that HopPG outperforms existing semantic-parsing-based baselines, especially on the multi-hop questions.
MuGER$^2$: Multi-Granularity Evidence Retrieval and Reasoning for Hybrid Question Answering
Oct 19, 2022
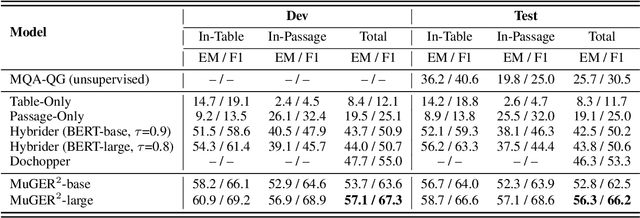
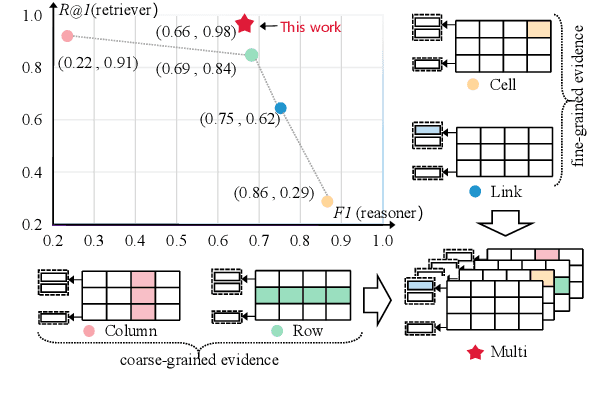
Hybrid question answering (HQA) aims to answer questions over heterogeneous data, including tables and passages linked to table cells. The heterogeneous data can provide different granularity evidence to HQA models, e.t., column, row, cell, and link. Conventional HQA models usually retrieve coarse- or fine-grained evidence to reason the answer. Through comparison, we find that coarse-grained evidence is easier to retrieve but contributes less to the reasoner, while fine-grained evidence is the opposite. To preserve the advantage and eliminate the disadvantage of different granularity evidence, we propose MuGER$^2$, a Multi-Granularity Evidence Retrieval and Reasoning approach. In evidence retrieval, a unified retriever is designed to learn the multi-granularity evidence from the heterogeneous data. In answer reasoning, an evidence selector is proposed to navigate the fine-grained evidence for the answer reader based on the learned multi-granularity evidence. Experiment results on the HybridQA dataset show that MuGER$^2$ significantly boosts the HQA performance. Further ablation analysis verifies the effectiveness of both the retrieval and reasoning designs.
UniRPG: Unified Discrete Reasoning over Table and Text as Program Generation
Oct 15, 2022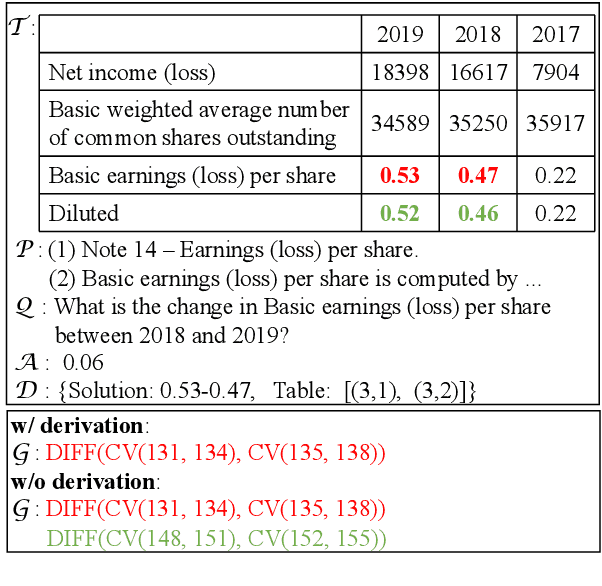
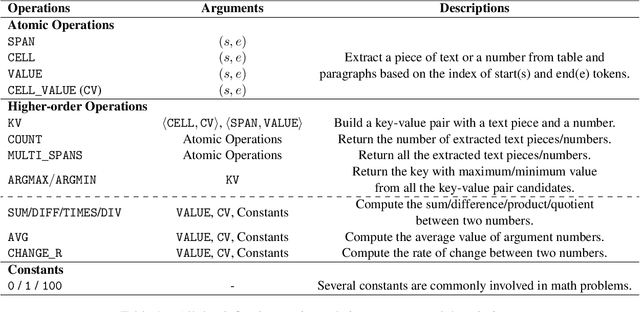
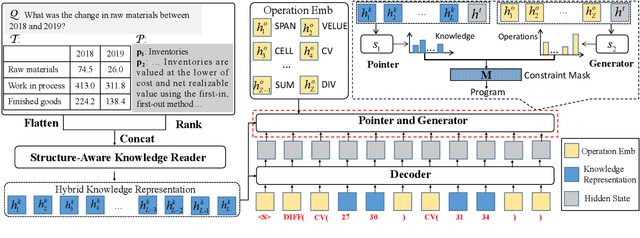
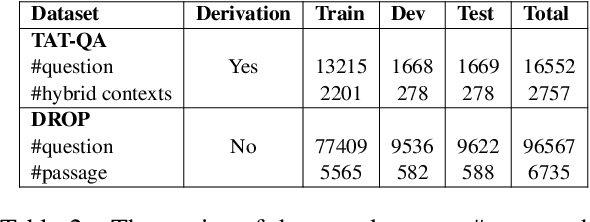
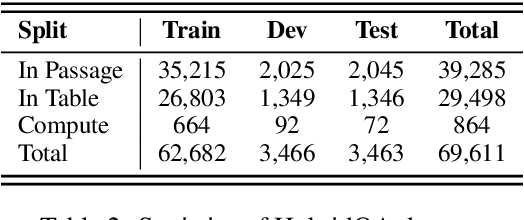
Question answering requiring discrete reasoning, e.g., arithmetic computing, comparison, and counting, over knowledge is a challenging task. In this paper, we propose UniRPG, a semantic-parsing-based approach advanced in interpretability and scalability, to perform unified discrete reasoning over heterogeneous knowledge resources, i.e., table and text, as program generation. Concretely, UniRPG consists of a neural programmer and a symbolic program executor, where a program is the composition of a set of pre-defined general atomic and higher-order operations and arguments extracted from table and text. First, the programmer parses a question into a program by generating operations and copying arguments, and then the executor derives answers from table and text based on the program. To alleviate the costly program annotation issue, we design a distant supervision approach for programmer learning, where pseudo programs are automatically constructed without annotated derivations. Extensive experiments on the TAT-QA dataset show that UniRPG achieves tremendous improvements and enhances interpretability and scalability compared with state-of-the-art methods, even without derivation annotation. Moreover, it achieves promising performance on the textual dataset DROP without derivations.
LUNA: Learning Slot-Turn Alignment for Dialogue State Tracking
May 05, 2022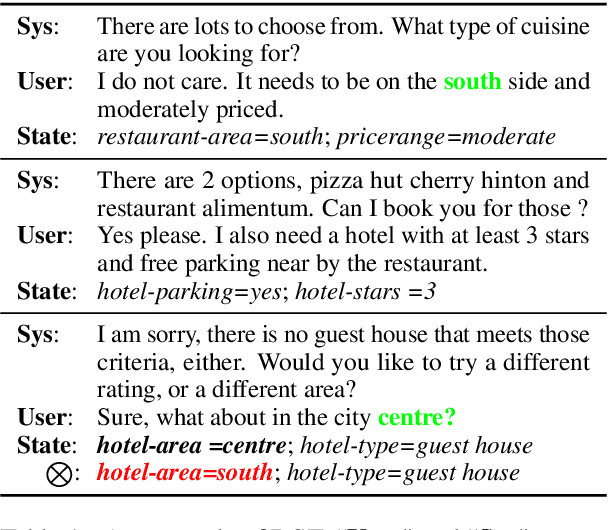
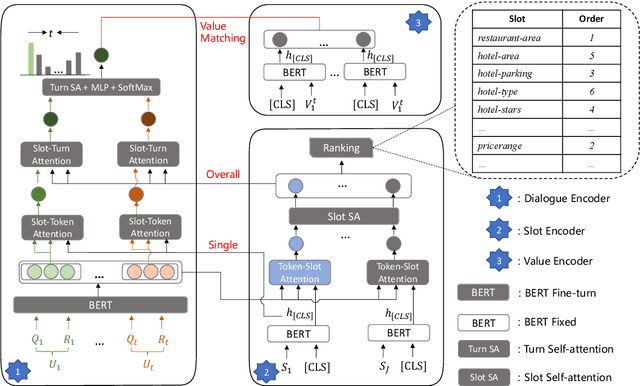
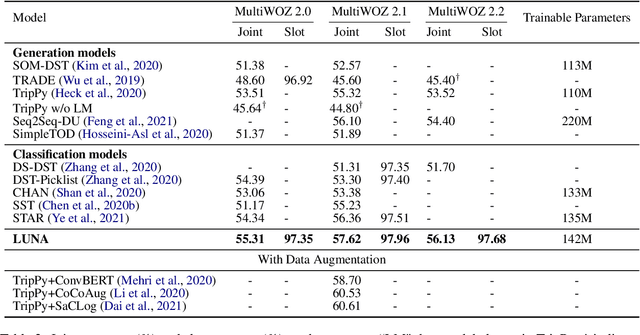
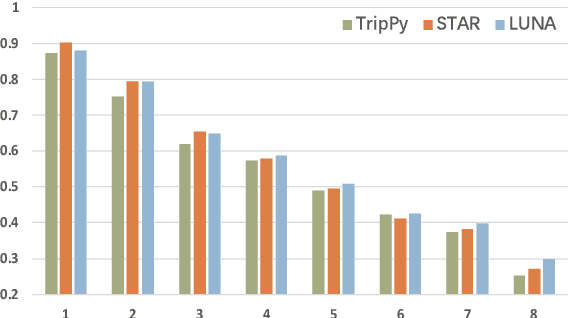
Dialogue state tracking (DST) aims to predict the current dialogue state given the dialogue history. Existing methods generally exploit the utterances of all dialogue turns to assign value for each slot. This could lead to suboptimal results due to the information introduced from irrelevant utterances in the dialogue history, which may be useless and can even cause confusion. To address this problem, we propose LUNA, a sLot-tUrN Alignment enhanced approach. It first explicitly aligns each slot with its most relevant utterance, then further predicts the corresponding value based on this aligned utterance instead of all dialogue utterances. Furthermore, we design a slot ranking auxiliary task to learn the temporal correlation among slots which could facilitate the alignment. Comprehensive experiments are conducted on multi-domain task-oriented dialogue datasets, i.e., MultiWOZ 2.0, MultiWOZ 2.1, and MultiWOZ 2.2. The results show that LUNA achieves new state-of-the-art results on these datasets.
OPERA:Operation-Pivoted Discrete Reasoning over Text
May 04, 2022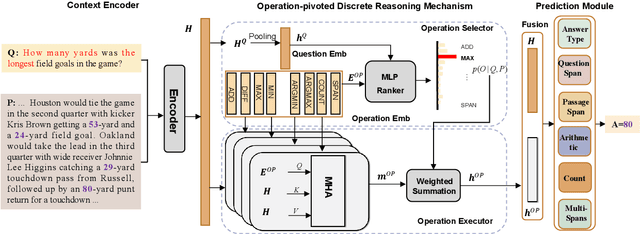

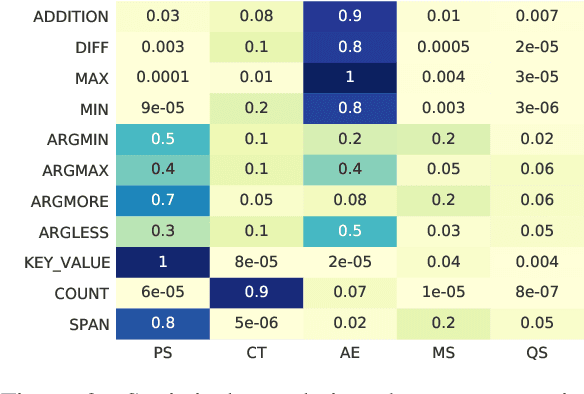

Machine reading comprehension (MRC) that requires discrete reasoning involving symbolic operations, e.g., addition, sorting, and counting, is a challenging task. According to this nature, semantic parsing-based methods predict interpretable but complex logical forms. However, logical form generation is nontrivial and even a little perturbation in a logical form will lead to wrong answers. To alleviate this issue, multi-predictor -based methods are proposed to directly predict different types of answers and achieve improvements. However, they ignore the utilization of symbolic operations and encounter a lack of reasoning ability and interpretability. To inherit the advantages of these two types of methods, we propose OPERA, an operation-pivoted discrete reasoning framework, where lightweight symbolic operations (compared with logical forms) as neural modules are utilized to facilitate the reasoning ability and interpretability. Specifically, operations are first selected and then softly executed to simulate the answer reasoning procedure. Extensive experiments on both DROP and RACENum datasets show the reasoning ability of OPERA. Moreover, further analysis verifies its interpretability.
Modeling Future Cost for Neural Machine Translation
Feb 28, 2020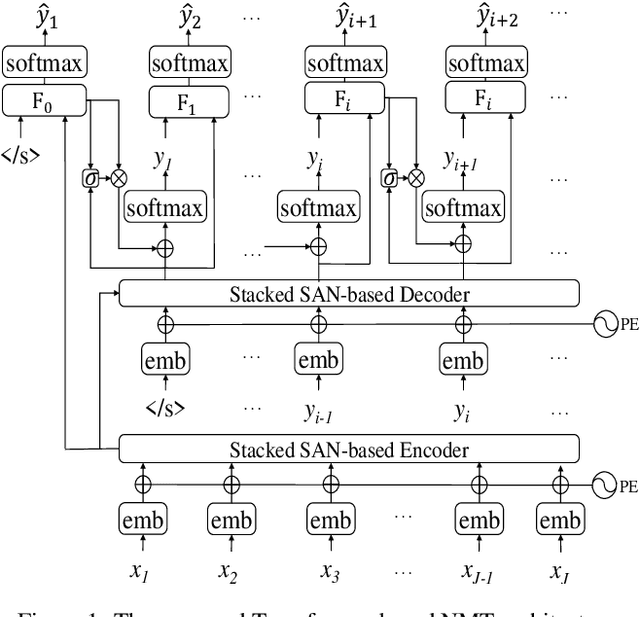
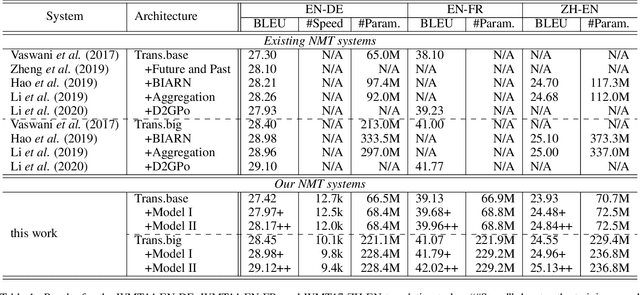
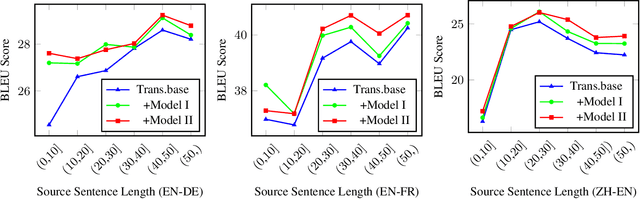
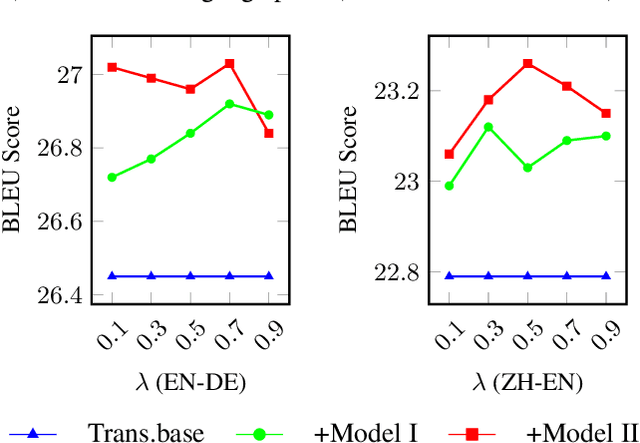
Existing neural machine translation (NMT) systems utilize sequence-to-sequence neural networks to generate target translation word by word, and then make the generated word at each time-step and the counterpart in the references as consistent as possible. However, the trained translation model tends to focus on ensuring the accuracy of the generated target word at the current time-step and does not consider its future cost which means the expected cost of generating the subsequent target translation (i.e., the next target word). To respond to this issue, we propose a simple and effective method to model the future cost of each target word for NMT systems. In detail, a time-dependent future cost is estimated based on the current generated target word and its contextual information to boost the training of the NMT model. Furthermore, the learned future context representation at the current time-step is used to help the generation of the next target word in the decoding. Experimental results on three widely-used translation datasets, including the WMT14 German-to-English, WMT14 English-to-French, and WMT17 Chinese-to-English, show that the proposed approach achieves significant improvements over strong Transformer-based NMT baseline.
Multimodal Matching Transformer for Live Commenting
Feb 07, 2020
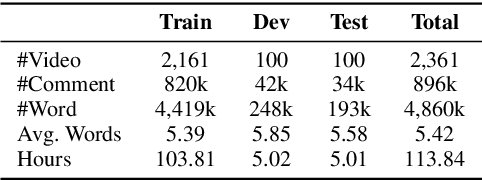
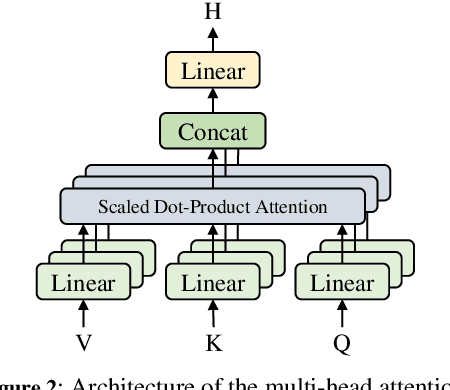
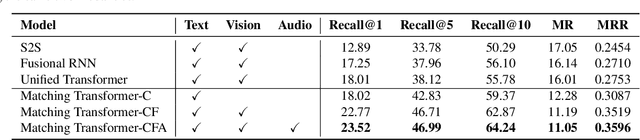
Automatic live commenting aims to provide real-time comments on videos for viewers. It encourages users engagement on online video sites, and is also a good benchmark for video-to-text generation. Recent work on this task adopts encoder-decoder models to generate comments. However, these methods do not model the interaction between videos and comments explicitly, so they tend to generate popular comments that are often irrelevant to the videos. In this work, we aim to improve the relevance between live comments and videos by modeling the cross-modal interactions among different modalities. To this end, we propose a multimodal matching transformer to capture the relationships among comments, vision, and audio. The proposed model is based on the transformer framework and can iteratively learn the attention-aware representations for each modality. We evaluate the model on a publicly available live commenting dataset. Experiments show that the multimodal matching transformer model outperforms the state-of-the-art methods.