 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGastric-X: A Multimodal Multi-Phase Benchmark Dataset for Advancing Vision-Language Models in Gastric Cancer Analysis
Mar 19, 2026Recent vision-language models (VLMs) have shown strong generalization and multimodal reasoning abilities in natural domains. However, their application to medical diagnosis remains limited by the lack of comprehensive and structured datasets that capture real clinical workflows. To advance the development of VLMs for clinical applications, particularly in gastric cancer, we introduce Gastric-X, a large-scale multimodal benchmark for gastric cancer analysis providing 1.7K cases. Each case in Gastric-X includes paired resting and dynamic CT scans, endoscopic image, a set of structured biochemical indicators, expert-authored diagnostic notes, and bounding box annotations of tumor regions, reflecting realistic clinical conditions. We systematically examine the capability of recent VLMs on five core tasks: Visual Question Answering (VQA), report generation, cross-modal retrieval, disease classification, and lesion localization. These tasks simulate critical stages of clinical workflow, from visual understanding and reasoning to multimodal decision support. Through this evaluation, we aim not only to assess model performance but also to probe the nature of VLM understanding: Can current VLMs meaningfully correlate biochemical signals with spatial tumor features and textual reports? We envision Gastric-X as a step toward aligning machine intelligence with the cognitive and evidential reasoning processes of physicians, and as a resource to inspire the development of next-generation medical VLMs.
Dynamic Mix Precision Routing for Efficient Multi-step LLM Interaction
Feb 02, 2026Large language models (LLM) achieve strong performance in long-horizon decision-making tasks through multi-step interaction and reasoning at test time. While practitioners commonly believe a higher task success rate necessitates the use of a larger and stronger LLM model, multi-step interaction with a large LLM incurs prohibitive inference cost. To address this problem, we explore the use of low-precision quantized LLM in the long-horizon decision-making process. Based on the observation of diverse sensitivities among interaction steps, we propose a dynamic mix-precision routing framework that adaptively selects between high-precision and low-precision LLMs at each decision step. The router is trained via a two-stage pipeline, consisting of KL-divergence-based supervised learning that identifies precision-sensitive steps, followed by Group-Relative Policy Optimization (GRPO) to further improve task success rates. Experiments on ALFWorld demonstrate that our approach achieves a great improvement on accuracy-cost trade-off over single-precision baselines and heuristic routing methods.
AIConfigurator: Lightning-Fast Configuration Optimization for Multi-Framework LLM Serving
Jan 09, 2026Optimizing Large Language Model (LLM) inference in production systems is increasingly difficult due to dynamic workloads, stringent latency/throughput targets, and a rapidly expanding configuration space. This complexity spans not only distributed parallelism strategies (tensor/pipeline/expert) but also intricate framework-specific runtime parameters such as those concerning the enablement of CUDA graphs, available KV-cache memory fractions, and maximum token capacity, which drastically impact performance. The diversity of modern inference frameworks (e.g., TRT-LLM, vLLM, SGLang), each employing distinct kernels and execution policies, makes manual tuning both framework-specific and computationally prohibitive. We present AIConfigurator, a unified performance-modeling system that enables rapid, framework-agnostic inference configuration search without requiring GPU-based profiling. AIConfigurator combines (1) a methodology that decomposes inference into analytically modelable primitives - GEMM, attention, communication, and memory operations while capturing framework-specific scheduling dynamics; (2) a calibrated kernel-level performance database for these primitives across a wide range of hardware platforms and popular open-weights models (GPT-OSS, Qwen, DeepSeek, LLama, Mistral); and (3) an abstraction layer that automatically resolves optimal launch parameters for the target backend, seamlessly integrating into production-grade orchestration systems. Evaluation on production LLM serving workloads demonstrates that AIConfigurator identifies superior serving configurations that improve performance by up to 40% for dense models (e.g., Qwen3-32B) and 50% for MoE architectures (e.g., DeepSeek-V3), while completing searches within 30 seconds on average. Enabling the rapid exploration of vast design spaces - from cluster topology down to engine specific flags.
Inverse Design of Metamaterials with Manufacturing-Guiding Spectrum-to-Structure Conditional Diffusion Model
Jun 08, 2025Metamaterials are artificially engineered structures that manipulate electromagnetic waves, having optical properties absent in natural materials. Recently, machine learning for the inverse design of metamaterials has drawn attention. However, the highly nonlinear relationship between the metamaterial structures and optical behaviour, coupled with fabrication difficulties, poses challenges for using machine learning to design and manufacture complex metamaterials. Herein, we propose a general framework that implements customised spectrum-to-shape and size parameters to address one-to-many metamaterial inverse design problems using conditional diffusion models. Our method exhibits superior spectral prediction accuracy, generates a diverse range of patterns compared to other typical generative models, and offers valuable prior knowledge for manufacturing through the subsequent analysis of the diverse generated results, thereby facilitating the experimental fabrication of metamaterial designs. We demonstrate the efficacy of the proposed method by successfully designing and fabricating a free-form metamaterial with a tailored selective emission spectrum for thermal camouflage applications.
Doracamom: Joint 3D Detection and Occupancy Prediction with Multi-view 4D Radars and Cameras for Omnidirectional Perception
Jan 26, 2025



3D object detection and occupancy prediction are critical tasks in autonomous driving, attracting significant attention. Despite the potential of recent vision-based methods, they encounter challenges under adverse conditions. Thus, integrating cameras with next-generation 4D imaging radar to achieve unified multi-task perception is highly significant, though research in this domain remains limited. In this paper, we propose Doracamom, the first framework that fuses multi-view cameras and 4D radar for joint 3D object detection and semantic occupancy prediction, enabling comprehensive environmental perception. Specifically, we introduce a novel Coarse Voxel Queries Generator that integrates geometric priors from 4D radar with semantic features from images to initialize voxel queries, establishing a robust foundation for subsequent Transformer-based refinement. To leverage temporal information, we design a Dual-Branch Temporal Encoder that processes multi-modal temporal features in parallel across BEV and voxel spaces, enabling comprehensive spatio-temporal representation learning. Furthermore, we propose a Cross-Modal BEV-Voxel Fusion module that adaptively fuses complementary features through attention mechanisms while employing auxiliary tasks to enhance feature quality. Extensive experiments on the OmniHD-Scenes, View-of-Delft (VoD), and TJ4DRadSet datasets demonstrate that Doracamom achieves state-of-the-art performance in both tasks, establishing new benchmarks for multi-modal 3D perception. Code and models will be publicly available.
Bridge-Coder: Unlocking LLMs' Potential to Overcome Language Gaps in Low-Resource Code
Oct 24, 2024
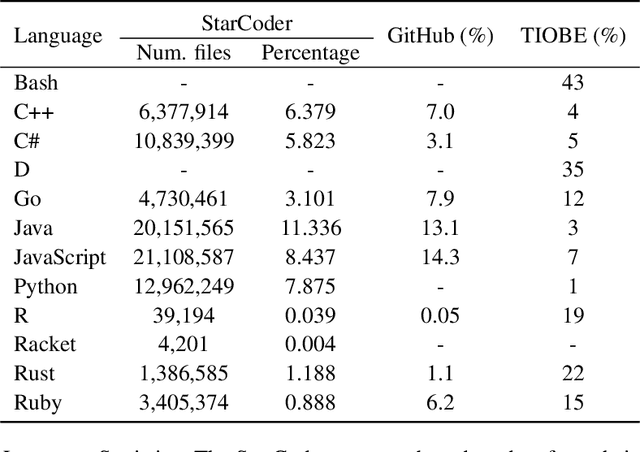

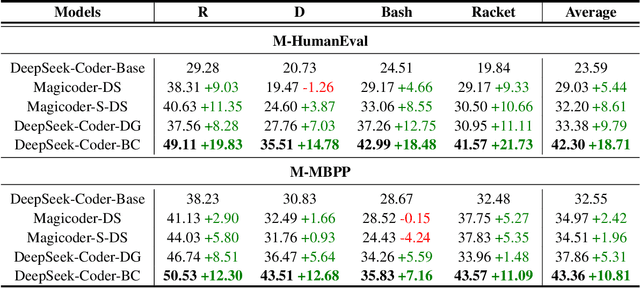
Large Language Models (LLMs) demonstrate strong proficiency in generating code for high-resource programming languages (HRPLs) like Python but struggle significantly with low-resource programming languages (LRPLs) such as Racket or D. This performance gap deepens the digital divide, preventing developers using LRPLs from benefiting equally from LLM advancements and reinforcing disparities in innovation within underrepresented programming communities. While generating additional training data for LRPLs is promising, it faces two key challenges: manual annotation is labor-intensive and costly, and LLM-generated LRPL code is often of subpar quality. The underlying cause of this issue is the gap between natural language to programming language gap (NL-PL Gap), which is especially pronounced in LRPLs due to limited aligned data. In this work, we introduce a novel approach called Bridge-Coder, which leverages LLMs' intrinsic capabilities to enhance the performance on LRPLs. Our method consists of two key stages. Bridge Generation, where we create high-quality dataset by utilizing LLMs' general knowledge understanding, proficiency in HRPLs, and in-context learning abilities. Then, we apply the Bridged Alignment, which progressively improves the alignment between NL instructions and LRPLs. Experimental results across multiple LRPLs show that Bridge-Coder significantly enhances model performance, demonstrating the effectiveness and generalization of our approach. Furthermore, we offer a detailed analysis of the key components of our method, providing valuable insights for future work aimed at addressing the challenges associated with LRPLs.