 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark of Segmentation Techniques for Pelvic Fracture in CT and X-ray: Summary of the PENGWIN 2024 Challenge
Apr 03, 2025The segmentation of pelvic fracture fragments in CT and X-ray images is crucial for trauma diagnosis, surgical planning, and intraoperative guidance. However, accurately and efficiently delineating the bone fragments remains a significant challenge due to complex anatomy and imaging limitations. The PENGWIN challenge, organized as a MICCAI 2024 satellite event, aimed to advance automated fracture segmentation by benchmarking state-of-the-art algorithms on these complex tasks. A diverse dataset of 150 CT scans was collected from multiple clinical centers, and a large set of simulated X-ray images was generated using the DeepDRR method. Final submissions from 16 teams worldwide were evaluated under a rigorous multi-metric testing scheme. The top-performing CT algorithm achieved an average fragment-wise intersection over union (IoU) of 0.930, demonstrating satisfactory accuracy. However, in the X-ray task, the best algorithm attained an IoU of 0.774, highlighting the greater challenges posed by overlapping anatomical structures. Beyond the quantitative evaluation, the challenge revealed methodological diversity in algorithm design. Variations in instance representation, such as primary-secondary classification versus boundary-core separation, led to differing segmentation strategies. Despite promising results, the challenge also exposed inherent uncertainties in fragment definition, particularly in cases of incomplete fractures. These findings suggest that interactive segmentation approaches, integrating human decision-making with task-relevant information, may be essential for improving model reliability and clinical applicability.
Universal Segmentation of 33 Anatomies
Mar 04, 2022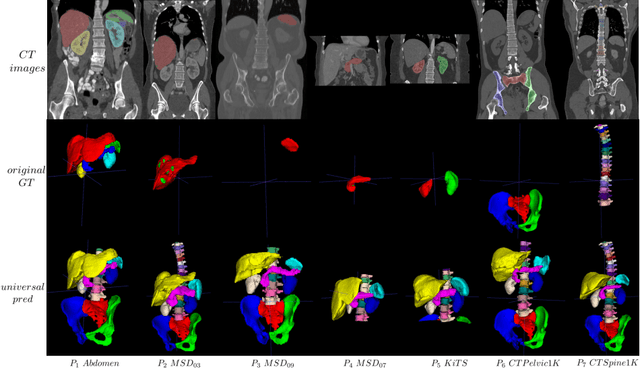
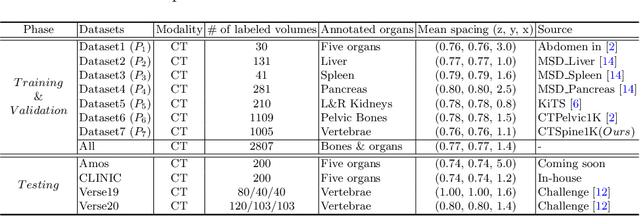
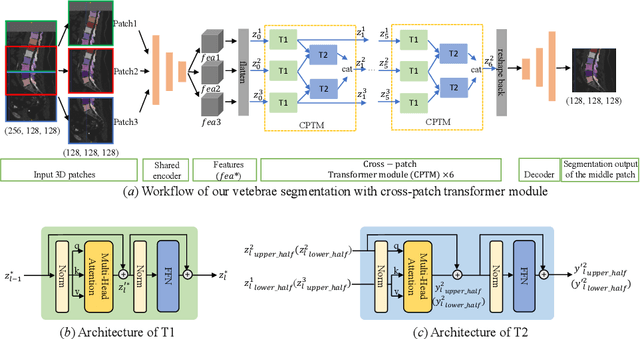
In the paper, we present an approach for learning a single model that universally segments 33 anatomical structures, including vertebrae, pelvic bones, and abdominal organs. Our model building has to address the following challenges. Firstly, while it is ideal to learn such a model from a large-scale, fully-annotated dataset, it is practically hard to curate such a dataset. Thus, we resort to learn from a union of multiple datasets, with each dataset containing the images that are partially labeled. Secondly, along the line of partial labelling, we contribute an open-source, large-scale vertebra segmentation dataset for the benefit of spine analysis community, CTSpine1K, boasting over 1,000 3D volumes and over 11K annotated vertebrae. Thirdly, in a 3D medical image segmentation task, due to the limitation of GPU memory, we always train a model using cropped patches as inputs instead a whole 3D volume, which limits the amount of contextual information to be learned. To this, we propose a cross-patch transformer module to fuse more information in adjacent patches, which enlarges the aggregated receptive field for improved segmentation performance. This is especially important for segmenting, say, the elongated spine. Based on 7 partially labeled datasets that collectively contain about 2,800 3D volumes, we successfully learn such a universal model. Finally, we evaluate the universal model on multiple open-source datasets, proving that our model has a good generalization performance and can potentially serve as a solid foundation for downstream tasks.
CTSpine1K: A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
Jun 10, 2021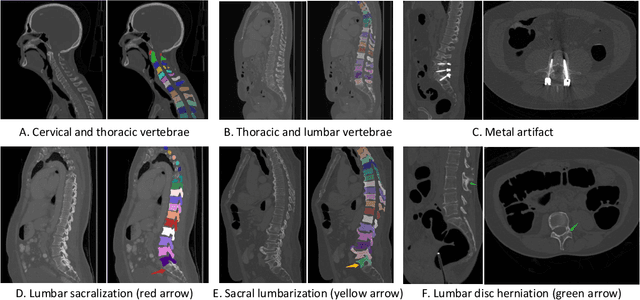

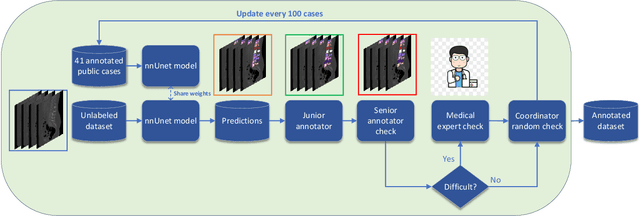
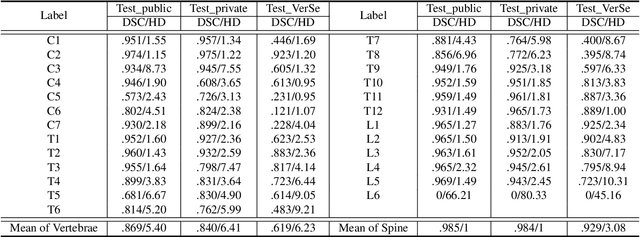
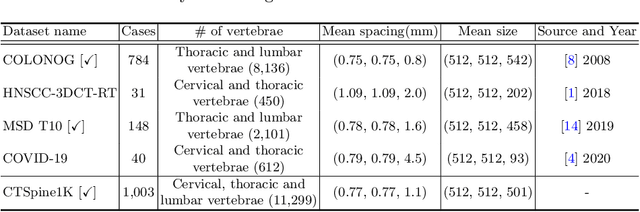
Spine-related diseases have high morbidity and cause a huge burden of social cost. Spine imaging is an essential tool for noninvasively visualizing and assessing spinal pathology. Segmenting vertebrae in computed tomography (CT) images is the basis of quantitative medical image analysis for clinical diagnosis and surgery planning of spine diseases. Current publicly available annotated datasets on spinal vertebrae are small in size. Due to the lack of a large-scale annotated spine image dataset, the mainstream deep learning-based segmentation methods, which are data-driven, are heavily restricted. In this paper, we introduce a large-scale spine CT dataset, called CTSpine1K, curated from multiple sources for vertebra segmentation, which contains 1,005 CT volumes with over 11,100 labeled vertebrae belonging to different spinal conditions. Based on this dataset, we conduct several spinal vertebrae segmentation experiments to set the first benchmark. We believe that this large-scale dataset will facilitate further research in many spine-related image analysis tasks, including but not limited to vertebrae segmentation, labeling, 3D spine reconstruction from biplanar radiographs, image super-resolution, and enhancement.
Deep Learning to Segment Pelvic Bones: Large-scale CT Datasets and Baseline Models
Dec 16, 2020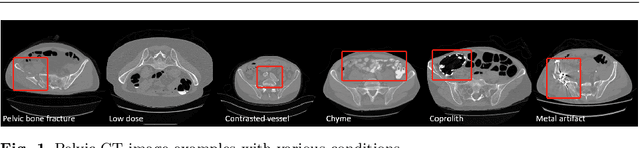
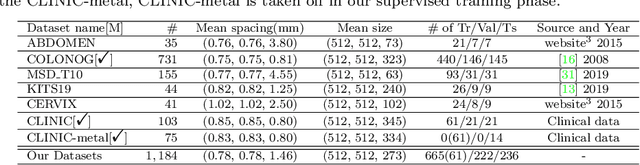
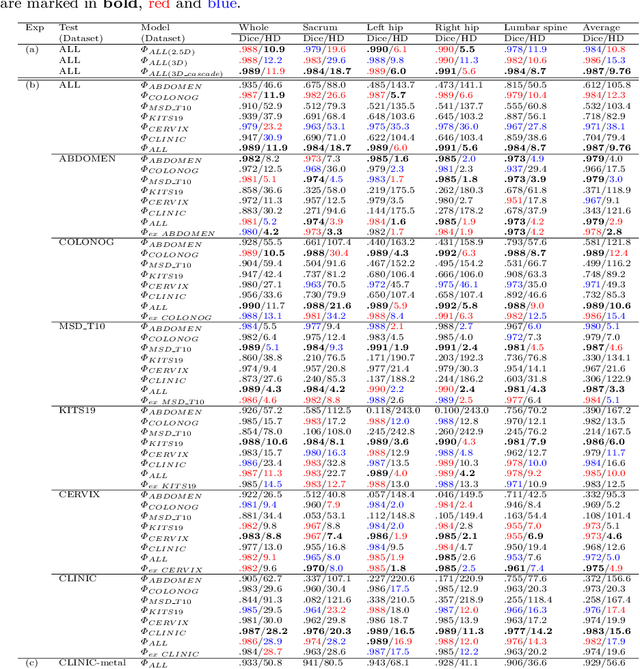
Purpose: Pelvic bone segmentation in CT has always been an essential step in clinical diagnosis and surgery planning of pelvic bone diseases. Existing methods for pelvic bone segmentation are either hand-crafted or semi-automatic and achieve limited accuracy when dealing with image appearance variations due to the multi-site domain shift, the presence of contrasted vessels, coprolith and chyme, bone fractures, low dose, metal artifacts, etc. Due to the lack of a large-scale pelvic CT dataset with annotations, deep learning methods are not fully explored. Methods: In this paper, we aim to bridge the data gap by curating a large pelvic CT dataset pooled from multiple sources and different manufacturers, including 1, 184 CT volumes and over 320, 000 slices with different resolutions and a variety of the above-mentioned appearance variations. Then we propose for the first time, to the best of our knowledge, to learn a deep multi-class network for segmenting lumbar spine, sacrum, left hip, and right hip, from multiple-domain images simultaneously to obtain more effective and robust feature representations. Finally, we introduce a post-processing tool based on the signed distance function (SDF) to eliminate false predictions while retaining correctly predicted bone fragments. Results: Extensive experiments on our dataset demonstrate the effectiveness of our automatic method, achieving an average Dice of 0.987 for a metal-free volume. SDF post-processor yields a decrease of 10.5% in hausdorff distance by maintaining important bone fragments in post-processing phase. Conclusion: We believe this large-scale dataset will promote the development of the whole community and plan to open source the images, annotations, codes, and trained baseline models at this URL1.