 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoMBS: Mixed-order minibatch sampling enhances model training from diverse-quality images
May 24, 2025Natural images exhibit label diversity (clean vs. noisy) in noisy-labeled image classification and prevalence diversity (abundant vs. sparse) in long-tailed image classification. Similarly, medical images in universal lesion detection (ULD) exhibit substantial variations in image quality, encompassing attributes such as clarity and label correctness. How to effectively leverage training images with diverse qualities becomes a problem in learning deep models. Conventional training mechanisms, such as self-paced curriculum learning (SCL) and online hard example mining (OHEM), relieve this problem by reweighting images with high loss values. Despite their success, these methods still confront two challenges: (i) the loss-based measure of sample hardness is imprecise, preventing optimum handling of different cases, and (ii) there exists under-utilization in SCL or over-utilization OHEM with the identified hard samples. To address these issues, this paper revisits the minibatch sampling (MBS), a technique widely used in deep network training but largely unexplored concerning the handling of diverse-quality training samples. We discover that the samples within a minibatch influence each other during training; thus, we propose a novel Mixed-order Minibatch Sampling (MoMBS) method to optimize the use of training samples with diverse qualities. MoMBS introduces a measure that takes both loss and uncertainty into account to surpass a sole reliance on loss and allows for a more refined categorization of high-loss samples by distinguishing them as either poorly labeled and under represented or well represented and overfitted. We prioritize under represented samples as the main gradient contributors in a minibatch and keep them from the negative influences of poorly labeled or overfitted samples with a mixed-order minibatch sampling design.
EfficientMT: Efficient Temporal Adaptation for Motion Transfer in Text-to-Video Diffusion Models
Mar 26, 2025



The progress on generative models has led to significant advances on text-to-video (T2V) generation, yet the motion controllability of generated videos remains limited. Existing motion transfer methods explored the motion representations of reference videos to guide generation. Nevertheless, these methods typically rely on sample-specific optimization strategy, resulting in high computational burdens. In this paper, we propose EfficientMT, a novel and efficient end-to-end framework for video motion transfer. By leveraging a small set of synthetic paired motion transfer samples, EfficientMT effectively adapts a pretrained T2V model into a general motion transfer framework that can accurately capture and reproduce diverse motion patterns. Specifically, we repurpose the backbone of the T2V model to extract temporal information from reference videos, and further propose a scaler module to distill motion-related information. Subsequently, we introduce a temporal integration mechanism that seamlessly incorporates reference motion features into the video generation process. After training on our self-collected synthetic paired samples, EfficientMT enables general video motion transfer without requiring test-time optimization. Extensive experiments demonstrate that our EfficientMT outperforms existing methods in efficiency while maintaining flexible motion controllability. Our code will be available https://github.com/PrototypeNx/EfficientMT.
Dynamically evolving segment anything model with continuous learning for medical image segmentation
Mar 08, 2025



Medical image segmentation is essential for clinical diagnosis, surgical planning, and treatment monitoring. Traditional approaches typically strive to tackle all medical image segmentation scenarios via one-time learning. However, in practical applications, the diversity of scenarios and tasks in medical image segmentation continues to expand, necessitating models that can dynamically evolve to meet the demands of various segmentation tasks. Here, we introduce EvoSAM, a dynamically evolving medical image segmentation model that continuously accumulates new knowledge from an ever-expanding array of scenarios and tasks, enhancing its segmentation capabilities. Extensive evaluations on surgical image blood vessel segmentation and multi-site prostate MRI segmentation demonstrate that EvoSAM not only improves segmentation accuracy but also mitigates catastrophic forgetting. Further experiments conducted by surgical clinicians on blood vessel segmentation confirm that EvoSAM enhances segmentation efficiency based on user prompts, highlighting its potential as a promising tool for clinical applications.
Face-MLLM: A Large Face Perception Model
Oct 28, 2024



Although multimodal large language models (MLLMs) have achieved promising results on a wide range of vision-language tasks, their ability to perceive and understand human faces is rarely explored. In this work, we comprehensively evaluate existing MLLMs on face perception tasks. The quantitative results reveal that existing MLLMs struggle to handle these tasks. The primary reason is the lack of image-text datasets that contain fine-grained descriptions of human faces. To tackle this problem, we design a practical pipeline for constructing datasets, upon which we further build a novel multimodal large face perception model, namely Face-MLLM. Specifically, we re-annotate LAION-Face dataset with more detailed face captions and facial attribute labels. Besides, we re-formulate traditional face datasets using the question-answer style, which is fit for MLLMs. Together with these enriched datasets, we develop a novel three-stage MLLM training method. In the first two stages, our model learns visual-text alignment and basic visual question answering capability, respectively. In the third stage, our model learns to handle multiple specialized face perception tasks. Experimental results show that our model surpasses previous MLLMs on five famous face perception tasks. Besides, on our newly introduced zero-shot facial attribute analysis task, our Face-MLLM also presents superior performance.
Task-adaptive Q-Face
May 15, 2024



Although face analysis has achieved remarkable improvements in the past few years, designing a multi-task face analysis model is still challenging. Most face analysis tasks are studied as separate problems and do not benefit from the synergy among related tasks. In this work, we propose a novel task-adaptive multi-task face analysis method named as Q-Face, which simultaneously performs multiple face analysis tasks with a unified model. We fuse the features from multiple layers of a large-scale pre-trained model so that the whole model can use both local and global facial information to support multiple tasks. Furthermore, we design a task-adaptive module that performs cross-attention between a set of query vectors and the fused multi-stage features and finally adaptively extracts desired features for each face analysis task. Extensive experiments show that our method can perform multiple tasks simultaneously and achieves state-of-the-art performance on face expression recognition, action unit detection, face attribute analysis, age estimation, and face pose estimation. Compared to conventional methods, our method opens up new possibilities for multi-task face analysis and shows the potential for both accuracy and efficiency.
Decoupled Textual Embeddings for Customized Image Generation
Dec 19, 2023
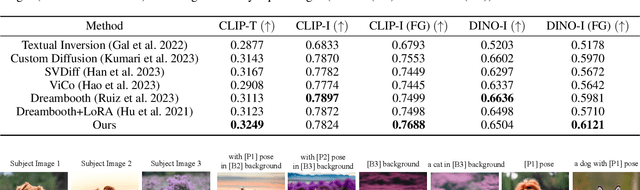
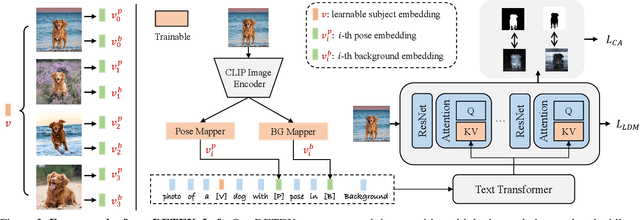
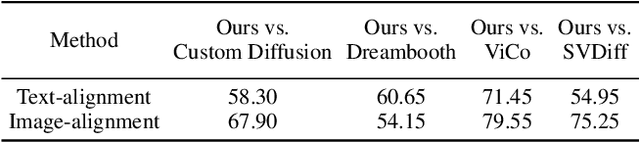
Customized text-to-image generation, which aims to learn user-specified concepts with a few images, has drawn significant attention recently. However, existing methods usually suffer from overfitting issues and entangle the subject-unrelated information (e.g., background and pose) with the learned concept, limiting the potential to compose concept into new scenes. To address these issues, we propose the DETEX, a novel approach that learns the disentangled concept embedding for flexible customized text-to-image generation. Unlike conventional methods that learn a single concept embedding from the given images, our DETEX represents each image using multiple word embeddings during training, i.e., a learnable image-shared subject embedding and several image-specific subject-unrelated embeddings. To decouple irrelevant attributes (i.e., background and pose) from the subject embedding, we further present several attribute mappers that encode each image as several image-specific subject-unrelated embeddings. To encourage these unrelated embeddings to capture the irrelevant information, we incorporate them with corresponding attribute words and propose a joint training strategy to facilitate the disentanglement. During inference, we only use the subject embedding for image generation, while selectively using image-specific embeddings to retain image-specified attributes. Extensive experiments demonstrate that the subject embedding obtained by our method can faithfully represent the target concept, while showing superior editability compared to the state-of-the-art methods. Our code will be made published available.
Mixed-order self-paced curriculum learning for universal lesion detection
Feb 09, 2023



Self-paced curriculum learning (SCL) has demonstrated its great potential in computer vision, natural language processing, etc. During training, it implements easy-to-hard sampling based on online estimation of data difficulty. Most SCL methods commonly adopt a loss-based strategy of estimating data difficulty and deweighting the `hard' samples in the early training stage. While achieving success in a variety of applications, SCL stills confront two challenges in a medical image analysis task, such as universal lesion detection, featuring insufficient and highly class-imbalanced data: (i) the loss-based difficulty measurer is inaccurate; ii) the hard samples are under-utilized from a deweighting mechanism. To overcome these challenges, in this paper we propose a novel mixed-order self-paced curriculum learning (Mo-SCL) method. We integrate both uncertainty and loss to better estimate difficulty online and mix both hard and easy samples in the same mini-batch to appropriately alleviate the problem of under-utilization of hard samples. We provide a theoretical investigation of our method in the context of stochastic gradient descent optimization and extensive experiments based on the DeepLesion benchmark dataset for universal lesion detection (ULD). When applied to two state-of-the-art ULD methods, the proposed mixed-order SCL method can provide a free boost to lesion detection accuracy without extra special network designs.
Affective Behaviour Analysis Using Pretrained Model with Facial Priori
Jul 24, 2022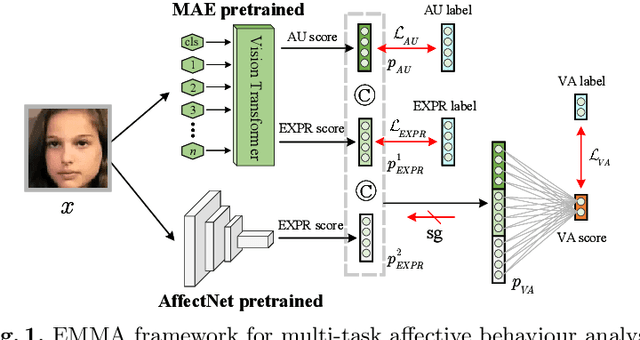
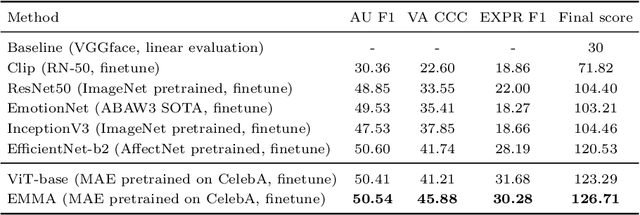
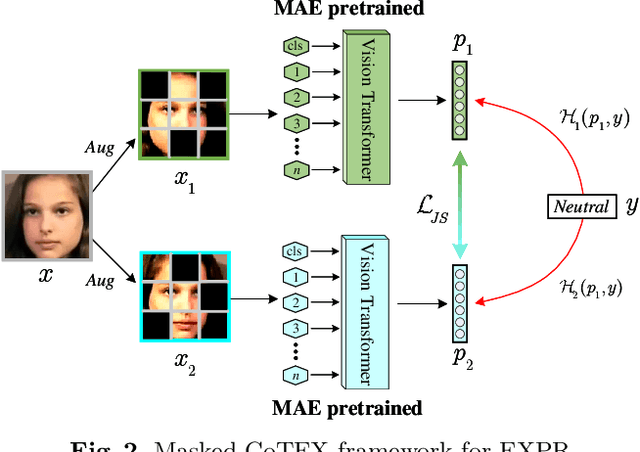

Affective behaviour analysis has aroused researchers' attention due to its broad applications. However, it is labor exhaustive to obtain accurate annotations for massive face images. Thus, we propose to utilize the prior facial information via Masked Auto-Encoder (MAE) pretrained on unlabeled face images. Furthermore, we combine MAE pretrained Vision Transformer (ViT) and AffectNet pretrained CNN to perform multi-task emotion recognition. We notice that expression and action unit (AU) scores are pure and intact features for valence-arousal (VA) regression. As a result, we utilize AffectNet pretrained CNN to extract expression scores concatenating with expression and AU scores from ViT to obtain the final VA features. Moreover, we also propose a co-training framework with two parallel MAE pretrained ViT for expression recognition tasks. In order to make the two views independent, we random mask most patches during the training process. Then, JS divergence is performed to make the predictions of the two views as consistent as possible. The results on ABAW4 show that our methods are effective.
MGRR-Net: Multi-level Graph Relational Reasoning Network for Facial Action Units Detection
Apr 08, 2022



The Facial Action Coding System (FACS) encodes the action units (AUs) in facial images, which has attracted extensive research attention due to its wide use in facial expression analysis. Many methods that perform well on automatic facial action unit (AU) detection primarily focus on modeling various types of AU relations between corresponding local muscle areas, or simply mining global attention-aware facial features, however, neglect the dynamic interactions among local-global features. We argue that encoding AU features just from one perspective may not capture the rich contextual information between regional and global face features, as well as the detailed variability across AUs, because of the diversity in expression and individual characteristics. In this paper, we propose a novel Multi-level Graph Relational Reasoning Network (termed MGRR-Net) for facial AU detection. Each layer of MGRR-Net performs a multi-level (i.e., region-level, pixel-wise and channel-wise level) feature learning. While the region-level feature learning from local face patches features via graph neural network can encode the correlation across different AUs, the pixel-wise and channel-wise feature learning via graph attention network can enhance the discrimination ability of AU features from global face features. The fused features from the three levels lead to improved AU discriminative ability. Extensive experiments on DISFA and BP4D AU datasets show that the proposed approach achieves superior performance than the state-of-the-art methods.
Automatic Facial Paralysis Estimation with Facial Action Units
Mar 30, 2022
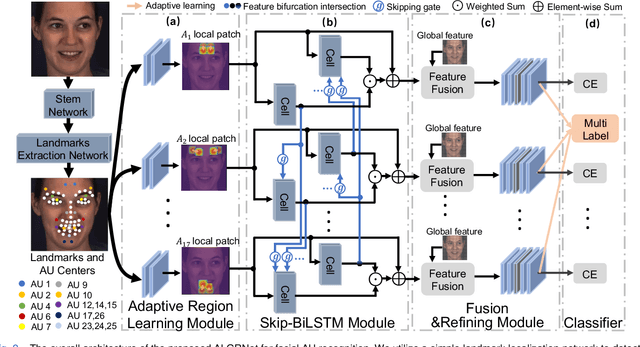
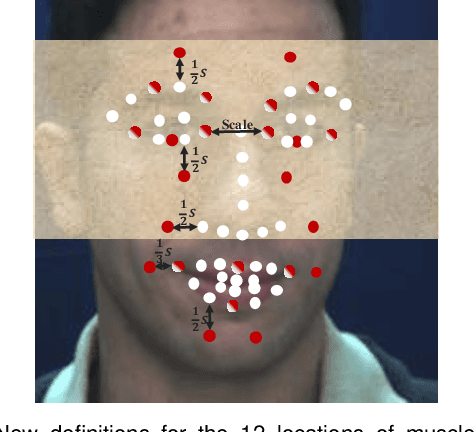
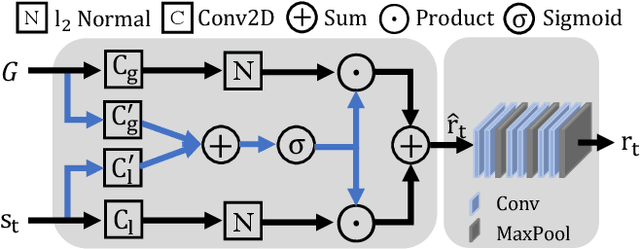
Facial palsy is unilateral facial nerve weakness or paralysis of rapid onset with unknown causes. Automatically estimating facial palsy severeness can be helpful for the diagnosis and treatment of people suffering from it across the world. In this work, we develop and experiment with a novel model for estimating facial palsy severity. For this, an effective Facial Action Units (AU) detection technique is incorporated into our model, where AUs refer to a unique set of facial muscle movements used to describe almost every anatomically possible facial expression. In this paper, we propose a novel Adaptive Local-Global Relational Network (ALGRNet) for facial AU detection and use it to classify facial paralysis severity. ALGRNet mainly consists of three main novel structures: (i) an adaptive region learning module that learns the adaptive muscle regions based on the detected landmarks; (ii) a skip-BiLSTM that models the latent relationships among local AUs; and (iii) a feature fusion&refining module that investigates the complementary between the local and global face. Quantitative results on two AU benchmarks, i.e., BP4D and DISFA, demonstrate our ALGRNet can achieve promising AU detection accuracy. We further demonstrate the effectiveness of its application to facial paralysis estimation by migrating ALGRNet to a facial paralysis dataset collected and annotated by medical professionals.