 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Bioacoustic Event Detection with Frame-Level Embedding Learning System
Jul 14, 2024This technical report presents our frame-level embedding learning system for the DCASE2024 challenge for few-shot bioacoustic event detection (Task 5).In this work, we used log-mel and PCEN for feature extraction of the input audio, Netmamba Encoder as the information interaction network, and adopted data augmentation strategies to improve the generalizability of the trained model as well as multiple post-processing methods. Our final system achieved an F-measure score of 56.4%, securing the 2nd rank in the few-shot bioacoustic event detection category of the Detection and Classification of Acoustic Scenes and Events Challenge 2024.
Multitask frame-level learning for few-shot sound event detection
Mar 17, 2024This paper focuses on few-shot Sound Event Detection (SED), which aims to automatically recognize and classify sound events with limited samples. However, prevailing methods methods in few-shot SED predominantly rely on segment-level predictions, which often providing detailed, fine-grained predictions, particularly for events of brief duration. Although frame-level prediction strategies have been proposed to overcome these limitations, these strategies commonly face difficulties with prediction truncation caused by background noise. To alleviate this issue, we introduces an innovative multitask frame-level SED framework. In addition, we introduce TimeFilterAug, a linear timing mask for data augmentation, to increase the model's robustness and adaptability to diverse acoustic environments. The proposed method achieves a F-score of 63.8%, securing the 1st rank in the few-shot bioacoustic event detection category of the Detection and Classification of Acoustic Scenes and Events Challenge 2023.
3D Dense Separated Convolution Module for Volumetric Image Analysis
May 14, 2019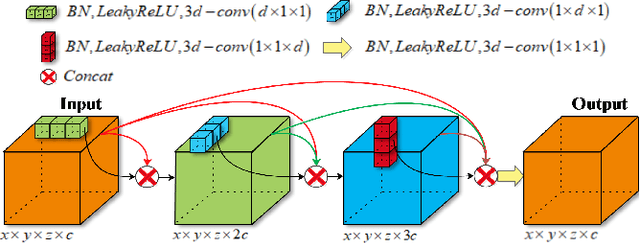
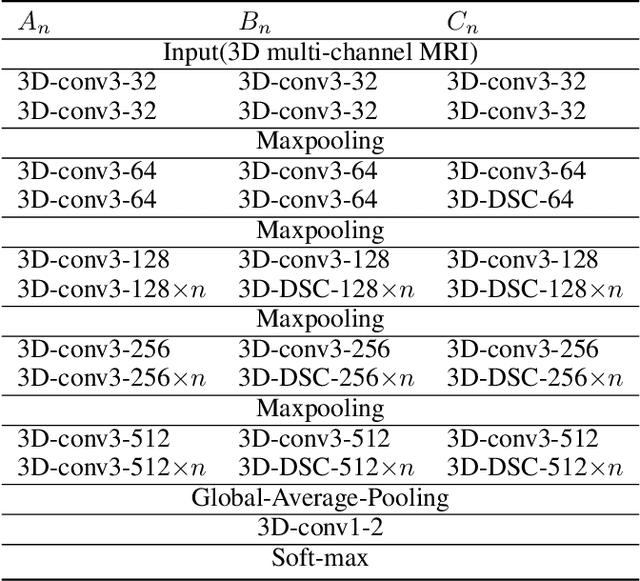
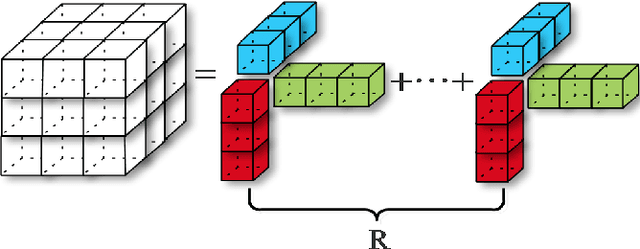
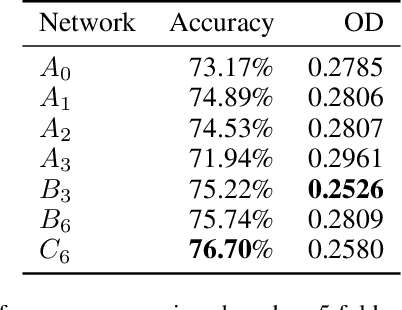
With the thriving of deep learning, 3D Convolutional Neural Networks have become a popular choice in volumetric image analysis due to their impressive 3D contexts mining ability. However, the 3D convolutional kernels will introduce a significant increase in the amount of trainable parameters. Considering the training data is often limited in biomedical tasks, a tradeoff has to be made between model size and its representational power. To address this concern, in this paper, we propose a novel 3D Dense Separated Convolution (3D-DSC) module to replace the original 3D convolutional kernels. The 3D-DSC module is constructed by a series of densely connected 1D filters. The decomposition of 3D kernel into 1D filters reduces the risk of over-fitting by removing the redundancy of 3D kernels in a topologically constrained manner, while providing the infrastructure for deepening the network. By further introducing nonlinear layers and dense connections between 1D filters, the network's representational power can be significantly improved while maintaining a compact architecture. We demonstrate the superiority of 3D-DSC on volumetric image classification and segmentation, which are two challenging tasks often encountered in biomedical image computing.