 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Design of Metamaterials with Manufacturing-Guiding Spectrum-to-Structure Conditional Diffusion Model
Jun 08, 2025Metamaterials are artificially engineered structures that manipulate electromagnetic waves, having optical properties absent in natural materials. Recently, machine learning for the inverse design of metamaterials has drawn attention. However, the highly nonlinear relationship between the metamaterial structures and optical behaviour, coupled with fabrication difficulties, poses challenges for using machine learning to design and manufacture complex metamaterials. Herein, we propose a general framework that implements customised spectrum-to-shape and size parameters to address one-to-many metamaterial inverse design problems using conditional diffusion models. Our method exhibits superior spectral prediction accuracy, generates a diverse range of patterns compared to other typical generative models, and offers valuable prior knowledge for manufacturing through the subsequent analysis of the diverse generated results, thereby facilitating the experimental fabrication of metamaterial designs. We demonstrate the efficacy of the proposed method by successfully designing and fabricating a free-form metamaterial with a tailored selective emission spectrum for thermal camouflage applications.
CRYSIM: Prediction of Symmetric Structures of Large Crystals with GPU-based Ising Machines
Apr 09, 2025Solving black-box optimization problems with Ising machines is increasingly common in materials science. However, their application to crystal structure prediction (CSP) is still ineffective due to symmetry agnostic encoding of atomic coordinates. We introduce CRYSIM, an algorithm that encodes the space group, the Wyckoff positions combination, and coordinates of independent atomic sites as separate variables. This encoding reduces the search space substantially by exploiting the symmetry in space groups. When CRYSIM is interfaced to Fixstars Amplify, a GPU-based Ising machine, its prediction performance was competitive with CALYPSO and Bayesian optimization for crystals containing more than 150 atoms in a unit cell. Although it is not realistic to interface CRYSIM to current small-scale quantum devices, it has the potential to become the standard CSP algorithm in the coming quantum age.
Preference-Optimized Pareto Set Learning for Blackbox Optimization
Aug 19, 2024



Multi-Objective Optimization (MOO) is an important problem in real-world applications. However, for a non-trivial problem, no single solution exists that can optimize all the objectives simultaneously. In a typical MOO problem, the goal is to find a set of optimum solutions (Pareto set) that trades off the preferences among objectives. Scalarization in MOO is a well-established method for finding a finite set approximation of the whole Pareto set (PS). However, in real-world experimental design scenarios, it's beneficial to obtain the whole PS for flexible exploration of the design space. Recently Pareto set learning (PSL) has been introduced to approximate the whole PS. PSL involves creating a manifold representing the Pareto front of a multi-objective optimization problem. A naive approach includes finding discrete points on the Pareto front through randomly generated preference vectors and connecting them by regression. However, this approach is computationally expensive and leads to a poor PS approximation. We propose to optimize the preference points to be distributed evenly on the Pareto front. Our formulation leads to a bilevel optimization problem that can be solved by e.g. differentiable cross-entropy methods. We demonstrated the efficacy of our method for complex and difficult black-box MOO problems using both synthetic and real-world benchmark data.
Molecule Graph Networks with Many-body Equivariant Interactions
Jun 19, 2024Message passing neural networks have demonstrated significant efficacy in predicting molecular interactions. Introducing equivariant vectorial representations augments expressivity by capturing geometric data symmetries, thereby improving model accuracy. However, two-body bond vectors in opposition may cancel each other out during message passing, leading to the loss of directional information on their shared node. In this study, we develop Equivariant N-body Interaction Networks (ENINet) that explicitly integrates equivariant many-body interactions to preserve directional information in the message passing scheme. Experiments indicate that integrating many-body equivariant representations enhances prediction accuracy across diverse scalar and tensorial quantum chemical properties. Ablation studies show an average performance improvement of 7.9% across 11 out of 12 properties in QM9, 27.9% in forces in MD17, and 11.3% in polarizabilities (CCSD) in QM7b.
Feature Importance Measurement based on Decision Tree Sampling
Jul 25, 2023Random forest is effective for prediction tasks but the randomness of tree generation hinders interpretability in feature importance analysis. To address this, we proposed DT-Sampler, a SAT-based method for measuring feature importance in tree-based model. Our method has fewer parameters than random forest and provides higher interpretability and stability for the analysis in real-world problems. An implementation of DT-Sampler is available at https://github.com/tsudalab/DT-sampler.
A Confidence Machine for Sparse High-Order Interaction Model
May 28, 2022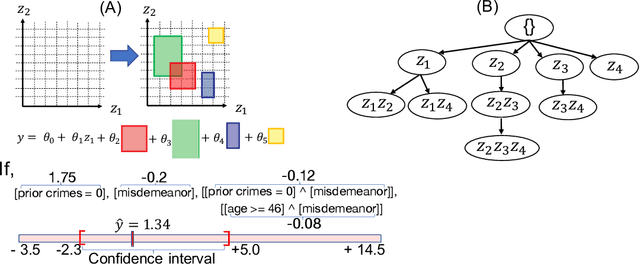


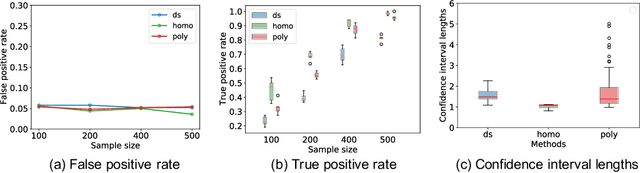
In predictive modeling for high-stake decision-making, predictors must be not only accurate but also reliable. Conformal prediction (CP) is a promising approach for obtaining the confidence of prediction results with fewer theoretical assumptions. To obtain the confidence set by so-called full-CP, we need to refit the predictor for all possible values of prediction results, which is only possible for simple predictors. For complex predictors such as random forests (RFs) or neural networks (NNs), split-CP is often employed where the data is split into two parts: one part for fitting and another to compute the confidence set. Unfortunately, because of the reduced sample size, split-CP is inferior to full-CP both in fitting as well as confidence set computation. In this paper, we develop a full-CP of sparse high-order interaction model (SHIM), which is sufficiently flexible as it can take into account high-order interactions among variables. We resolve the computational challenge for full-CP of SHIM by introducing a novel approach called homotopy mining. Through numerical experiments, we demonstrate that SHIM is as accurate as complex predictors such as RF and NN and enjoys the superior statistical power of full-CP.
Fast and More Powerful Selective Inference for Sparse High-order Interaction Model
Jun 09, 2021
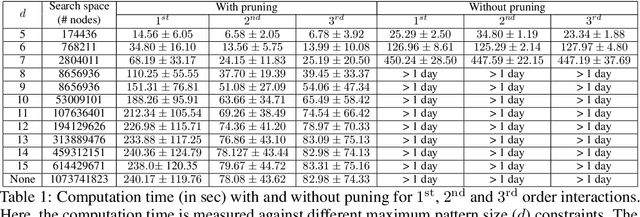

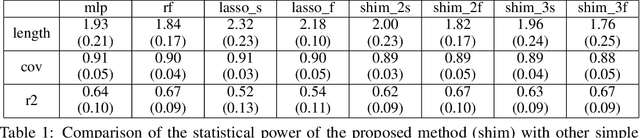
Automated high-stake decision-making such as medical diagnosis requires models with high interpretability and reliability. As one of the interpretable and reliable models with good prediction ability, we consider Sparse High-order Interaction Model (SHIM) in this study. However, finding statistically significant high-order interactions is challenging due to the intrinsic high dimensionality of the combinatorial effects. Another problem in data-driven modeling is the effect of "cherry-picking" a.k.a. selection bias. Our main contribution is to extend the recently developed parametric programming approach for selective inference to high-order interaction models. Exhaustive search over the cherry tree (all possible interactions) can be daunting and impractical even for a small-sized problem. We introduced an efficient pruning strategy and demonstrated the computational efficiency and statistical power of the proposed method using both synthetic and real data.