 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Structure Learning For Graph Neural Networks
Paper and Code
Nov 12, 2024
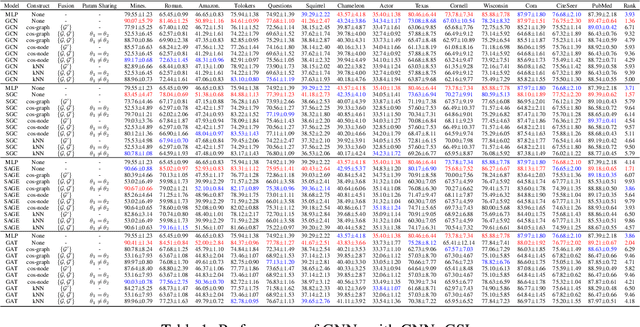
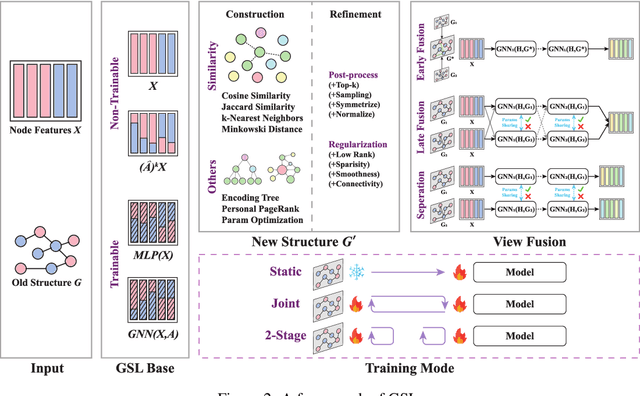

To improve the performance of Graph Neural Networks (GNNs), Graph Structure Learning (GSL) has been extensively applied to reconstruct or refine original graph structures, effectively addressing issues like heterophily, over-squashing, and noisy structures. While GSL is generally thought to improve GNN performance, it often leads to longer training times and more hyperparameter tuning. Besides, the distinctions among current GSL methods remain ambiguous from the perspective of GNN training, and there is a lack of theoretical analysis to quantify their effectiveness. Recent studies further suggest that, under fair comparisons with the same hyperparameter tuning, GSL does not consistently outperform baseline GNNs. This motivates us to ask a critical question: is GSL really useful for GNNs? To address this question, this paper makes two key contributions. First, we propose a new GSL framework, which includes three steps: GSL base (the representation used for GSL) construction, new structure construction, and view fusion, to better understand the effectiveness of GSL in GNNs. Second, after graph convolution, we analyze the differences in mutual information (MI) between node representations derived from the original topology and those from the newly constructed topology. Surprisingly, our empirical observations and theoretical analysis show that no matter which type of graph structure construction methods are used, after feeding the same GSL bases to the newly constructed graph, there is no MI gain compared to the original GSL bases. To fairly reassess the effectiveness of GSL, we conduct ablation experiments and find that it is the pretrained GSL bases that enhance GNN performance, and in most cases, GSL cannot improve GNN performance. This finding encourages us to rethink the essential components in GNNs, such as self-training and structural encoding, in GNN design rather than GSL.