Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSTC-NELSLIP System Description for DIHARD-III Challenge
Paper and Code
Mar 19, 2021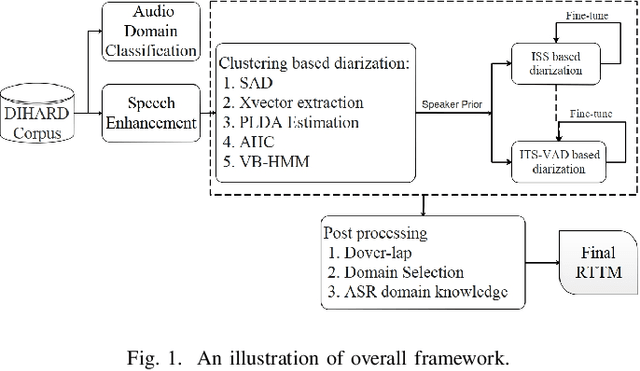
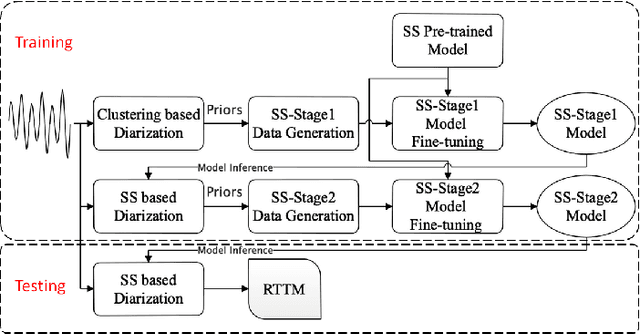
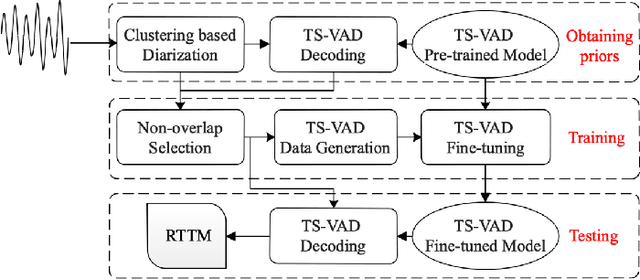
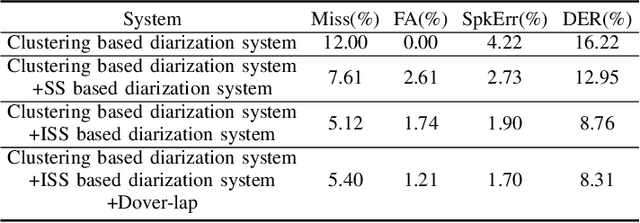
This system description describes our submission system to the Third DIHARD Speech Diarization Challenge. Besides the traditional clustering based system, the innovation of our system lies in the combination of various front-end techniques to solve the diarization problem, including speech separation and target-speaker based voice activity detection (TS-VAD), combined with iterative data purification. We also adopted audio domain classification to design domain-dependent processing. Finally, we performed post processing to do system fusion and selection. Our best system achieved DERs of 11.30% in track 1 and 16.78% in track 2 on evaluation set, respectively.
View paper on