 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe USTC-NERCSLIP Systems for the CHiME-9 MCoRec Challenge
Mar 02, 2026This report details our submission to the CHiME-9 MCoRec Challenge on recognizing and clustering multiple concurrent natural conversations within indoor social settings. Unlike conventional meetings centered on a single shared topic, this scenario contains multiple parallel dialogues--up to eight speakers across up to four simultaneous conversations--with a speech overlap rate exceeding 90%. To tackle this, we propose a multimodal cascaded system that leverages per-speaker visual streams extracted from synchronized 360 degree video together with single-channel audio. Our system improves three components of the pipeline by leveraging enhanced audio-visual pretrained models: Active Speaker Detection (ASD), Audio-Visual Target Speech Extraction (AVTSE), and Audio-Visual Speech Recognition (AVSR). The AVSR module further incorporates Whisper and LLM techniques to boost transcription accuracy. Our best single cascaded system achieves a Speaker Word Error Rate (WER) of 32.44% on the development set. By further applying ROVER to fuse outputs from diverse front-end and back-end variants, we reduce Speaker WER to 31.40%. Notably, our LLM-based zero-shot conversational clustering achieves a speaker clustering F1 score of 1.0, yielding a final Joint ASR-Clustering Error Rate (JACER) of 15.70%.
MirrorMark: A Distortion-Free Multi-Bit Watermark for Large Language Models
Jan 29, 2026As large language models (LLMs) become integral to applications such as question answering and content creation, reliable content attribution has become increasingly important. Watermarking is a promising approach, but existing methods either provide only binary signals or distort the sampling distribution, degrading text quality; distortion-free approaches, in turn, often suffer from weak detectability or robustness. We propose MirrorMark, a multi-bit and distortion-free watermark for LLMs. By mirroring sampling randomness in a measure-preserving manner, MirrorMark embeds multi-bit messages without altering the token probability distribution, preserving text quality by design. To improve robustness, we introduce a context-based scheduler that balances token assignments across message positions while remaining resilient to insertions and deletions. We further provide a theoretical analysis of the equal error rate to interpret empirical performance. Experiments show that MirrorMark matches the text quality of non-watermarked generation while achieving substantially stronger detectability: with 54 bits embedded in 300 tokens, it improves bit accuracy by 8-12% and correctly identifies up to 11% more watermarked texts at 1% false positive rate.
StealthInk: A Multi-bit and Stealthy Watermark for Large Language Models
Jun 05, 2025
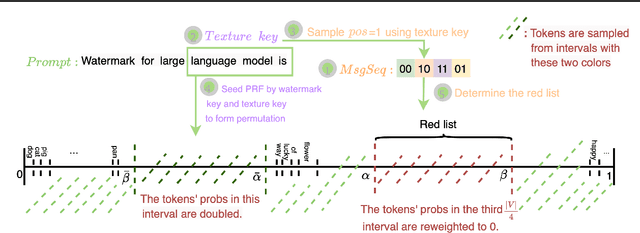
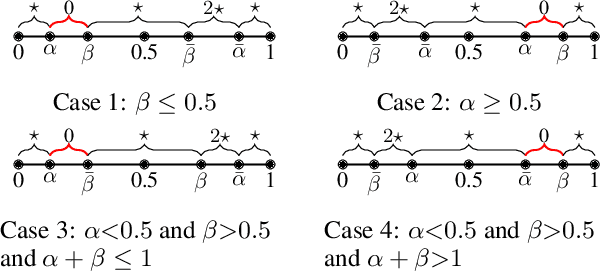
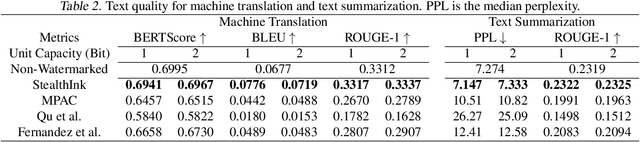
Watermarking for large language models (LLMs) offers a promising approach to identifying AI-generated text. Existing approaches, however, either compromise the distribution of original generated text by LLMs or are limited to embedding zero-bit information that only allows for watermark detection but ignores identification. We present StealthInk, a stealthy multi-bit watermarking scheme that preserves the original text distribution while enabling the embedding of provenance data, such as userID, TimeStamp, and modelID, within LLM-generated text. This enhances fast traceability without requiring access to the language model's API or prompts. We derive a lower bound on the number of tokens necessary for watermark detection at a fixed equal error rate, which provides insights on how to enhance the capacity. Comprehensive empirical evaluations across diverse tasks highlight the stealthiness, detectability, and resilience of StealthInk, establishing it as an effective solution for LLM watermarking applications.
An Experimental Study on Joint Modeling for Sound Event Localization and Detection with Source Distance Estimation
Jan 18, 2025



In traditional sound event localization and detection (SELD) tasks, the focus is typically on sound event detection (SED) and direction-of-arrival (DOA) estimation, but they fall short of providing full spatial information about the sound source. The 3D SELD task addresses this limitation by integrating source distance estimation (SDE), allowing for complete spatial localization. We propose three approaches to tackle this challenge: a novel method with independent training and joint prediction, which firstly treats DOA and distance estimation as separate tasks and then combines them to solve 3D SELD; a dual-branch representation with source Cartesian coordinate used for simultaneous DOA and distance estimation; and a three-branch structure that jointly models SED, DOA, and SDE within a unified framework. Our proposed method ranked first in the DCASE 2024 Challenge Task 3, demonstrating the effectiveness of joint modeling for addressing the 3D SELD task. The relevant code for this paper will be open-sourced in the future.
Exploring Audio-Visual Information Fusion for Sound Event Localization and Detection In Low-Resource Realistic Scenarios
Jun 21, 2024This study presents an audio-visual information fusion approach to sound event localization and detection (SELD) in low-resource scenarios. We aim at utilizing audio and video modality information through cross-modal learning and multi-modal fusion. First, we propose a cross-modal teacher-student learning (TSL) framework to transfer information from an audio-only teacher model, trained on a rich collection of audio data with multiple data augmentation techniques, to an audio-visual student model trained with only a limited set of multi-modal data. Next, we propose a two-stage audio-visual fusion strategy, consisting of an early feature fusion and a late video-guided decision fusion to exploit synergies between audio and video modalities. Finally, we introduce an innovative video pixel swapping (VPS) technique to extend an audio channel swapping (ACS) method to an audio-visual joint augmentation. Evaluation results on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2023 Challenge data set demonstrate significant improvements in SELD performances. Furthermore, our submission to the SELD task of the DCASE 2023 Challenge ranks first place by effectively integrating the proposed techniques into a model ensemble.
Multi-Bit Distortion-Free Watermarking for Large Language Models
Feb 26, 2024



Methods for watermarking large language models have been proposed that distinguish AI-generated text from human-generated text by slightly altering the model output distribution, but they also distort the quality of the text, exposing the watermark to adversarial detection. More recently, distortion-free watermarking methods were proposed that require a secret key to detect the watermark. The prior methods generally embed zero-bit watermarks that do not provide additional information beyond tagging a text as being AI-generated. We extend an existing zero-bit distortion-free watermarking method by embedding multiple bits of meta-information as part of the watermark. We also develop a computationally efficient decoder that extracts the embedded information from the watermark with low bit error rate.
Hierarchical Audio-Visual Information Fusion with Multi-label Joint Decoding for MER 2023
Sep 11, 2023



In this paper, we propose a novel framework for recognizing both discrete and dimensional emotions. In our framework, deep features extracted from foundation models are used as robust acoustic and visual representations of raw video. Three different structures based on attention-guided feature gathering (AFG) are designed for deep feature fusion. Then, we introduce a joint decoding structure for emotion classification and valence regression in the decoding stage. A multi-task loss based on uncertainty is also designed to optimize the whole process. Finally, by combining three different structures on the posterior probability level, we obtain the final predictions of discrete and dimensional emotions. When tested on the dataset of multimodal emotion recognition challenge (MER 2023), the proposed framework yields consistent improvements in both emotion classification and valence regression. Our final system achieves state-of-the-art performance and ranks third on the leaderboard on MER-MULTI sub-challenge.
* 5 pages, 4 figures
Deep Learning Based Audio-Visual Multi-Speaker DOA Estimation Using Permutation-Free Loss Function
Oct 26, 2022In this paper, we propose a deep learning based multi-speaker direction of arrival (DOA) estimation with audio and visual signals by using permutation-free loss function. We first collect a data set for multi-modal sound source localization (SSL) where both audio and visual signals are recorded in real-life home TV scenarios. Then we propose a novel spatial annotation method to produce the ground truth of DOA for each speaker with the video data by transformation between camera coordinate and pixel coordinate according to the pin-hole camera model. With spatial location information served as another input along with acoustic feature, multi-speaker DOA estimation could be solved as a classification task of active speaker detection. Label permutation problem in multi-speaker related tasks will be addressed since the locations of each speaker are used as input. Experiments conducted on both simulated data and real data show that the proposed audio-visual DOA estimation model outperforms audio-only DOA estimation model by a large margin.